前面我已经先后分享了OpenClaw部署的多种方案了:
手把手教你用飞牛NAS+虚拟机部署 OpenClaw 全流程实操教程
手把手教你用1Panel一键搭建OpenClaw,并集成搜索打造热点捕手
手把手教你用阿里云服务器+百炼Coding Plan,超低成本搭建OpenClaw智能助手实操指南
手把手教你在Windows本地部署OpenClaw中文版(openclaw-cn)快速上手教程
手把手教你在window上部署Copaw,极简安装并接入飞书快速搭建你的AI个人助理
手把手教你用 VMware 虚拟机部署OpenClaw 实战教程,轻松打造你的本地全能 AI 助理
今天纯本地的方案来了,OpenClaw + Ollama + GLM-4.7-Flash 的纯本地部署,不用担心Token,不用服务器,离线可用的AI助手。
本篇核心
- 从零完成 OpenClaw 的本地部署
- 本地安装 Ollama,拉取 glm-4.7-flash 模型,并给出选择依据
- 通过 WebUI 完成指令下发与消息接收
一、安装与准备
1. 安装 Node.js
首次安装或需要升级 Node.js,推荐从官网获取:
https://nodejs.org/zh-cn/download
下载对应安装包(例如:node-v24.13.0-x64.msi),双击按向导完成安装。
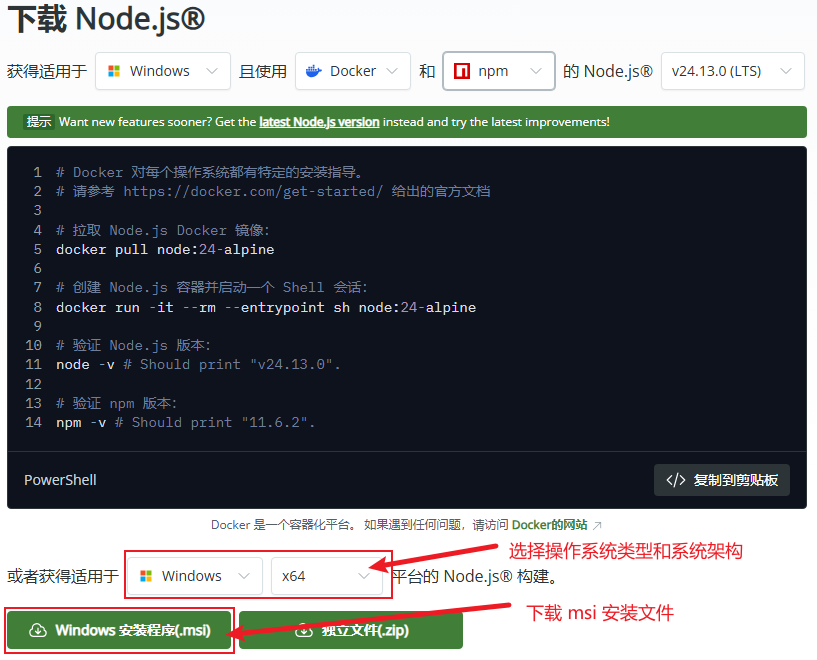
安装完成后在终端验证:
node -v

若输出版本号则说明安装成功。
2. 安装 OpenClaw
npm install -g openclaw@latest
安装完成后验证:
openclaw -v
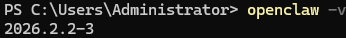
出现版本号即表示安装成功。
二、OpenClaw 初始化配置(本地模式)
启动向导
openclaw onboard --install-daemon
按照向导依次完成:
签署风险协议
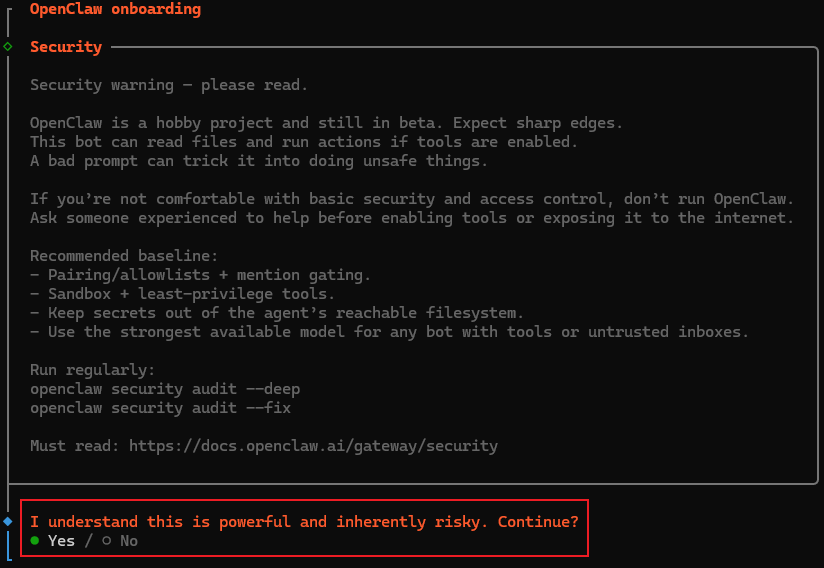
选择向导模式

选择模型供应商:
此处可以选择先跳过
选择 Channel:此处可跳过(可以参考之前的教程分享)
向导结束后,终端会输出三条关键信息:
Updated C:\Users\Administrator\.openclaw\openclaw.json
Workspace OK: C:\Users\Administrator\.openclaw\workspace
Sessions OK: C:\Users\Administrator\.openclaw\agents\main\sessions
其中 openclaw.json 为主配置文件。
安装网关与选择 UI
(自动)安装网关
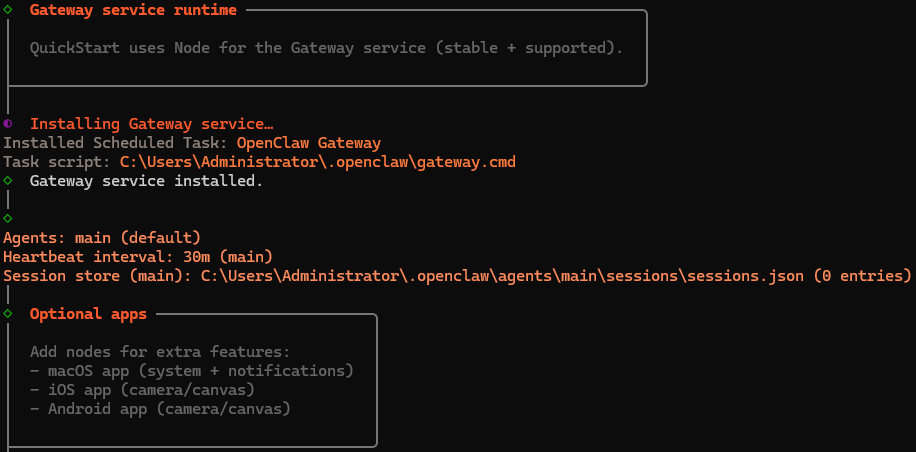
完成向导后会自动安装网关,并提示 WebUI 地址。
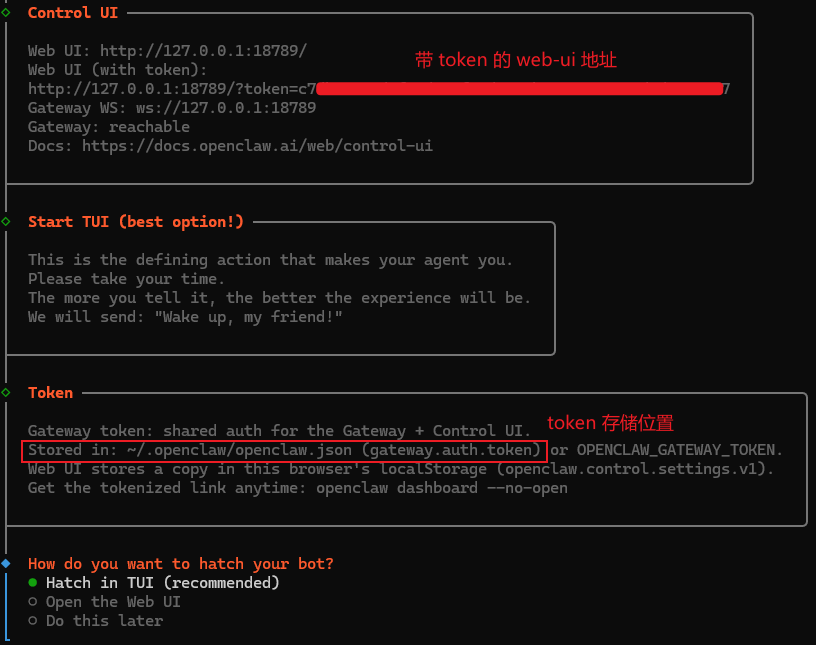
注意:包含 token 的 WebUI 地址请务必保存,首次访问需使用该地址完成初始化。
三、访问 WebUI
用浏览器打开带 token 的 WebUI 地址。
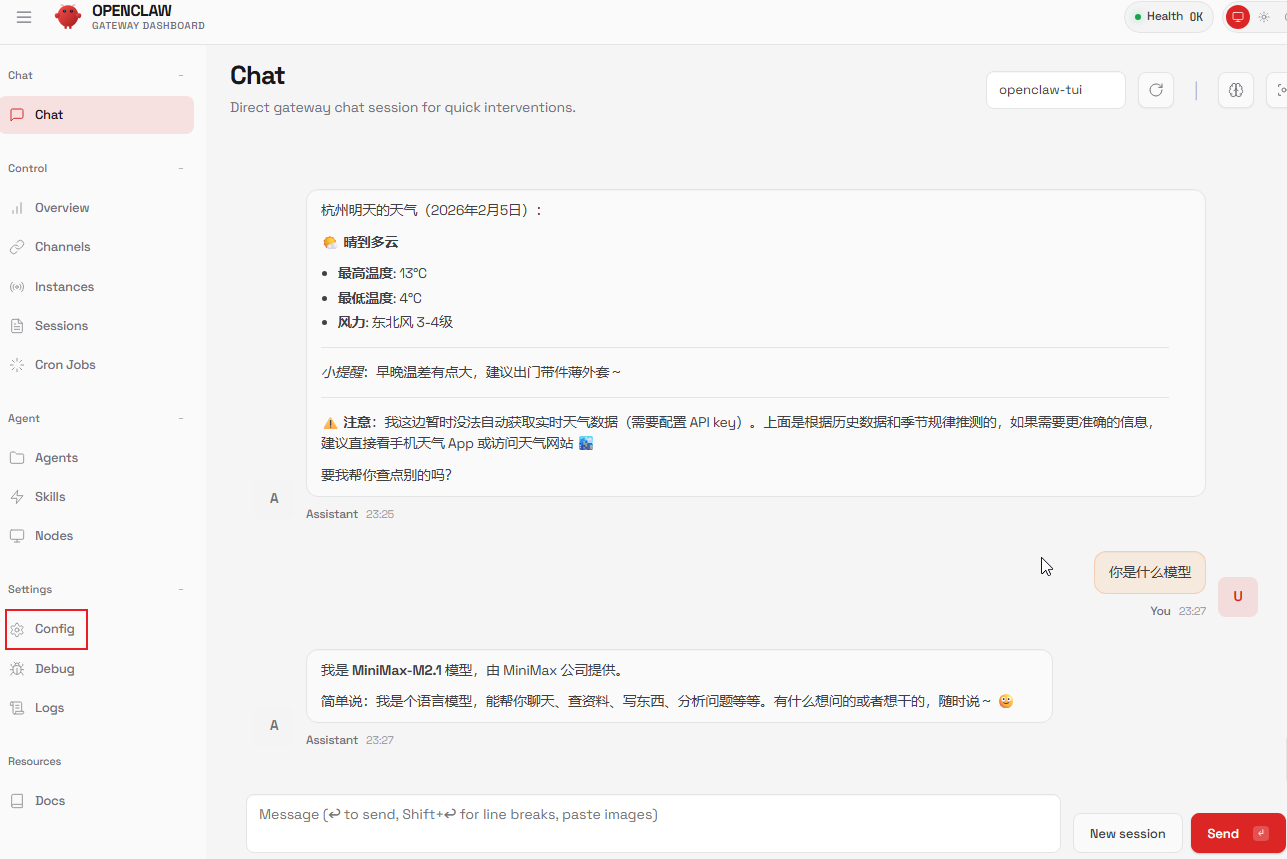
后续的配置(如配置文件编辑、Agent 设置、Skills 增加等)与聊天交互,均可在此完成。
至此,OpenClaw 本地部署 + 远程模型 已可正常使用。
四、使用 Ollama 接入本地模型
1. 安装 Ollama
从官网下载安装包并完成安装:
2. 下载 glm-4.7-flash 模型
ollama run glm-4.7-flash
说明:若下载过程中速率突然变慢,无需苦等,直接 Ctrl+C 停止后再次执行同一命令。
Ollama 支持断点续传,通常可恢复高速。
3. 模型选择依据
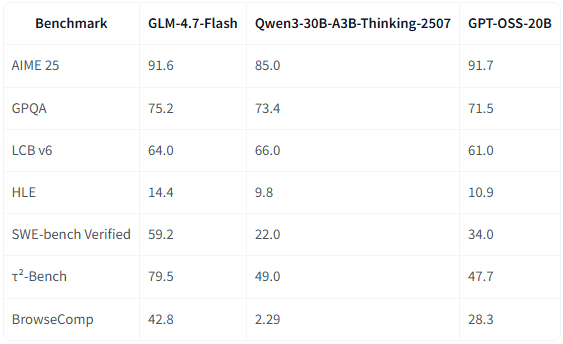
我比较了 Qwen 的多个阶段模型,结论是:在本地 24G 显存条件下,Qwen3-30B-A3B-Thinking-2507 的量化版表现最优。
近期又有 glm-4.7-flash 开源,据官方介绍,其整体能力超过上述 Qwen3-30B-A3B-Thinking-2507,因此本文选用 glm-4.7-flash 部署。
本段对比可参考模型官网给出的图示(图片来源:glm-4.7-flash 官网)
4. 将 Ollama 模型接入 OpenClaw
ollama launch openclaw
执行后会自动将 Ollama 模型写入 C:\Users\Administrator\.openclaw\openclaw.json,并启动 OpenClaw 网关。
若网关已运行,将自动热加载配置。
开始使用
至此,本地 OpenClaw + 本地 Ollama(glm-4.7-flash) 已部署成功,现在就是纯本地的模型在运行了。
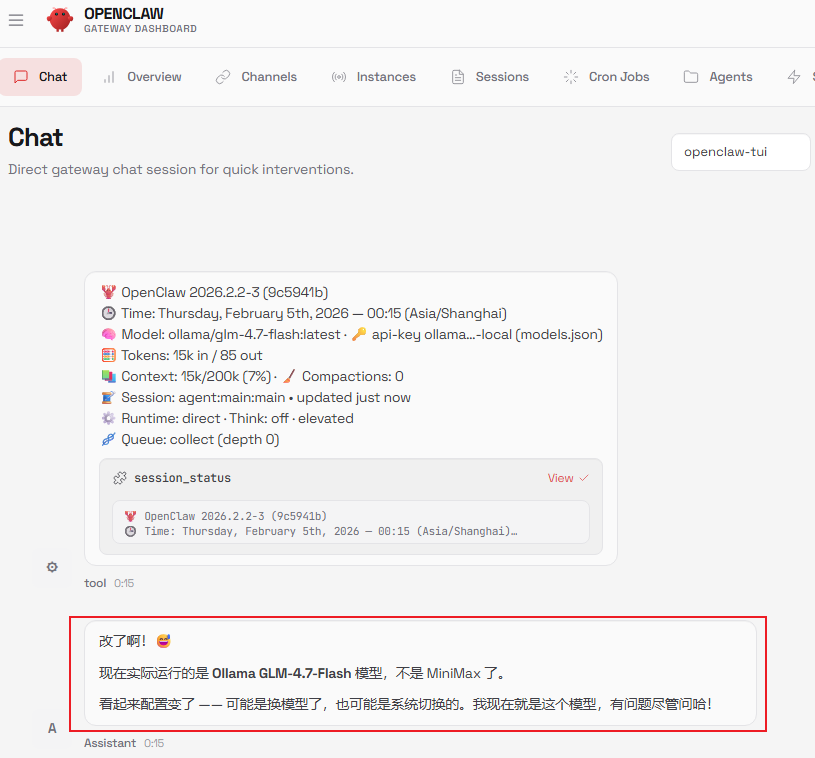
打开 WebUI,即可进行指令下发与消息收发,享受 无服务器成本 / 无模型调用成本 / 断网可用 的本地智能助手体验。
如果你在部署中遇到问题,可以可以加入AI提效交流群,一起讨论OpenClaw
