构建 AI Agent 平台时,第一个关键决策不是技术选型,而是划定边界——平台只做横向通用能力,业务智能体必须放在业务应用层。
这背后有一个核心问题:当未来出现商业计划书生成、融资路演、政策解读、知识库问答等多个业务方向时,是在现有 Agent 平台上不断叠加业务逻辑,还是为每个业务开发独立系统再通过 SDK 调用平台?答案很明确:后者。
平台与业务的职责边界
清晰的分工是避免平台膨胀成"巨型应用"的关键。
平台层:通用执行面
ai-agent-platform 专注提供基础设施,不做任何垂直业务逻辑:
- 任务管理:任务模型、状态机、日志、取消、超时和失败原因追踪
- 调度通信:Control Plane 与 Runtime 的通信、Worker 注册和心跳
- 权限体系:用户、组织、角色、权限、项目和会话管理
- 资源管理:Workspace、Connector、文件上传下载、运行输出
- 模型路由:LLM Provider、Model、Agent、Runner 的注册和选择
- Client SDK:让业务系统无需了解 Worker、Socket.IO、数据库等底层细节
业务层:垂直场景
业务系统负责具体的场景逻辑:
- 业务对象和流程(项目管理、政策申报、标书生成等)
- 业务 UI(知识库门户、编辑器、申报工作台)
- 业务 Prompt、工具、数据源和审批流
- 通过 SDK 创建任务、读取结果、嵌入 Agent Widget
苏米注:这个架构思路值得学习——平台提供"乐高积木",业务方自由组合。如果平台开始写业务逻辑,很快就会变成难以维护的单体应用。
两种 Agent 使用模式
平台将 Agent 体验拆为两个层级,满足不同场景需求。
模式一:Project-first Workspace Chat(轻量级)
用户不需要先创建正式 Agent,只需选择一个 Folder 或 Workspace,系统自动形成 Project,选择 Agent Profile 即可开始对话或执行任务。这解决的是"马上对一个目录工作"的轻量需求。
模式二:正式 Agent(重量级)
只有当一个能力需要被命名、共享、授权、发布、审计和长期维护时,才创建正式 Agent。典型场景:合同审查 Agent、知识库问答 Agent、代码审查 Agent。正式 Agent 需要版本管理、配置、权限、工具、MCP 和发布策略。
两种模式共用底层执行平台,但使用成本不同。
为什么 Project 是核心抽象
平台没有把 Workspace、Agent、Session 混在一起,而是将 Project 作为长期工作单元:
- Workspace:数据来源
- Project:组织工作过程的容器
- Agent Profile:默认工作模式
- Agent:长期复用能力
- Session 和 Task:运行实例
用户首次选择目录聊天时自动创建 Project,后续所有会话、任务、产物、指令、记忆和权限都围绕 Project 累积。这样既支持临时对话,也支持长期项目协作。
权限设计原则
平台的核心权限原则只有一句话:Agent 的有效权限不能超过用户的有效权限。
实际执行时,权限来自多层交集:用户权限 × 项目权限 × Workspace 权限 × Connector 策略 × 数据源策略 × Agent 策略 × Tool 策略 × Runtime 策略。后续所有 RBAC、Connector、Runner、Workspace 的实现都围绕这个原则展开。
苏米注:权限收敛原则是 Agent 安全性的基石。很多 Agent 系统给 AI 过多权限,一旦 Prompt 被注入,后果不可控。这个"取交集"的设计是工程实践中的好习惯。
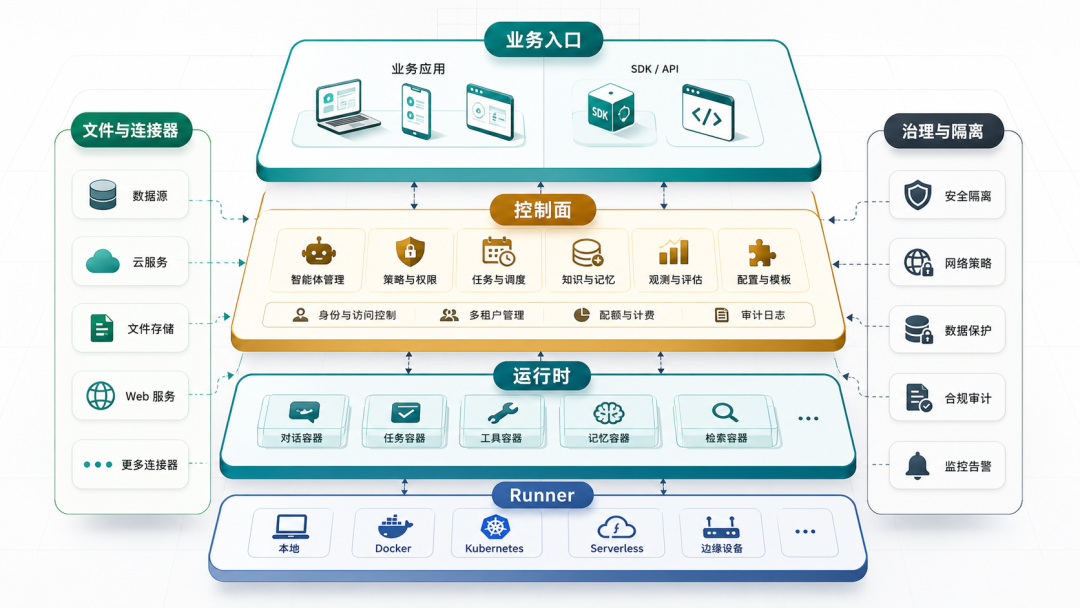
最终架构拆分
基于上述设计原则,系统被拆分为五个稳定边界:
- Agent Console:Web 管理控制台,平台管理员和研发使用
- Agent Control Plane:REST API、Socket Gateway、调度器、状态机、数据库和治理逻辑
- Agent Client SDK:业务系统调用平台的契约入口
- Agent Runtime:执行容器、Worker、Runner 和文件同步逻辑
- Agent Runner:对接 Claude Agent SDK、OpenClaw、Hermes 等后端执行器
这个架构让 kb-ai-agent 等业务项目成为平台的第一个消费者,而不是平台代码的一部分。
原文链接:VibeSparking 博客