6 月 2 日,法国 AI 公司 H Company 推出 Holo3.1 系列开源计算机控制大模型。这是继两个月前 Holo3 发布后,该团队针对生产环境反馈优化的版本,核心解决此前计算机控制 AI 代理(Computer-use Agent)普遍存在的云部署延迟高、成本高、数据隐私风险的问题。
Holo3.1 是什么?
Holo3.1 基于 Qwen 架构开发,专门针对 GUI 理解、屏幕操作、任务规划、跨应用导航等计算机控制场景做了微调。和通用大模型相比,在真实本地 GUI 任务中的表现更突出。同时原生支持函数调用协议,可无缝接入第三方 AI 代理框架,适配不同生产环境的部署需求。
整个系列覆盖 0.8B、4B、9B、35B 四种参数规格,提供 NVFP4、FP8、Q4 GGUF 三种量化版本,可完全离线运行在 MacBook、Windows PC、DGX Spark 等设备上,所有运算与数据均不离开用户本地环境。
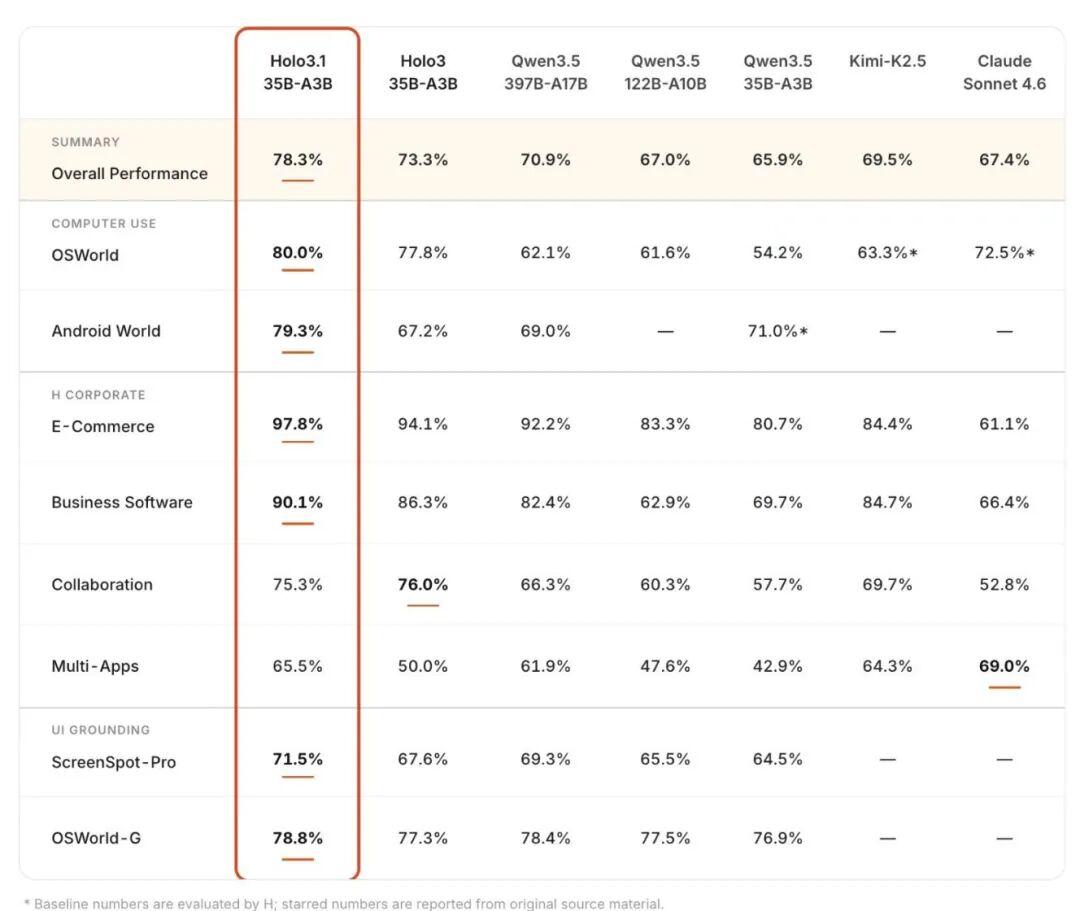
性能表现:35B 版全面超越主流模型
官方给出的基准测试数据显示,Holo3.1 35B 版本整体性能达 78.3%,OSWorld 基准 80.0%,AndroidWorld 基准 79.3%,全面超过 Qwen3.5-397B、Kimi-K2.5、Claude Sonnet 4.6 等主流模型。
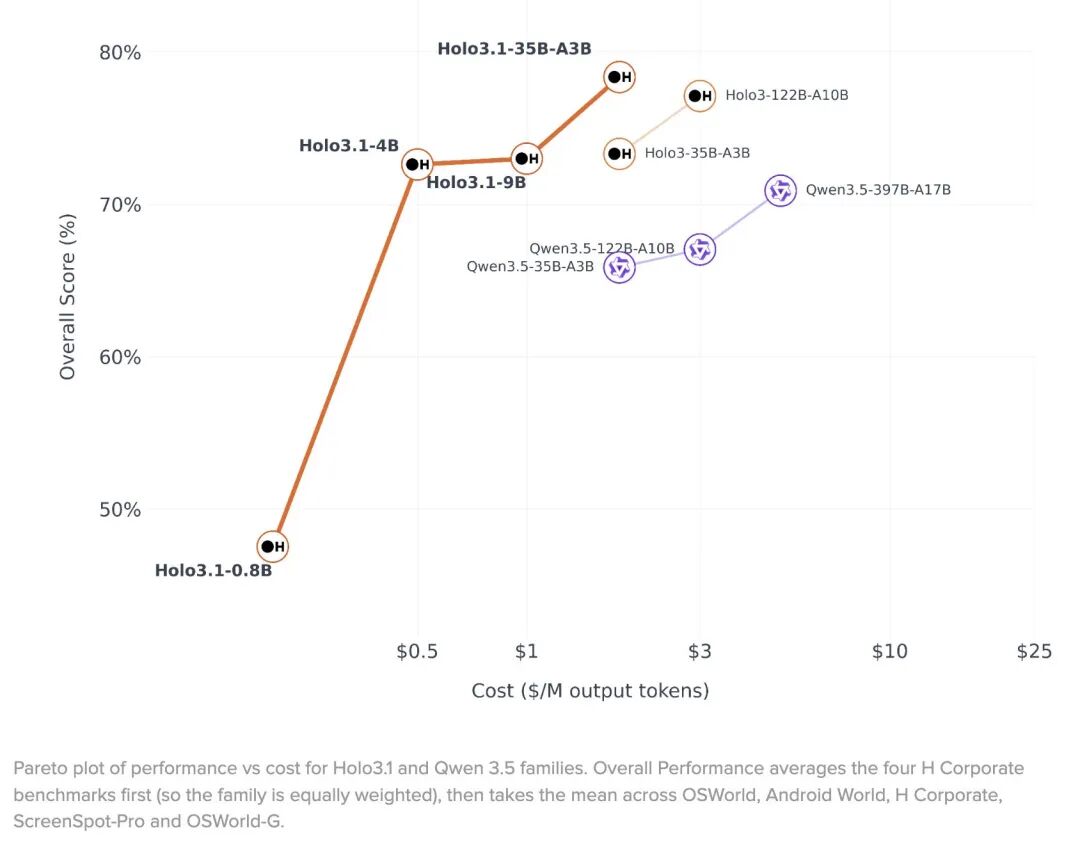
哪怕是 4B、9B 的小参数版本,AndroidWorld 基准成绩也达到 71%,足够覆盖多数简单自动化场景。
速度优化:NVFP4 量化提升显著
在 DGX Spark 设备上使用 Fast harness 调度,NVFP4 量化的 35B 版本每分钟可处理 18.1 个请求:
- 是 FP8 版本的 1.5 倍
- 是全精度 BF16 版本的 1.74 倍
- OSWorld 基准成绩仅比 BF16 版本低 2 个百分点,几乎无感知损失
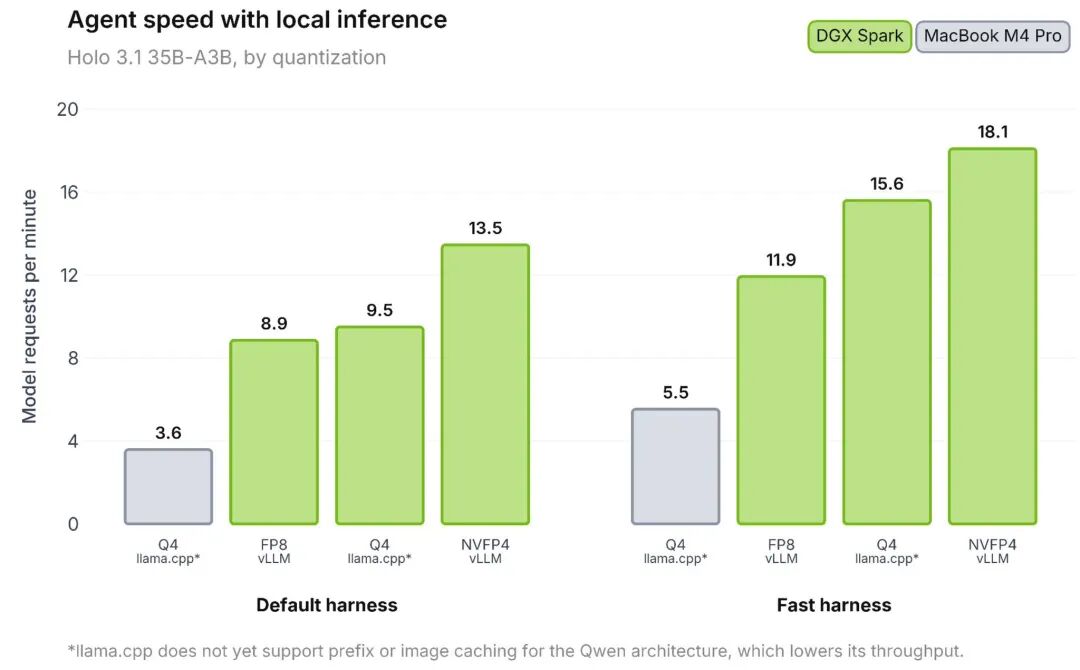
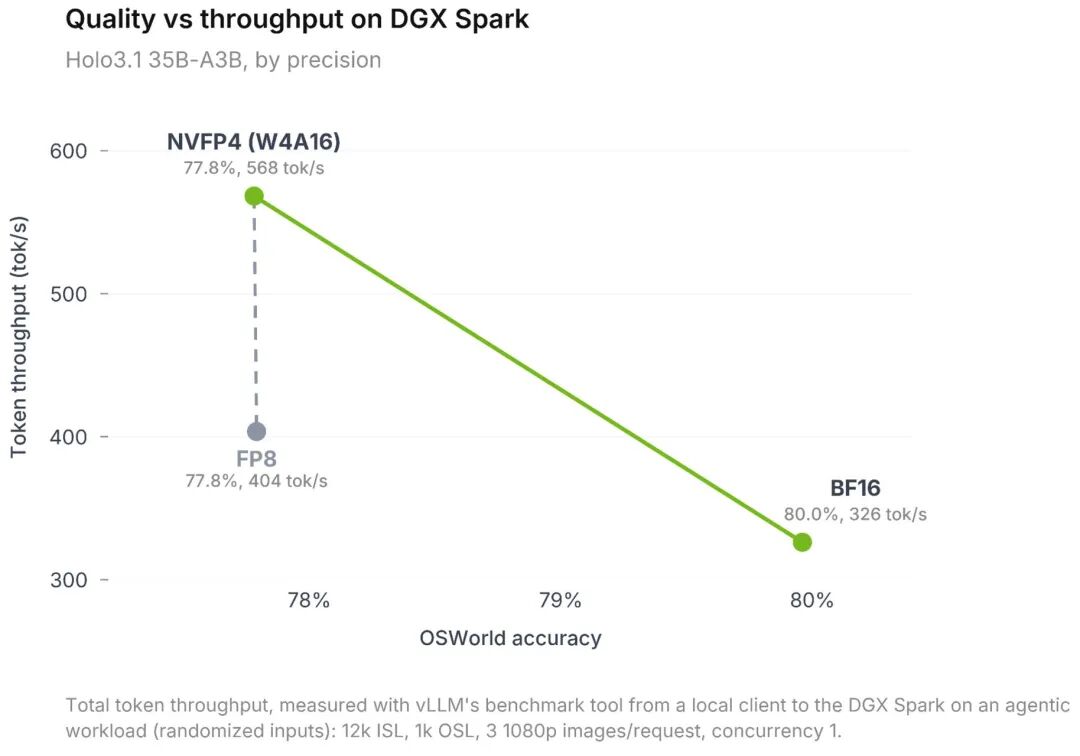
苏米注:NVFP4 量化的效果非常值得关注——1.74 倍的速度提升,精度损失仅 2 个百分点。这意味着在本地部署 Computer Use模型时,可以在性能和精度之间找到很好的平衡点。
本地部署:消费级硬件即可运行
Q4 GGUF 版本的 35B 模型可在苹果硅 Mac、普通 Windows PC 上运行,小参数版本甚至有望适配移动端神经引擎。官方提到,配合后续将推出的桌面代理调度工具,端到端操作延迟可从 6.8 秒压缩到 3.3 秒。
开源协议与 API 服务
目前所有 Holo3.1 模型权重已在 Hugging Face 开放下载:
- 35B 版本:Apache 2.0 协议完全开源,可免费商用
- 122B 版本:研究授权,仅对付费用户开放,适用于复杂多步操作场景
官方同时提供 API 服务:
- 免费 tier:每分钟 10 次请求,无需绑定信用卡
- 付费版:输入 token $0.25/百万,输出 token $1.8/百万,上下文长度 65536
- 支持最多 5 张 1080P 图像输入
- API 默认不保留用户的提示词与返回结果,仅记录请求时间、模型与 token 数量等基础日志
开发者社区反馈
该模型发布后引发开发者社区关注。有开发者提到,此前云端代理的延迟和成本足以抵消多数自动化收益,本地高吞吐量的计算机控制模型才是 AI 代理真正进入日常工作的核心前提。也有开发者表示,4B 小参数版本的表现超出预期,有望在端侧设备上实现可用的 AI 操作功能。
相关链接
- 官方技术博客:hcompany.ai/holo3.1
- Holo 模型 API:hcompany.ai/holo-models-api
- Hugging Face 下载:huggingface.co/collections/Hcompany/holo31
总结:Holo3.1 的核心价值在于将 Computer Use 能力从云端拉到本地——35B 版性能超越多个主流闭源模型,同时支持在消费级硬件上离线运行。Apache 2.0 开源协议 + 免费 API tier,降低了开发者的试用门槛。对于关注本地 AI 代理和端侧部署的开发者来说,这是一个值得密切跟进的项目。