制作视频时,很多人希望语音能更有特色——无论是音色还是语气。市面上很多工具要么声音固定,要么需要充值才能使用声音克隆功能。
今天介绍的 Voicebox 是一款开源免费的声音克隆工具,所有数据和模型都运行在本地,普通电脑也能用,不消耗 Token,不限次数。
什么是 Voicebox?
Voicebox 是一款以本地化为核心的 AI 语音工作室。你可以使用它从短短几秒钟的语音中克隆声音,生成语音,支持中文、英语、日语、阿拉伯语等多国语言。
核心功能
- 声音克隆:从参考音频中克隆声音,生成自然语音
- 语音特效:为生成的语音增加混响、延迟、合唱等特效
- 语音转文本:将语音转换为对应文本(基于 Whisper)
- RESTful API:每个操作都有对应的 API 接口
- MCP 集成:可通过 MCP 协议与 Claude Code、OpenClaw 等 Agent 结合
- 多平台部署:支持 Windows、Linux、macOS、Docker
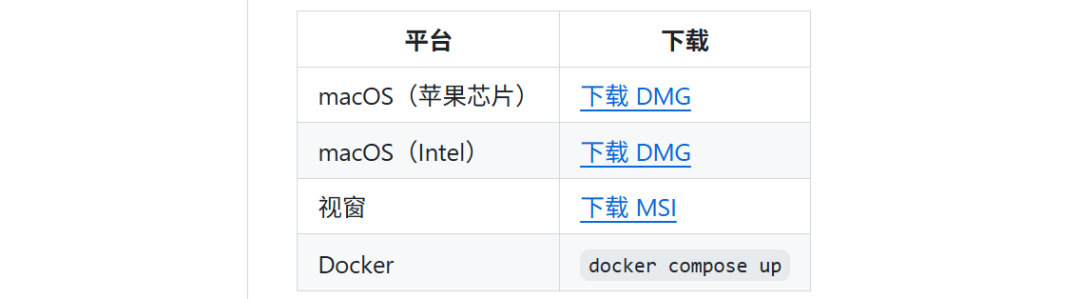
支持的 TTS 开源模型
Voicebox 支持 7 种开源文本转语音大模型:
| 模型 | 特点 | 适用场景 |
|---|---|---|
| Qwen TTS | 支持 1.7B/0.6B 两种规格,中文处理效果佳 | 多语言克隆,中文优先 |
| Qwen CustomVoice | 9 种预设音色,无需参考音频也能生成 | 快速生成,中文支持 |
| LuxTTS | 轻量级,1GB 显存即可运行,CPU 友好 | 英文语音生成 |
| Chatterbox TTS | 支持 23 种语言,语言覆盖最广 | 多语言需求 |
| TADA | HumeAI 语音模型,长文本处理效果最佳 | 长文本转语音 |
| Kokoro | 90+ 预设音色,仅 84MB,适合 CPU 推理 | 轻量快速生成 |
| Whisper | OpenAI 开源模型,支持 base/small/large 版本 | 语音转文本 |

安装与使用
安装
访问官网 https://voicebox.sh/,下载对应系统的安装包,双击安装即可。
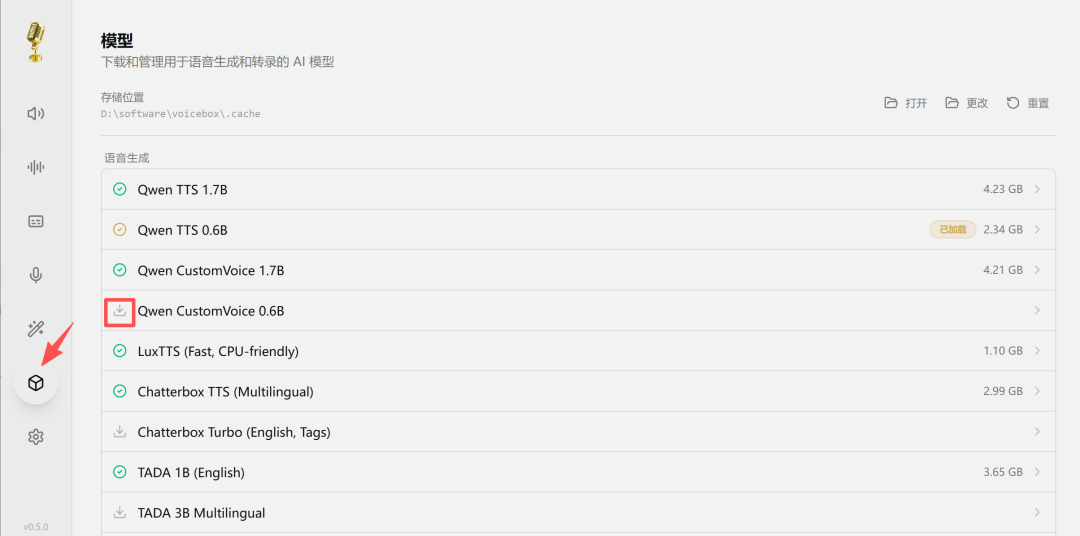
下载模型
安装完成后,在左侧菜单「模型」中选择需要的模型下载。模型从 HuggingFace 获取,体积较大,需耐心等待。
克隆声音
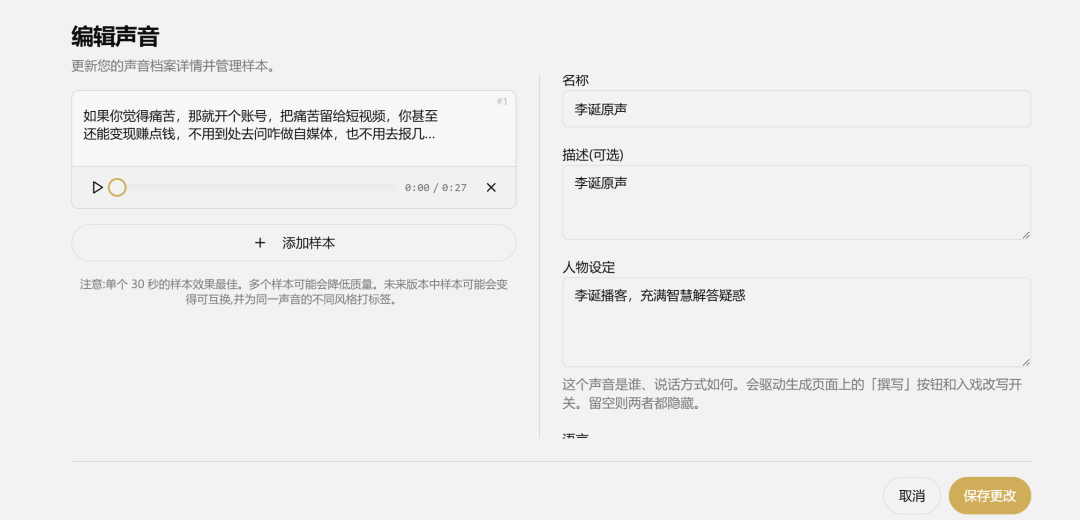
- 创建声音,准备参考音频(建议单个 30 秒样本效果最佳)
- 填写必要信息,添加声音样本时需写出声音的文本内容
生成语音
复制文本,添加到 Voicebox 输入框中,选择语言和模型即可生成。以 Qwen-TTS 0.6B 为例,约 10 秒即可生成。
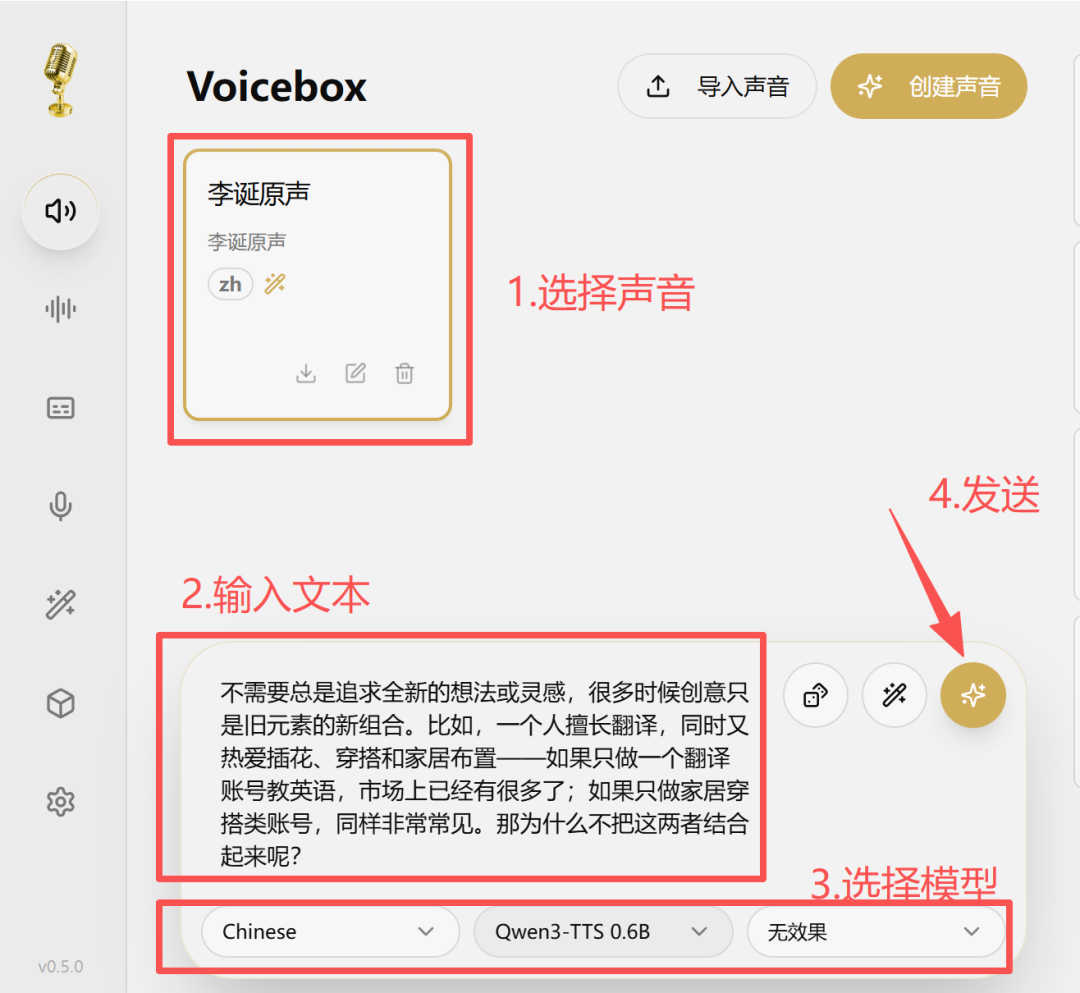
语音克隆效果在音色、语调、语速等方面表现都不错。
与 Agent 结合使用
Voicebox 与 Agent 结合有很多实用场景:
- 视频配音/播客内容:用 OpenClaw 生成内容,Voicebox 生成语音
- Agent 语音对话:本地部署 Voicebox,让 OpenClaw 调用接口把文本转成语音
Voicebox 提供全面的 HTTP API,可以部署为服务端供 Agent 使用。

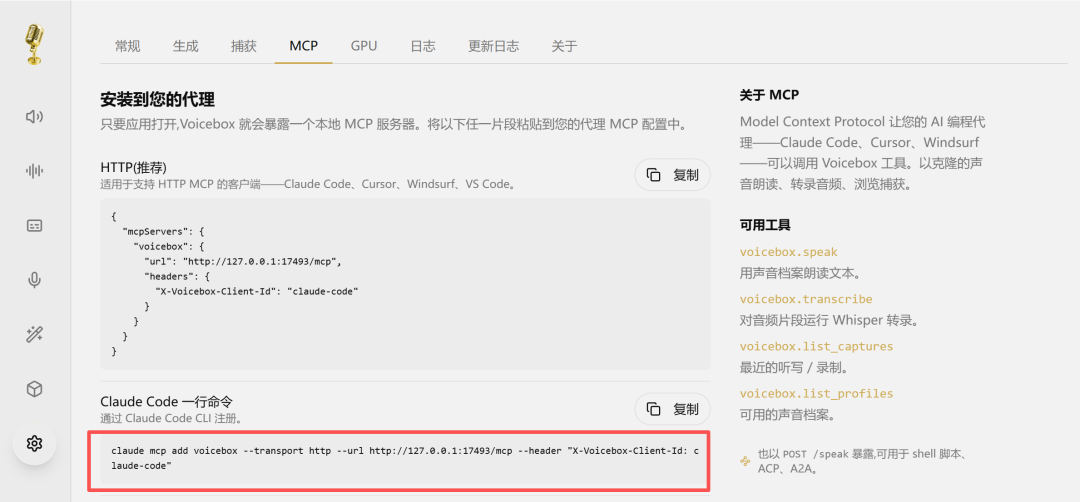
除了 RESTful 接口,Voicebox 还支持 MCP 协议,Claude Code 直接一句命令即可使用本地 Voicebox。
总结
Voicebox 是一款以本地为核心的语音转化工具:
- 不消耗 Token:模型运行在本地,可以无限使用
- 隐私性好:数据内容在本地,不外发
- 模型丰富:支持 7 种开源 TTS 模型
- Agent 友好:提供 RESTful API 和 MCP 接口
如果你需要做视频配音、播客内容,或者想让 Agent 具备语音能力,Voicebox 值得试试。
官网: https://voicebox.sh/
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。
未经允许不得转载:Voicebox:开源声音克隆工具,本地运行不耗Token,支持多国语言