高音质、情绪表达和精确时长控制的模型,其实非常罕见。
最近,B站语音团队推出了一个让我眼前一亮的新项目:IndexTTS2。这是他们在早期 IndexTTS 的基础上做的全面升级,主打三个核心亮点:
-
零样本语音与情绪克隆
-
精准的时长控制
-
影视级的音质表现
换句话说,IndexTTS2 不只是“声音合成”,而是走向了真正的可控配音生成工具,尤其适配影视、游戏、播客等高要求场景。
项目介绍
IndexTTS2 是一款基于自回归架构的文本转语音(TTS)模型。
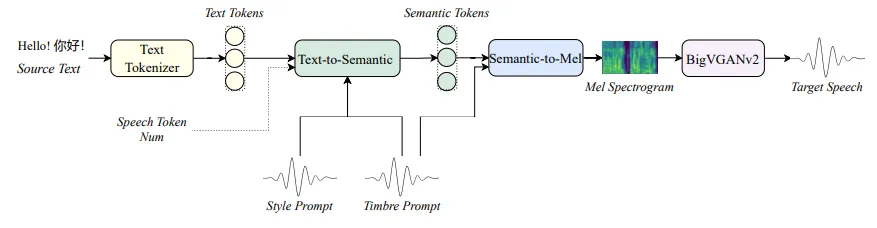
相较于市面上的主流 TTS 工具,它首次解决了两个难题:
-
情绪与音色的独立建模:可以把“声音是谁”和“声音带什么情绪”分开处理;
-
时长精确可控:不仅能合成自然语音,还能严格卡时间轴,非常适合电影或动画配音。
模型支持 中英文双语,并且能够在本地运行,未来还会开放模型权重,方便开发者在离线环境下使用。
核心功能
零样本语音克隆:只需一段参考语音,就能模仿声线、语调和节奏;
https://index-tts.github.io/index-tts2.github.io/ex6/Let_the_Bullets_Fly_1.mp4
零样本情绪克隆:可选第二段情绪语音(愤怒、低语、恐惧等),做到“声线+情绪”双克隆,这是全球首次实现;
https://index-tts.github.io/index-tts2.github.io/ex6/Empresses_in_the_Palace_1.mp4
文本情绪控制:如果没有情绪语音,可以直接在文本中指定(如“愤怒地说”);
https://index-tts.github.io/index-tts2.github.io/ex6/Empresses_in_the_Palace_2.mp4
精准时长控制:输出语音的时长完全可设定,保证和视频画面同步;
本地运行:未来将提供权重下载,支持离线部署,适合对隐私敏感的应用;
影视级音质:采用 BigVGAN2 解码器,提升清晰度与自然度。
技术细节
-
输入处理:支持中文字符+拼音建模,解决多音字问题;
-
语音编码:Conformer 条件编码器增强音色克隆稳定性;
-
情绪控制:基于 Qwen3 微调,支持文本情绪指令,结合 GPT 潜在表示增强情绪细腻度;
-
时长控制:支持指定生成帧数(精确配音)或自由生成(自然语速);
-
解码器:BigVGAN2 替换 XTTS 解码器,优化音质表现。
应用场景
-
影视/动画配音:卡时间轴,带情绪,更像“真人演员”;
-
游戏角色语音:快速克隆角色声线,支持不同情绪语气;
-
播客、有声书:长音频生成,保持自然和情感流畅;
-
AI 数字人/虚拟助手:支持离线运行,兼顾隐私和拟人感;
-
政府/企业内部应用:敏感数据环境中的本地化语音生成。
安装与部署
目前 IndexTTS2 的代码和模型权重还没有完全开放,官方只发布了 技术细节、Demo 演示和对比实验。
也可以体验之前苏米分享的TTS系列一键包:https://pan.quark.cn/s/f5d174155f6e (里面有包含了 IndexTTS1)
相似/对比项目推荐
如果你等不及 IndexTTS2 的正式开放,也可以先体验一些相似的开源/商用项目:
-
XTTS (Coqui.ai):支持多语种的零样本语音克隆;
-
F5-TTS:专注于快速推理和跨语言语音克隆;
-
MaskGCT:多语言 TTS,表现不错但缺乏情绪与时长控制;
-
ElevenLabs TTS(商用):音质接近影视级,但本地化与时长控制不如 IndexTTS2。
总结
从我个人的体验和理解来看,IndexTTS2 已经把 TTS 从“能听”推向了“能演”。它不只是把文字读出来,而是能带着真实的情绪、合适的节奏,甚至精准卡点到秒。对于影视、游戏、播客创作者来说,这几乎等于多了一个“随时待命的配音演员”。
目前官方还没有放出完整的开源版本,但从技术细节来看,它极有潜力成为未来 TTS 领域的一个重要里程碑。对开发者和创作者而言,这绝对是一个值得持续关注的项目。
项目地址:https://index-tts.github.io/index-tts2.github.io/
相关论文: