DeepSeek 刚刚开源了一套全新的推理优化方案 DSpark,附带详细论文、草稿模型权重以及完整的训练框架 DeepSpec。在 DeepSeek V4 生产环境中的实测结果显示,吞吐量和延迟提升了最高 85%——在不增加任何显卡的前提下,直接拉高了整个大模型服务系统的性能天花板。

为什么 LLM 推理这么慢
大语言模型生成速度慢的根本原因在于其工作机制:每次只能根据前面的内容预测下一个词(token)。生成的内容越长,用户等待的时间就越久,而且 GPU 算力往往还吃不饱。
业内一直在用推测解码(Speculative Decoding)技术来提速。简单说就是找一个小模型先草拟一批词,再让大模型一次性判断对错——全对就一起输出,错了就从错误位置重新计算。
但现有的草稿模型有两个硬伤:
- 顺序生成的草稿模型:自己生成就很慢,拖累了整体进度
- 并行生成的草稿模型:速度快了,但词与词之间毫无关联,越往后"瞎编"的概率越大,被大模型频繁打回
此外,不管草稿质量好坏,全都交给大模型去检查。在系统空闲时没问题,一旦系统满载,这些注定要被废弃的草稿会白白抢占宝贵的计算资源,导致整体吞吐量暴跌。
DSpark 的两招解决方案
第一招:半自回归生成
DSpark 的思路是把顺序生成和并行生成结合起来:主体部分保持并行计算(保住极致的生成速度),在最后面加了一个极其轻量的顺序处理模块。有了这个模块,草稿词之间就有了上下文联系——前一个词预测了"理所",后一个词就会顺理成章地给出"当然",彻底避免了前言不搭后语的问题。
这样即使是长串草稿,也能保持极高的采纳率。
第二招:硬件感知的置信度调度
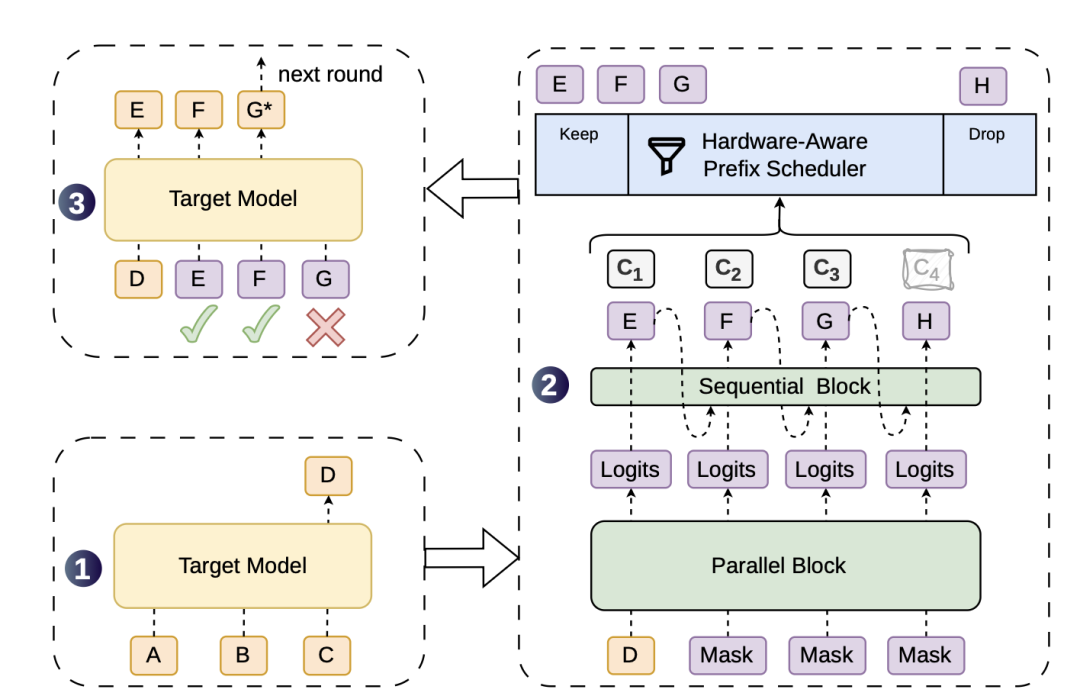
有了高质量的长草稿,下一步是决定让大模型检查多少个词。DSpark 给小模型装了一个打分器,专门预测每个草稿词"存活下来"的概率。
更重要的是,系统会实时监控当前的算力负载:
- 算力富裕时:放行更多草稿词去验证,充分榨干闲置算力
- 算力紧张时:立刻变得严格,直接砍掉得分低的草稿词,确保计算资源只花在最有可能成功的词上
苏米注:这个"硬件感知"的设计是 DSpark 区别于其他推测解码方案的关键。大多数方案只关注算法层面的优化,而 DSpark 把系统运行时的真实负载纳入了决策循环,这在生产环境中意义重大——它让加速效果不再是实验室里的理想数据,而是能在高并发场景下稳定发挥。
实战成绩
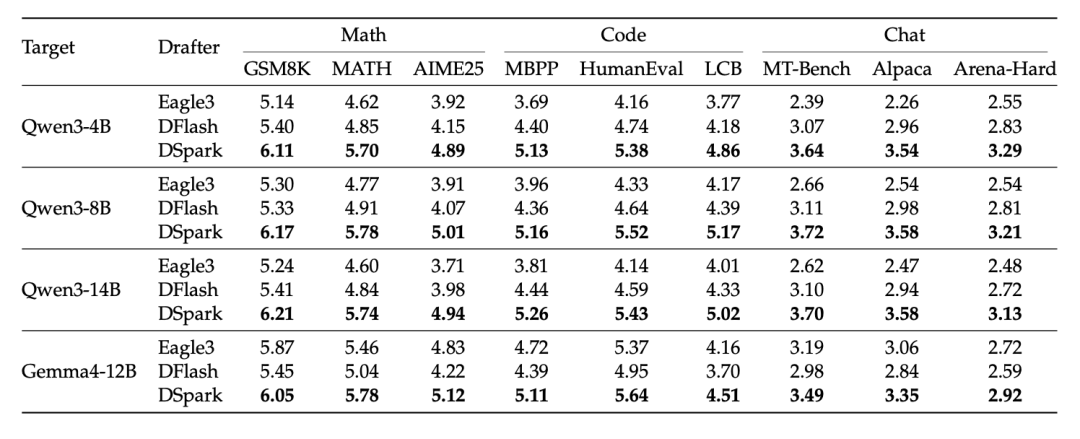
在纯算法测试中,无论是数学逻辑解答、代码编写还是日常聊天,DSpark 在 Qwen 和 Gemma 等不同规模的模型上都碾压了现有的各种草稿模型,草稿采纳长度大幅提升。
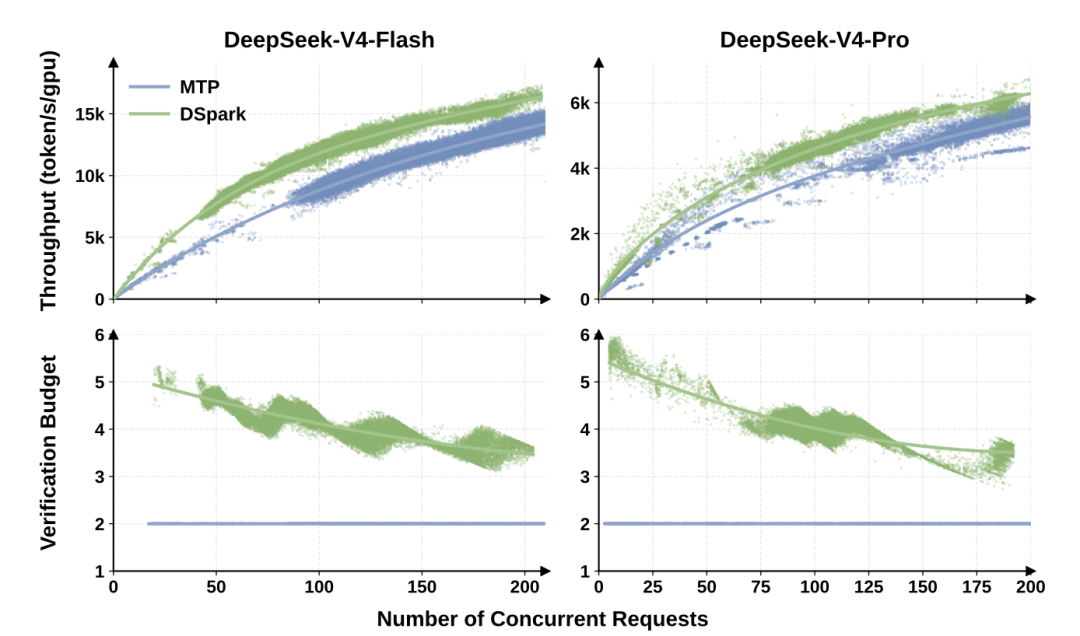
更值得关注的是真实生产环境的实战表现。研发团队将 DSpark 直接部署到了 DeepSeek V4 的线上服务系统中,在和老一代生产基线保持相同整体吞吐能力的前提下:
- V4 Flash 和 V4 Pro 的每个用户生成速度大幅提升,最高达到 85%
- 极限高并发时系统更稳定:老系统会因为资源争抢而崩溃掉速,DSpark 能动态缩减验证长度,死死稳住响应底线
开源内容
目前研发团队已经把 DSpark 的模型权重连同底层训练库 DeepSpec 一并开放。DeepSpec 是一个用于训练和评估推测解码草稿模型的完整代码库,包含:
- 数据准备
- 草稿模型实现
- 训练代码
- 评估脚本
目前支持 DSpark、DFlash 和 Eagle3 三种算法,所有开发者都可以直接体验这套前沿的推理加速方案。