在研发团队中,需求理解偏差和沟通成本一直是效率瓶颈。尽管 AI 代码补全工具(如 Copilot)已普及,但它们主要解决的是「写单个函数更快」的问题,并未触及从需求到交付的整条链路效率瓶颈。
现在的趋势是构建「AI 原生研发流水线」:将一份 PRD(产品需求文档)输入系统,由 AI 自动理解需求、拆解任务、生成代码、运行测试并提交到仓库,实现从需求输入到代码交付的闭环。
一、什么是 AI 原生研发流水线?
「AI 辅助开发」与「AI 原生研发流水线」有本质区别。前者是把 AI 当工具,主动权在人;后者是把 AI 嵌入研发流程本身,AI 是执行主体,人负责把关和决策。
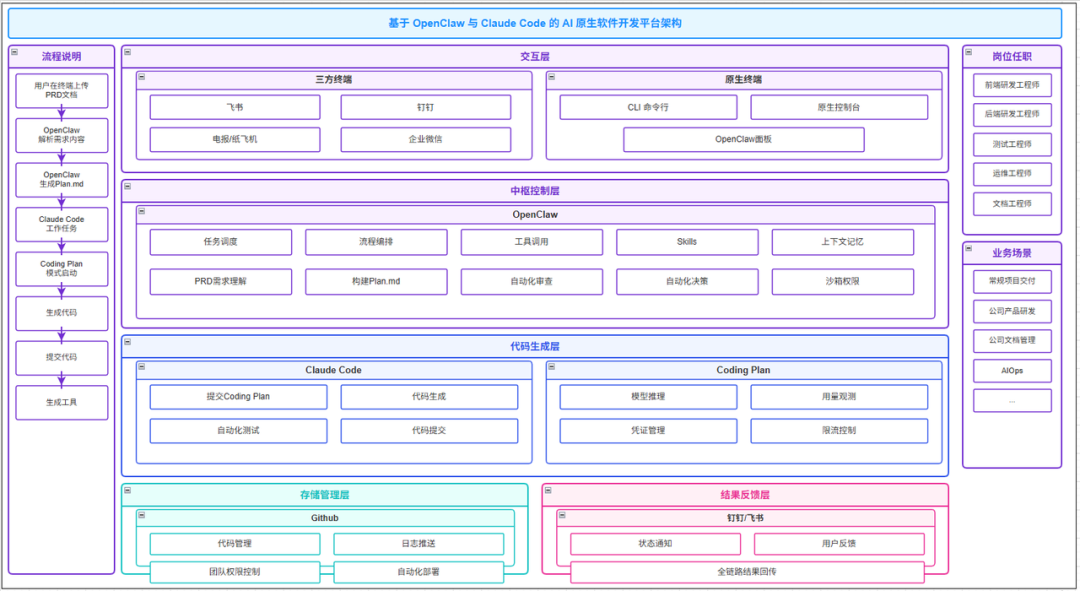
这套架构通常分为五层:
- 交互层:用户通过飞书、钉钉或 CLI 提交需求指令。
- 中枢控制层:OpenClaw 负责理解需求、拆解任务、制定计划并调度流程。
- 代码生成层:基于 Claude Code 进行代码生成,通过 Coding Plan 管理模型调用与开发步骤。
- 存储管理层:GitHub 进行版本管理,结合自动化部署机制完成交付。
- 结果反馈层:将任务进度、执行结果推送给用户。
简而言之,OpenClaw 是大脑,负责读懂需求、规划方案;Claude Code 是双手,负责把想法变成能跑的代码。
二、一份 PRD 是如何变成代码的?
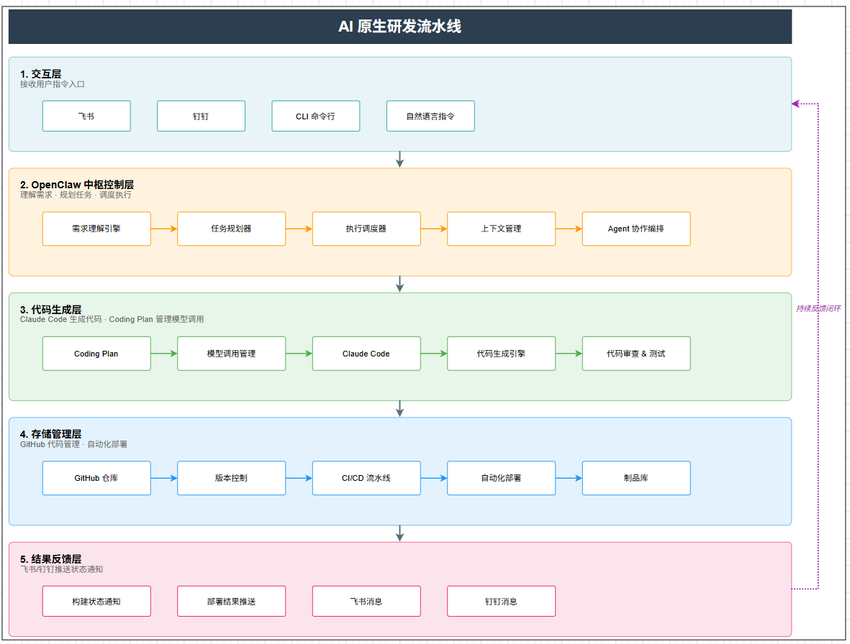
整个流程分为五个步骤:
Step 1:上传 PRD,OpenClaw 解析需求
用户将 PRD 文档提交给系统。OpenClaw 进行结构化理解,将自然语言转化为机器可执行的任务描述,识别核心功能、边缘情况、依赖关系和歧义点。
Step 2:生成 Plan.md,把需求变成任务树
OpenClaw 生成一份 Plan.md,这是一个有层级、有优先级、有依赖关系的任务树。每个子任务明确输入输出和前置依赖,成为团队成员的参考依据。
Step 3:Claude Code 启动 Coding Plan 模式
Claude Code 进入 Coding Plan 模式,背后有一套调度机制在运转:模型推理、用量观测、限流控制和凭证管理。这确保了代码生成在工程约束下可控地进行。
Step 4:生成代码 + 自动化测试
流水线同步生成对应的测试用例并自动执行。测试不通过,代码不会提交,将测试变成了强制约束。
Step 5:提交代码,结果回传
测试通过后,代码自动推送到 GitHub,触发部署流程。同时,飞书或钉钉收到状态通知。整条链路每一步都有记录,可追溯、可回放。
三、OpenClaw 的「中枢大脑」作用
虽然 Claude Code 负责写代码,但最难的部分在于 OpenClaw 的中枢控制:
- 任务调度与流程编排:处理多任务并行时的依赖关系和执行顺序,避免「各跑各的,最后合不上」。
- 上下文记忆:在跨任务、跨会话的情况下保持对项目背景的理解,让 AI 能参与完整项目。
- Skills 体系:将沉淀的处理逻辑和最佳实践封装成可复用的 Skill,让流水线越用越快。
- 自动化审查与沙箱权限:代码生成和测试在沙箱中运行,生产环境操作需人工确认,平衡了 AI 自主性和人的管控权。
四、适用场景与挑战
最适合的场景:
- 需求文档清晰、功能边界明确的业务系统(后台管理、数据报表、内部工具)。
- 重复性高、模式固定的开发工作(CRUD、API 接入、文档站点)。
- 有现成技术规范、不需要大量架构决策的项目。
暂时存在挑战的场景:
- 产品形态不确定、需要大量探索和迭代的早期产品。
- 底层架构重构(涉及大量历史债务和隐性约束)。
- 强交互创新、需要频繁用户验证的体验设计。
五、工程师的价值
流水线替代的是研发链路中可被规则描述、可重复执行的部分(如写登录接口、跑回归测试)。真正需要工程师的地方在于:在需求模糊时判断方向、在系统遇到前所未有问题时找出根因、在技术选型时权衡长期代价。
流水线是放大器,不是替代品。它把工程师从重复劳动中解放出来,让人专注于需要判断和经验的高价值工作。