作为一个长期在一线体验和落地AI工具的产品经理,我最近把本地可部署的大模型又系统跑了一遍。
目标很明确:在24G显存的设备上,选择一款稳定、覆盖面广、能支持文本和图片的统一模型,用来支撑我的日常原型验证和智能体开发。
前面我分享了:手把手教你部署 OpenClaw + Ollama + GLM-4.7-Flash 的纯本地方案,实现无需服务器、无模型调用费用、离线可用的 AI 助手
Qwen3.5系列发布并开源之后,我觉得本地24G显存新选择多了一个:Qwen3.5-27B,也是不错的OpenClaw 搭配的本地方案,而且还多了视觉方案。
核心观点
- 在24G显存下,Qwen3.5-27B表现更均衡:官方测评显示它与Qwen3.5-35B-A3B整体性能接近,但参数规模更小,更适合本地部署。
- 相较GLM-4.7-Flash,Qwen3.5-27B在公开对比数据中更优,且是文本-视觉一体化模型,减少了文本模型与多模态模型切换的复杂度。
- 实际使用中需控制上下文长度(建议不超过32k),否则在24G显存环境下容易因显存不足崩溃。
为什么现在写Qwen3.5
近期出现了更贴近国内使用习惯的本地智能助理(例如 CoPaw 这类),它们偏好在本地使用可开源、可控的模型做多模态任务。

Qwen3.5系列开放后,本地部署路线变得更完整:我可以用Ollama拉起一个统一的文本-视觉模型,替代之前“文本模型 + VL模型”的组合方案,减少切换、路由和工程复杂度。
Qwen3.5时间线与型号
- 2026-02-16:Qwen3.5-397B-A17B(旗舰)发布。
- 2026-02-24:开源Qwen3.5-122B-A10B、Qwen3.5-35B-A3B、Qwen3.5-27B三款模型。
从官方测评图(原文提供)看,Qwen3.5-35B-A3B和Qwen3.5-27B整体差距不大,Qwen3.5-27B在部分指标占优,且模型更小,因此更适合24G显存的本地部署。
差异化与适配性:我怎么选
| 模型 | 模态能力 | 显存要求(24G) | 上下文长度建议 | 定位/适配 | 备注 |
|---|---|---|---|---|---|
| Qwen3.5-27B | 文本+视觉 | 可部署 | 建议 ≤32k | 本地多模态统一;智能体调用图片与文本混合任务 | 官方评测优于GLM-4.7-Flash(来源于原文对比);模型体积更小 |
| Qwen3.5-35B-A3B | 文本+视觉 | 可部署(更紧张) | 建议 ≤32k | 性能接近27B;24G下更容易触发显存瓶颈 | 和27B性能接近,但体积更大 |
| GLM-4.7-Flash | 文本为主 | 可部署 | 更长上下文支持 | 需要更长上下文时的备选 | 此前在本地24G显存为优选;上下文能力强 |
| Qwen3-30B-A3B-Thinking-2507(量化) | 文本 | 可部署 | 中等 | 思维链场景、文本推理 | 早期结论的24G优选,后被GLM-4.7-Flash替代 |
选择建议:
- 需要统一处理文本与图片:优先Qwen3.5-27B。
- 需要更长的上下文窗口:考虑GLM-4.7-Flash。
- 纯文本且强调推理链:可尝试Qwen3-30B-A3B-Thinking-2507(量化)。
说明:性能结论基于原文引用的官方数据与横向对比;不同评测基准、任务分布和量化方案会影响结果,落地前建议进行小样本验证。
本地部署步骤(Ollama)
安装Ollama:前往官网 https://ollama.com 下载并安装。
下载模型:终端执行
ollama run qwen3.5:2
下载过程中若速度明显变慢,可 Ctrl+C 终止后重试;Ollama支持断点续传,通常能恢复到正常速率。
启动与使用:在Ollama界面或终端直接对话。
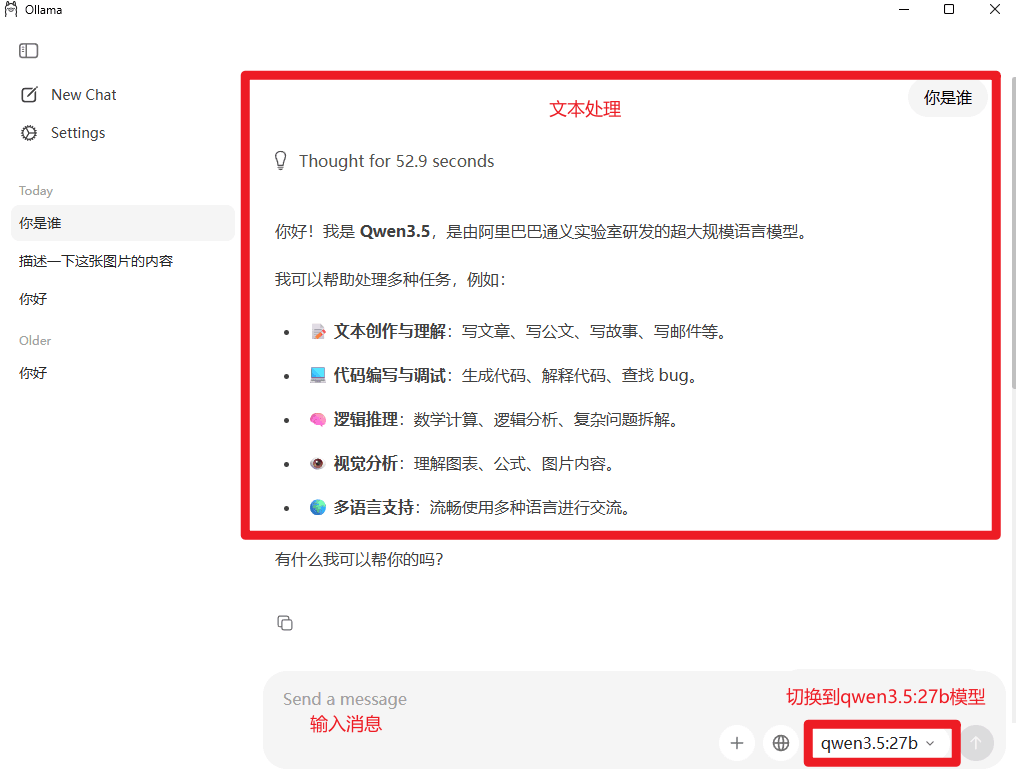
文本与图片混合任务可在同一模型内完成(图片理解)。

使用中的注意点
- 显存与上下文:Qwen3.5-27B在24G显存下建议将context length设置在32k内,避免因显存不足崩溃(35B-A3B同理)。
- 任务拆分:长文档或多图任务尽量分批处理(分chunk),减少显存压力,提高稳定性。
- 量化与并发:若需并发或长会话,考虑量化版本与降低并发数;监控GPU显存波动。
- 更大上下文需求:对长文检索或长会话,GLM-4.7-Flash依然是可选项。
我的实践体验
过去我在本地智能体里常用“两套模型”:文本模型负责理解、生成,VL模型负责图片解析,路由与切换较复杂。
换成Qwen3.5-27B后,工程链路更简单:一个模型即可完成截图+文本混合任务(例如在原型演示中,对界面截图进行结构化描述,再结合需求文档生成测试用例)。
体验中的问题也很直接:一次把上下文开到大于32k,几次触发显存不足导致中断。后来通过限制上下文、对长输入做chunk化、降低并发,稳定性明显提升。
生成速度上,27B的延迟可接受(与35B-A3B相近),但在图像解析时仍需给模型足够时间,不适合极端低延迟场景。
结尾总结
如果你和我一样,在24G显存的机器上做本地智能体原型迭代,Qwen3.5-27B是当前更稳妥的统一选择:性能与体积平衡、支持文本与视觉、减少工程复杂度。
上限更高的需求(更长上下文、更强并发)可以有GLM-4.7-Flash做补位。
我的原则是不追“绝对最强”,而是选择对目标任务和资源约束最合适的组合——在这点上,Qwen3.5-27B值得优先尝试。
相关链接:
官方博客:https://qwen.ai/blog?id=qwen3.5 GitHub:https://github.com/QwenLM/Qwen3.5 Hugging Face:https://huggingface.co/Qwen 在线体验:https://chat.qwen.ai/ API服务:https://modelstudio.alibabacloud.com/