本文介绍如何在本地运行AI大模型,使用目前主流的两个工具:Ollama和LM Studio。一个适合开发者,一个适合所有人。
为什么要本地运行大模型?
本地运行大模型的核心优势:
- 零费用:没有API调用计费,运行多少次都不花钱
- 隐私安全:数据完全留在本地,不上传任何服务器,适合处理敏感信息
- 无网络依赖:断网也能用,响应速度只取决于硬件
- 高度可定制:可以加载各种开源模型,自由调整参数
本地运行也有局限:需要一定的硬件配置(主要是内存和显存),模型能力通常比GPT-4、Claude等顶级商业模型稍弱。但对于日常写作、代码辅助、文档问答等任务,完全够用。
Ollama
Ollama是一个开源工具,能通过一行命令下载并运行各种主流开源大模型,堪称本地AI界的"Docker"。支持macOS、Linux和Windows,背后维护活跃,更新很快。
官方网址:https://ollama.com/
如果国内环境无法下载Ollama,可以试试 https://cnb.cool/hex/ollama 下载安装。
支持哪些模型?
Ollama的模型库非常丰富,主要包括:
- Llama系列:Meta出品,综合能力强
- Qwen系列:阿里出品,中文表现优秀
- Gemma系列:Google出品
- GLM系列:智谱AI出品
- Minimax系列:MiniMax出品
- Mistral/Mixtral系列:法国团队,代码能力突出
- DeepSeek系列:国产推理模型,数学逻辑强
- Phi系列:微软出品,小而精
如何使用
首先到官网 https://ollama.com/download 下载并安装。
然后下载安装需要的模型,可以在 https://ollama.com/search 找到合适的模型,打开详情页,根据电脑性能选择合适的模型尺寸。
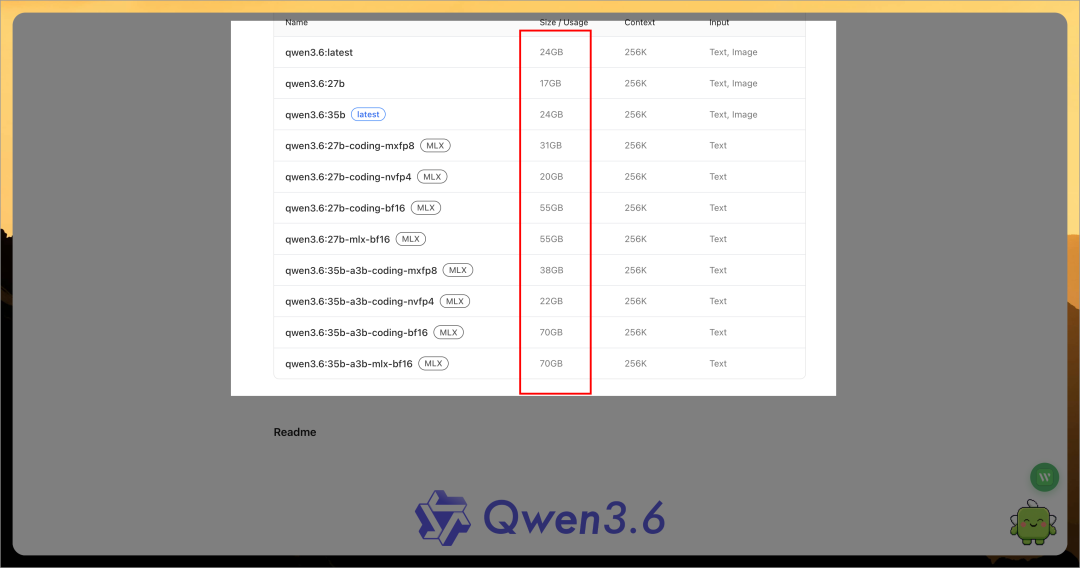
打开电脑命令行工具,输入以下命令进行下载并运行:
ollama run qwen3.6:27b
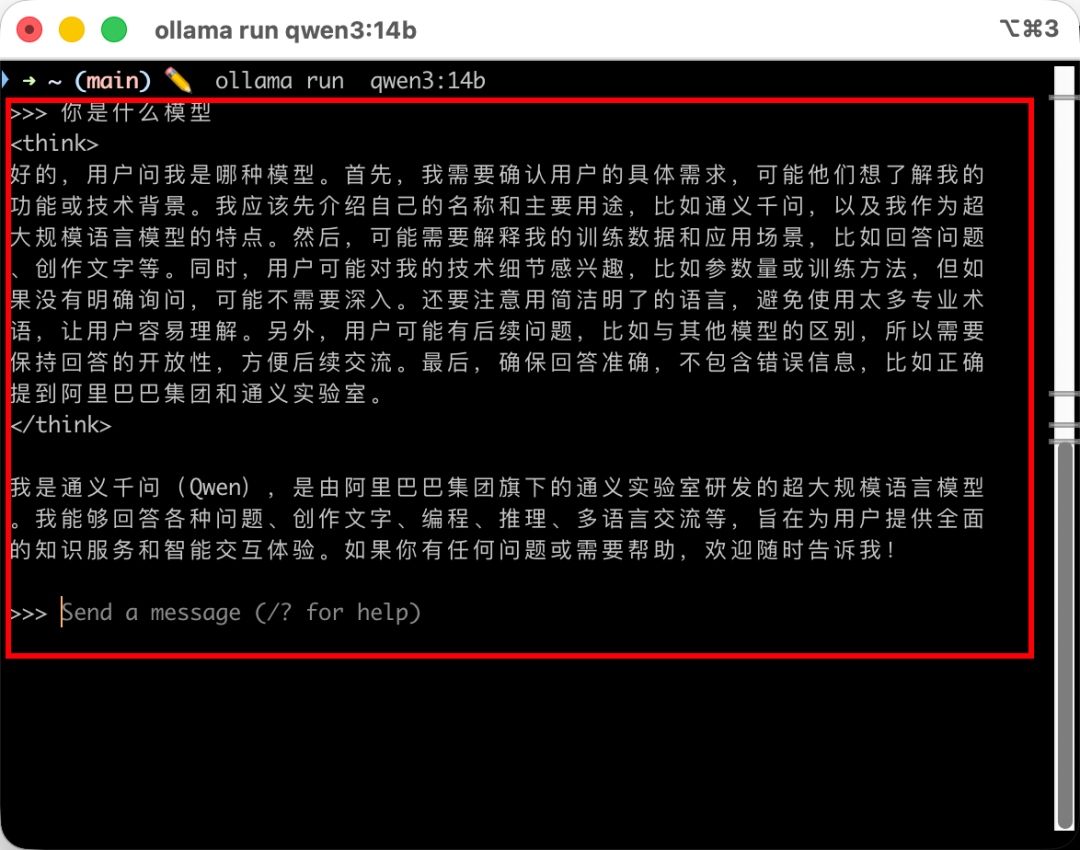
等待下载安装完成后,就可以自由跟这个AI大模型对话了。
常用命令
# 下载并运行 Llama 3(8B 参数版本)
ollama run llama3
# 下载并运行中文友好的 Qwen
ollama run qwen3
# 列出已安装的模型
ollama list
# 删除模型
ollama rm llama3
运行后直接在终端对话,或者通过内置的REST API(默认 http://localhost:11434)接入自己的应用,接口格式与OpenAI API兼容,几乎可以无缝替换。
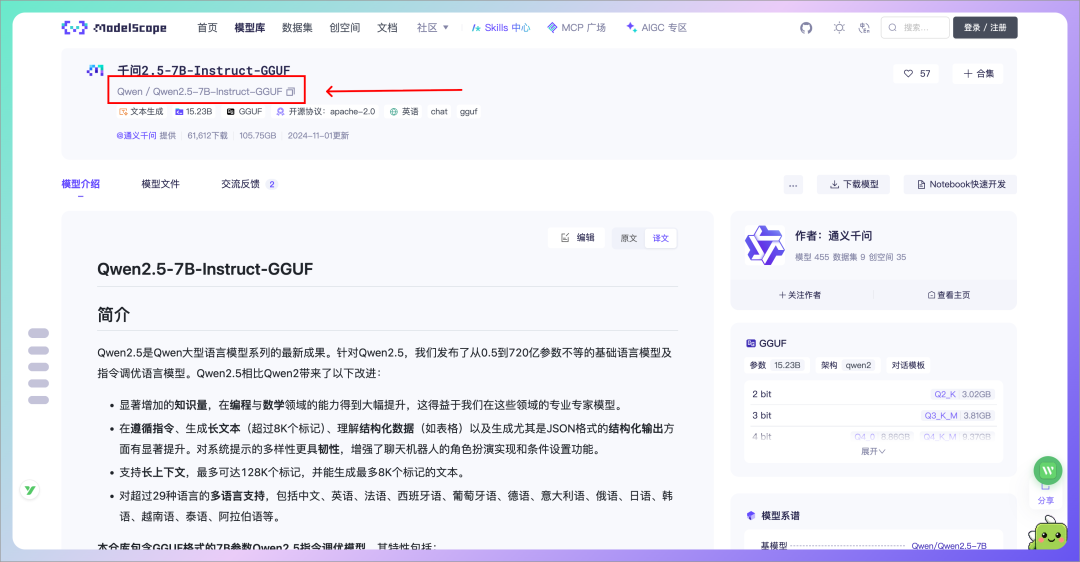
国内模型加速下载
如果在国内下载模型很慢,可以试试ModelScope的方案。在 https://modelscope.cn/models?libraries=GGUF 找到合适的模型,然后把命令里面模型名称改成:
ollama run modelscope.cn/{model-id}
其中{model-id}替换成具体模型名称即可,格式是{username}/{model},比如:
ollama run modelscope.cn/Qwen/Qwen2.5-3B-Instruct-GGUF
ollama run modelscope.cn/second-state/gemma-2-2b-it-GGUF
ollama run modelscope.cn/Shanghai_AI_Laboratory/internlm2_5-7b-chat-gguf
客户端使用
对于非技术用户,命令行界面可能不太方便,推荐以下客户端:
1. Ollama官方客户端
下载并安装好Ollama后,会自带一个客户端界面,可以在输入框右下角直接选择要使用的AI模型,然后正常进行对话。
2. ChatWise客户端
ChatWise是一款本地AI大模型聊天客户端,官方网址:https://docs.chatwise.app/。使用方式类似,在对话页面左上角切换模型。
3. WiseMindAI客户端
WiseMindAI是一款本地优先的AI学习与知识工作台。不仅支持使用本地AI模型进行文档总结、对话,还支持AI知识库、知识卡片等功能。让资料处理、知识沉淀和成果输出都在一个地方完成。
官方网址:https://wisemindai.app/
所有的对话记录都可以保存成笔记、知识卡片,还可以做成海报直接分享。
LM Studio
如果不喜欢命令行,LM Studio是更好的选择。它提供了一个漂亮的桌面GUI,让你像用普通软件一样管理和使用本地大模型,支持macOS、Windows和Linux。
官方网址:https://lmstudio.ai/
核心功能
1. 模型市场
内置模型搜索界面,可以直接搜索并下载Hugging Face上的GGUF格式模型,无需手动折腾。
2. 类ChatGPT对话界面
下载好模型后,可以直接在软件里和模型对话,界面清晰,支持多轮对话历史管理。
3. 本地API服务器
一键开启本地OpenAI兼容API,让其他工具(如Cursor、Continue、Open WebUI)直接接入本地模型。
4. 多模型对比
可以同时加载多个模型,进行横向对比,找到最适合自己需求的那一个。
如何使用
打开LM Studio后,在左侧"Model Search"菜单按钮,打开弹窗,直接选中要使用的模型,点击右侧下载即可。
也可以到官网 https://lmstudio.ai/models 搜索并安装。
下载完成后,点击左侧第一个菜单"Chat",在顶部选择下载好的模型,点击"加载模型"按钮。
接下来就可以和AI模型对话了。LM Studio还支持很多对话设置,比如预设提示词、系统提示词等。
在WiseMindAI中,也可以直接使用LM Studio的本地AI模型,这样就可以完全离线去使用各种AI功能,特别是一些有隐私要求的文档,可以在离线情况下进行文档总结、对话、生成思维导图等。
Ollama vs LM Studio:怎么选?
| 对比维度 | Ollama | LM Studio |
|---|---|---|
| 操作方式 | 命令行 | 图形界面 |
| 上手难度 | 需要基础终端知识 | 零门槛 |
| API集成 | 原生支持,OpenAI兼容 | 支持,需手动开启 |
| 模型来源 | Ollama官方模型库 | Hugging Face(GGUF格式) |
| 适合场景 | 开发集成、自动化脚本 | 日常对话、模型体验 |
| 性能开销 | 极低(纯后台服务) | 稍高(带GUI) |
| 跨平台 | macOS/Linux/Windows | macOS/Windows/Linux |
简单建议:
- 你是开发者,想把AI接入自己的应用 → 选Ollama
- 你只是想在电脑上和AI聊天,省掉订阅费 → 选LM Studio
- 两者也可以同时安装,各取所长
硬件要求参考
本地运行大模型对硬件有一定要求,以下是常见模型的内存参考:
| 模型规模 | 推荐内存/显存 | 可用模型举例 |
|---|---|---|
| 3B参数 | 4GB | Phi-4-mini、Gemma 3 3B |
| 7B参数 | 8GB | Llama 3.1 8B、Qwen 2.5 7B |
| 14B参数 | 16GB | Qwen 2.5 14B、Gemma 3 12B |
| 32B+参数 | 32GB+ | Qwen 2.5 32B、Llama 3.3 70B(量化版) |
没有独立显卡也没关系,两款工具都支持纯CPU运行,只是速度会慢一些。有Apple Silicon(M1/M2/M3/M4)的Mac用户体验尤其好,Metal GPU加速效果出色。
模型推荐清单(2026最新版)
以下是目前实际在用或测试过值得推荐的模型:
- 日常中文对话:qwen3.6:9b(阿里Qwen系列的最新一代,中文理解依然是开源里最强的,8GB显存即可跑)
- 代码辅助:qwen3.6:27b(2026年4月刚发布,SWE-bench成绩达到77.2%,和Claude Opus 4.5打平,代码质量令人惊喜)
- 综合推理/长文档:gemma4(Google出品,MoE架构,256K超长上下文,推理速度快,本地跑起来非常流畅)
- 低配设备:phi4-mini(微软出品,3.8B参数,4GB内存可跑,速度15-20 tokens/s,轻量但表现出乎意料地好)
- 强推理/数学逻辑:deepseek-v3.2-exp:7b(DeepSeek最新推理实验版,数学和逻辑分析很强)
如果机器内存够大(32GB+),可以试试qwen3.5:72b或llama4:8b,综合质量已经非常接近云端的GPT-4o mini,本地跑完全免费。
总结
云端AI服务固然强大,但本地开源模型已经足以覆盖大多数日常需求。借助Ollama和LM Studio,任何人都可以在自己的电脑上免费运行AI大模型,彻底告别API账单,同时获得更好的数据隐私保护。