视频创作中,最耗时的往往不是脚本撰写和录制,而是后期剪辑。打开剪辑软件,一帧帧剪掉"呃"、"嗯"等语气词片段,配字幕、加动效,手动打点、反复试听,一段几分钟的视频可能需要数小时剪辑。
最近 GitHub 上开源了一个名为 video-use 的 Claude Code Skill,让 AI 自动完成视频剪辑流程。
项目背景
video-use 来自 Browser Use 团队,他们之前开源的 browser-use 项目让 AI 自动操控浏览器,已收获 8.8 万 Star。这次他们将 AI 操控浏览器的思路应用到视频编辑领域,制作成 Claude Code Skill。
安装后无需打开任何剪辑软件,只需将视频素材放入指定文件夹,然后用自然语言告诉 Claude Code 需求即可。
核心功能
只需一句"把 xxx 文件夹里的视频素材剪辑成一条可发布的视频",video-use 就能:
- 自动盘点素材并给出剪辑方案
- 识别并剪掉口头禅、语气词片段
- 对每段素材进行色彩调级
- 每个剪切点自动添加 30 毫秒音频淡入淡出
- 自动生成并添加字幕
- 输出剪辑完成的视频到素材目录旁的文件夹
技术架构:双层处理策略
video-use 的核心创新在于其底层实现逻辑。传统多模态模型处理视频时,通常将视频拆分成帧逐帧识别,一条视频轻松消耗数千万 Token。
video-use 采用双层架构,大幅降低 Token 消耗:
第一层:音频层(常驻加载)
通过 ElevenLabs Scribe 转写,生成带词级时间戳的文字稿,同时标注说话人、笑声、叹息等信息。词级时间戳是剪辑精度的关键,其他主流转写工具通常只提供句级时间戳或不区分说话人。
第二层:视觉层(按需调用)
遇到模糊停顿、重录比对、剪辑点确认等关键决策时,timeline_view 会现场合成一张图片供 LLM 参考,包含胶片缩略图、音频波形、单词标签等叠加信息。
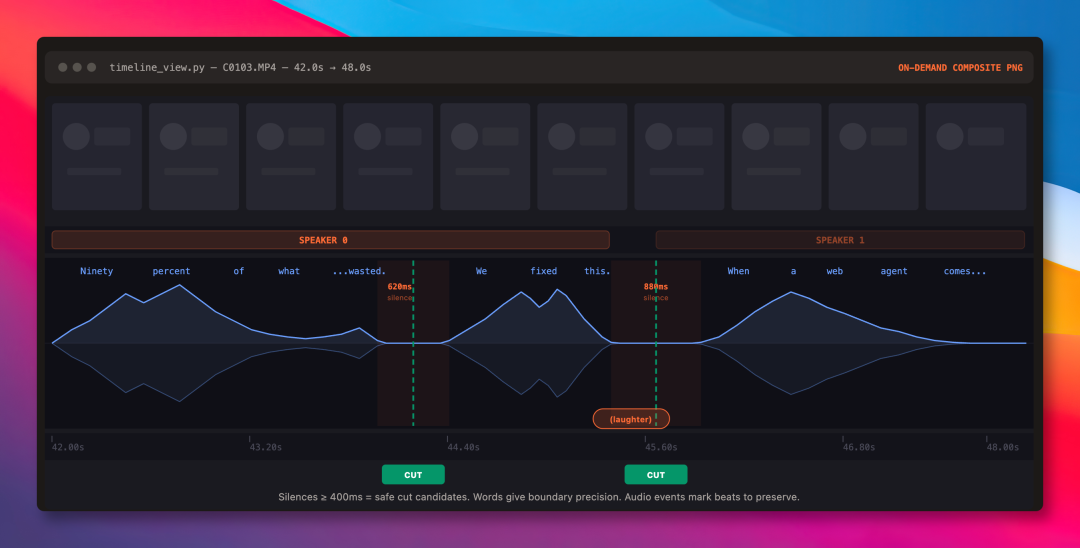
这个思路与 browser-use 项目一脉相承——用结构化数据替代原始图像输入,大幅降低 Token 消耗并提升处理效率。
自检与迭代机制
渲染完成后,工具会在每个剪切点进行自检,扫描画面跳切、爆音、字幕遮挡等问题。发现问题自动回炉重新渲染,最多重试 3 次,通过后才提交预览。
整个流程为:转录 → 打包 → 模型推理 → 生成剪辑决策 → 渲染 → 自检。每一步策略都需要用户确认才执行,确保剪辑过程可控。
项目上下文管理
每次剪辑的上下文会写入 project.md 文件。对于课程、长播客、连载 vlog 等连续性项目,video-use 能从上次的状态继续,无需重复说明背景信息。
安装与使用
安装流程简单:
# 克隆项目到本地
git clone https://github.com/browser-use/video-use
cd video-use
# 链接到 Claude Code 的 skills 目录
ln -s "$(pwd)" ~/.claude/skills/video-use
# 安装依赖(ffmpeg 必装,yt-dlp 可选)
pip install -e .
brew install ffmpeg
brew install yt-dlp
# 配置 ElevenLabs API Key 到.env 文件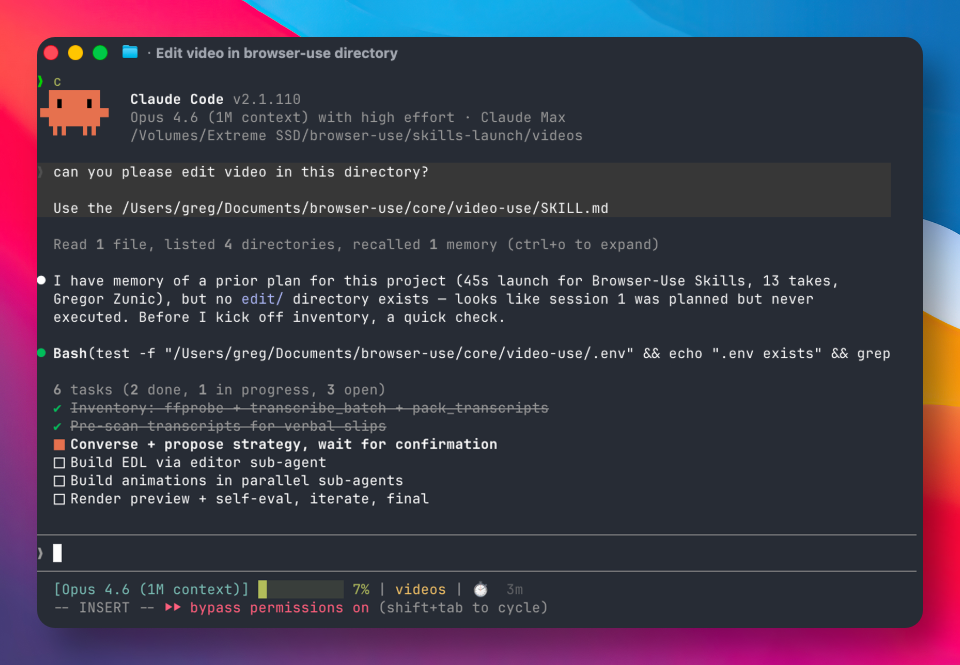
目前项目处于早期阶段,复杂场景可能需要多轮对话才能达到预期效果。描述越具体,结果越准确。
苏米注
video-use 的真正价值不在于功能本身,而在于其方法论的复用性。browser-use 将 LLM 从"看网页截图"换成"读结构化 DOM",video-use 将"看视频帧"换成"读带时间戳的转录文本"。
这种思路的核心是:用结构化、低 Token 消耗的数据表示替代原始高维输入。随着 Opus 4.7 等模型学会自我验证,AI Agent 正从"协助完成某一步"向"独立交付完整成果"演进。
未来创作者可以把更多精力留给创意本身,而非重复、琐碎的执行环节。