谷歌最新的开源模型 Gemma 4 原生支持 function calling,可以装在自己的电脑上并接入 OpenClaw,实现 token 成本归零。
关键亮点:Gemma 4 是 Gemma 家族第一次用 Apache 2.0 协议开源,支持商用、魔改、二次分发。配合 Ollama 大版本更新,在 Apple Silicon 上使用苹果自家的 MLX 框架推理,速度翻倍。
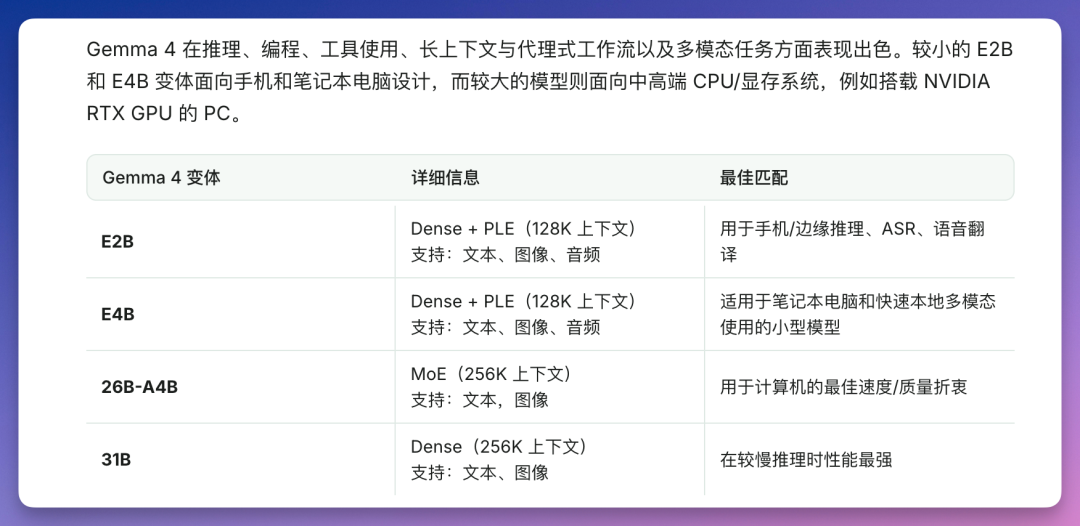
Gemma 4 四个版本如何选择
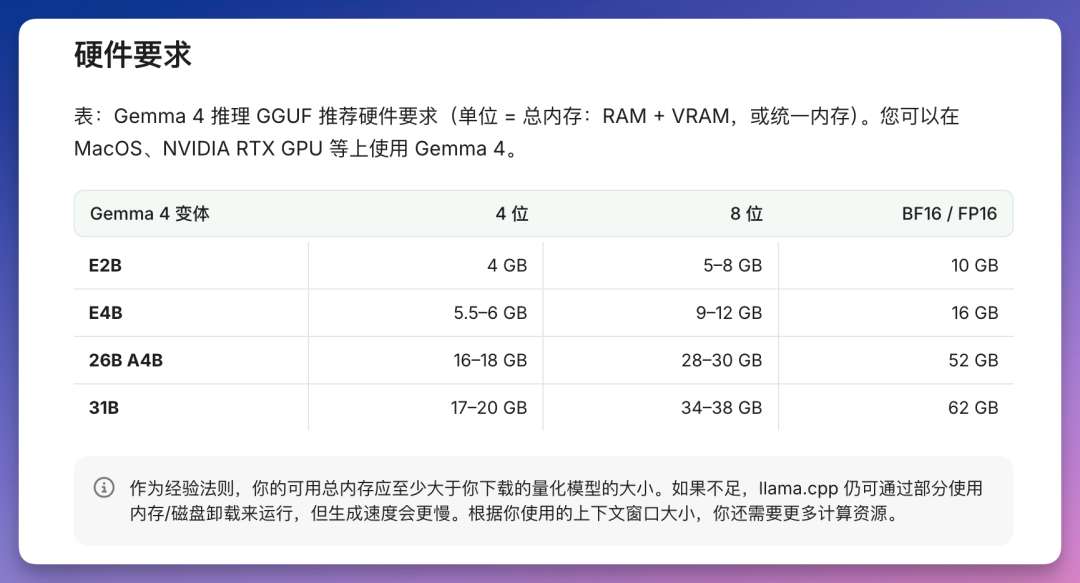
Gemma 4 提供四个版本,以下是 4-bit 量化后的内存需求:
| 版本 | 参数 | 内存需求 | 上下文 | 特点 |
|---|---|---|---|---|
| E2B | 23 亿 | ~4 GB | 128K | 支持图片、音频,手机/树莓派可跑 |
| E4B | 45 亿 | ~5.5 GB | 128K | 支持图片、音频,适合日常聊天 |
| 26B | 252 亿 (MoE) | 16-18 GB | 256K | 激活 38 亿参数,性价比最高 |
| 31B | 307 亿 | 17-20 GB | 256K | 满血版,编程/数学能力最强 |
选择建议:
- 4 GB 内存 → E2B
- 6 GB 内存 → E4B
- 18 GB 内存 → 26B(推荐,性价比最高)
- 20 GB 以上 → 31B(满血版)
26B 采用混合专家架构(MoE),总参数 252 亿但每次推理只激活 38 亿,速度接近小模型,质量接近满血版。24 GB 内存的 Mac 或 24 GB 显存的显卡即可运行。
31B 满血版在 Arena AI 开源排行榜位列第三,AIME 2026 数学推理 89.2%,编程 LiveCodeBench 80.0%。
Mac 用户部署步骤
步骤一:安装 Ollama
Ollama 是运行本地模型最简单的工具,模型下载、推理引擎、API 服务一个 App 搞定。
使用 Homebrew 安装:
brew install --cask ollama-app
步骤二:启动 Ollama
open -a Ollama菜单栏会出现羊驼图标,等待几秒钟初始化完成。
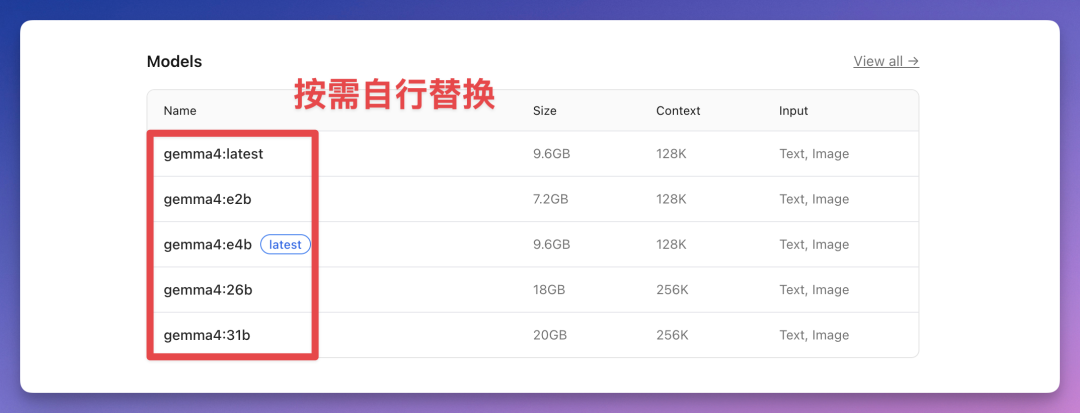
步骤三:下载并运行模型
根据内存选择模型,以 26B 为例:
ollama run gemma4:26b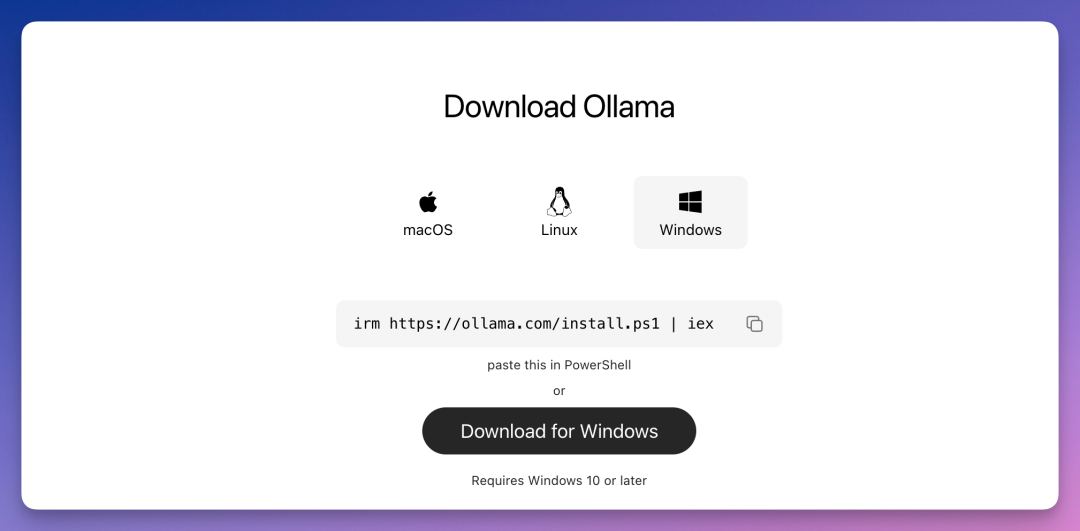
Ollama 会自动下载模型并启动对话。26B 约 18 GB,需要耐心等待。
下载完成后直接进入聊天界面,随便问一句测试是否成功。
查看模型运行状态
ollama ps你可以看到 CPU/GPU 的推理分配比例,例如「14%/86% CPU/GPU」。在 Apple Silicon 上,大部分计算跑在 GPU 上,速度比纯 CPU 快得多。
Windows 用户部署步骤
步骤一:安装 Ollama
打开 PowerShell,一行命令安装:
irm https://ollama.com/install.ps1 | iex
步骤二:运行模型
打开新的 PowerShell 窗口:
ollama run gemma4:26b有 NVIDIA 显卡的话,Ollama 会自动调用 CUDA 加速。没有独显也能跑,速度会慢一些。
NVIDIA 用户注意:Ollama 0.19 新增了 NVFP4 格式支持,用更少的显存跑模型,精度损失很小。RTX 40 系及以上显卡自动生效。
通过 OpenClaw 远程部署
如果你已经有 OpenClaw 环境,可以直接让 AI 助手帮你完成部署,全程无需手动敲命令。
1. 安装 Ollama
对 OpenClaw 说:
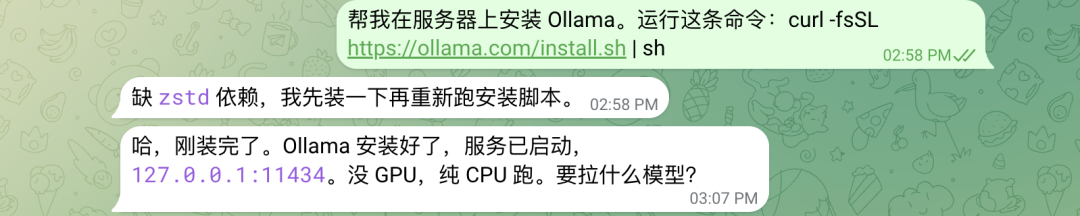
在服务器上安装 Ollama,运行这条命令:
curl -fsSL https://ollama.com/install.sh | shAI 助手会自动发现并安装缺失的依赖(如 zstd),然后重新运行安装脚本。
2. 下载模型
下载 Gemma 4 26B 模型:ollama pull gemma4:26b
3. 测试运行
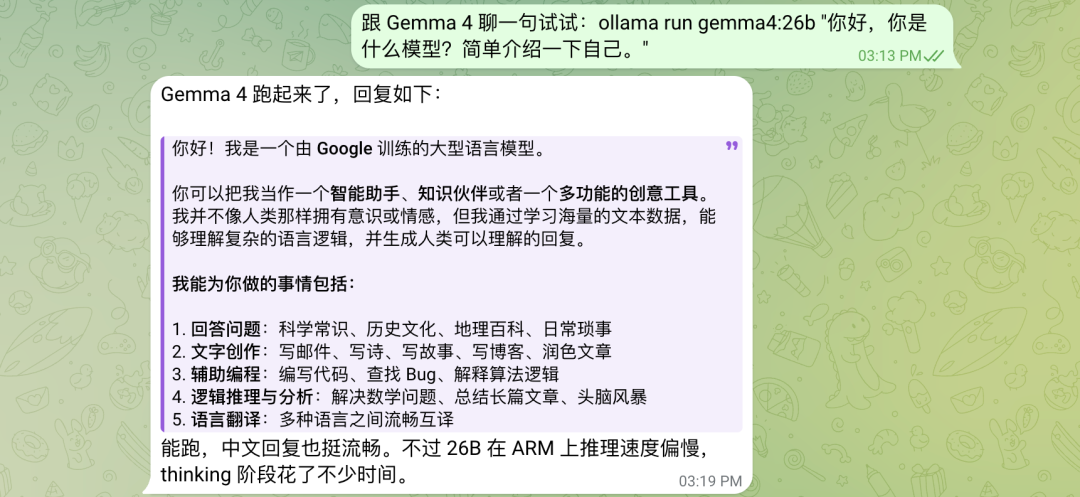
跟 Gemma 4 聊一句试试:ollama run gemma4:26b "你好,你是什么模型?简单介绍一下自己。"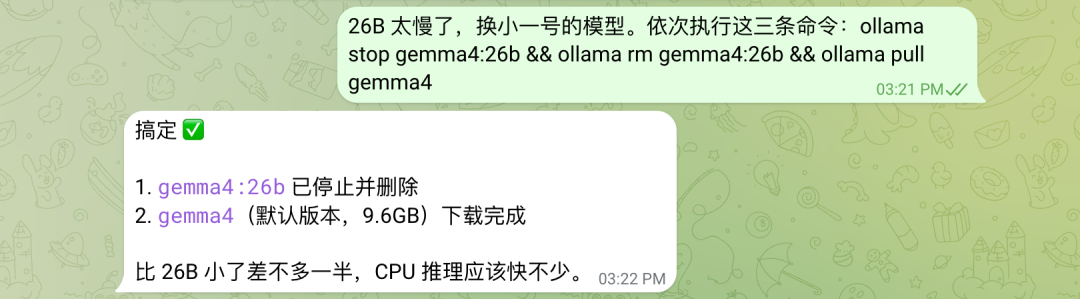
4. 切换模型版本
如果 26B 在纯 CPU 上推理较慢,可以切换到小模型:
换成 E4B 模型
速度会明显提升。
进阶:接入 OpenClaw 作为主力模型
部署完成后,可以将 OpenClaw 的模型后端切换到本地 Gemma 4,API 端点指向 localhost:11434,从此不再需要云端 API。
苏米注:推荐满血版 31B 作为主力模型,小模型更适合端侧设备。26B MoE 版本在性能和资源消耗之间取得了很好的平衡,是大多数用户的首选。
Ollama 常用命令速查
| 命令 | 说明 |
|---|---|
ollama list |
查看已下载的模型 |
ollama ps |
查看正在运行的模型和内存占用 |
ollama run gemma4:26b |
启动对话 |
ollama stop gemma4:26b |
卸载模型释放内存 |
ollama pull gemma4:26b |
更新到最新版本 |
ollama rm gemma4:26b |
删除模型 |
总结
Gemma 4 本地部署只需三步:

- 安装 Ollama(Mac 用 Homebrew,Windows 用 PowerShell)
- 根据内存选择版本并下载(推荐 26B MoE)
- 运行
ollama run gemma4:xx开始使用
通过 OpenClaw 可以实现全自动化部署,无需手动敲命令。部署完成后,可将 OpenClaw 接入本地 Gemma 4,实现零成本运行。
核心优势:
- Apache 2.0 开源协议,可商用
- 4-bit 量化降低内存需求
- Ollama 一键部署,跨平台支持
- 接入 OpenClaw 实现零 token 成本