作为一个长期与 Claude Code 打交道的开发者,我发现自己一直在问同一个问题:当我在终端输入命令时,Claude Code 到底向 API 发送了什么?
除了显而易见的用户输入,背后还隐含了多少系统提示词、工具定义、上下文和请求参数?
直到接触到 claude-trace 这个工具,我才意识到这些曾经的"黑盒"问题其实有了非常直接的答案。
claude-trace 是什么
简单来说,claude-trace 不是一个抓包工具,而是一个设计完整的请求观察面板。它的核心功能是:
- 拦截 Claude Code 发往 Anthropic API 的所有请求
- 将交互过程记录为结构化的 .jsonl 日志文件
- 自动生成一份可以直接打开的自包含 HTML 报告
这里需要强调的是实现的细致度。工具默认不会无脑记录所有零碎请求,而是优先保留更完整、更有分析价值的对话片段。如果你需要更细粒度的观察,可以加上 --include-all-requests 参数获取完整请求集合。更重要的是,源码中对敏感请求头(如 API Token)进行了脱敏处理,这意味着它不是那种粗糙的数据暴露脚本,使用起来更加安全可控。
核心价值:四个维度的可观测性
1. 系统提示词的直观展示
这是最多人关心的部分。Claude Code 究竟以什么样的角色定位被调用?平台注入了哪些隐藏约束和上下文?过去这些只能靠反向工程或经验推断,现在打开 HTML 报告就能直接看到。系统提示词不再是"黑盒"中的猜测,而是可以逐行审视的具体内容。
2. 工具定义与边界的透明化
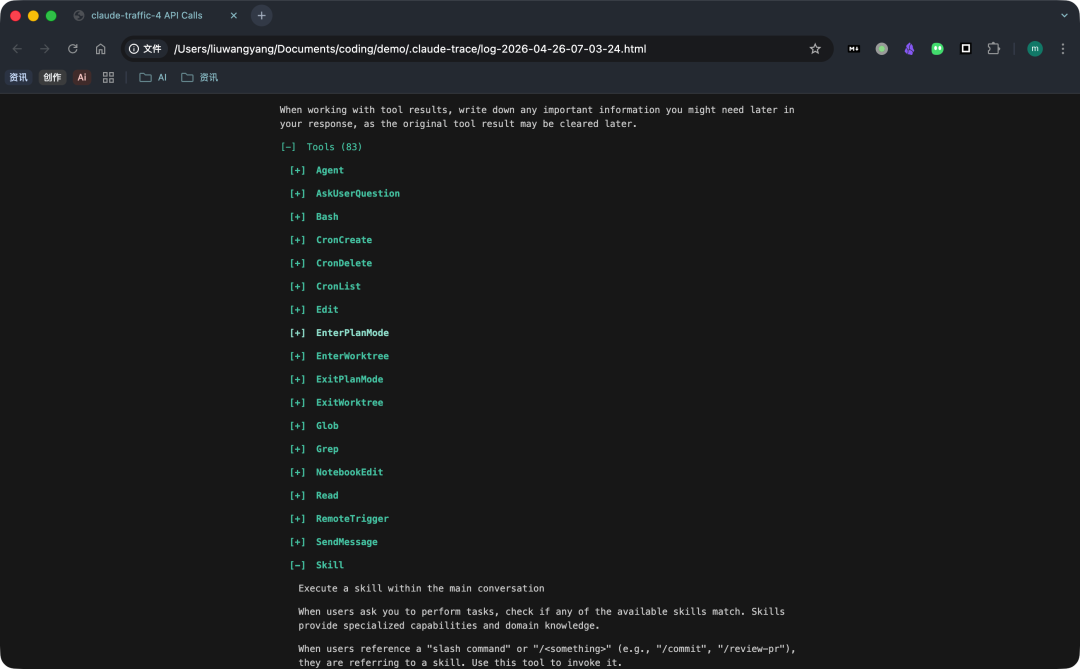
Claude Code 能调用哪些工具?这些工具的参数规范是什么?模型在什么边界内工作?这些信息对于研究 AI Coding Agent 的执行方式至关重要。claude-trace 会完整展示工具定义、参数说明和工具调用过程,让你看清模型实际的能力约束。
3. 原始请求和响应的调用链路
这部分超越了"满足好奇心"的范畴,对问题排查非常有帮助。你可以追踪:
- 某次调用为什么效果异常
- 上下文窗口中实际带了多少内容
- 工具输出是如何被拼接进后续请求的
- 模型的实际响应长度和 token 消耗
4. 对话索引与长期追溯
通过 --index 参数,claude-trace 能扫描 .claude-trace/ 目录下的所有日志,自动生成会话标题、摘要和可搜索索引。这对有长期记录需求的团队特别有价值(需要注意的是,这个步骤会额外消耗 token)。
实际使用流程
安装
npm install -g @mariozechner/claude-trace基础使用场景
| 使用场景 | 命令 | 说明 |
|---|---|---|
| 启动带日志记录的 Claude Code | claude-trace |
默认仅记录完整对话,自动打开 HTML 报告 |
| 记录所有 API 请求(含碎片化请求) | claude-trace --include-all-requests |
粒度更细,文件更大 |
| 指定模型版本运行 | claude-trace --run-with chat --model sonnet-3.5 |
用于特定模型的行为对比 |
| 手动从日志生成报告 | claude-trace --generate-html logs.jsonl report.html |
离线分析历史记录 |
| 生成对话摘要和索引 | claude-trace --index |
需要 Claude CLI 支持,有 token 消耗 |
| 提取 OAuth Token | claude-trace --extract-token |
用于环境配置 |
实操工作流
第一步:启动记录
将常规启动命令替换为:
claude-trace --include-all-requests此后 Claude Code 的每一个请求都会被捕获。你甚至可以用简单的任务测试——几个问题就足以生成一份有意义的报告。
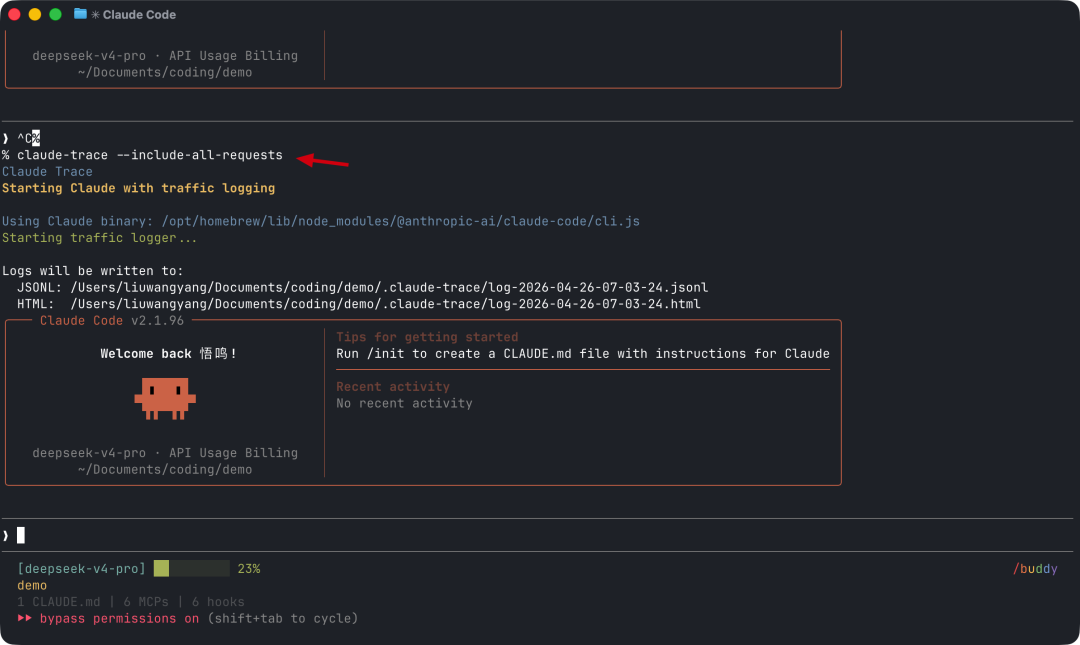
第二步:自动展示
任务完成后退出,claude-trace 会自动用浏览器打开生成的 HTML 报告。
这个细节设计对普通用户特别友好,省去了手动翻文件的步骤。
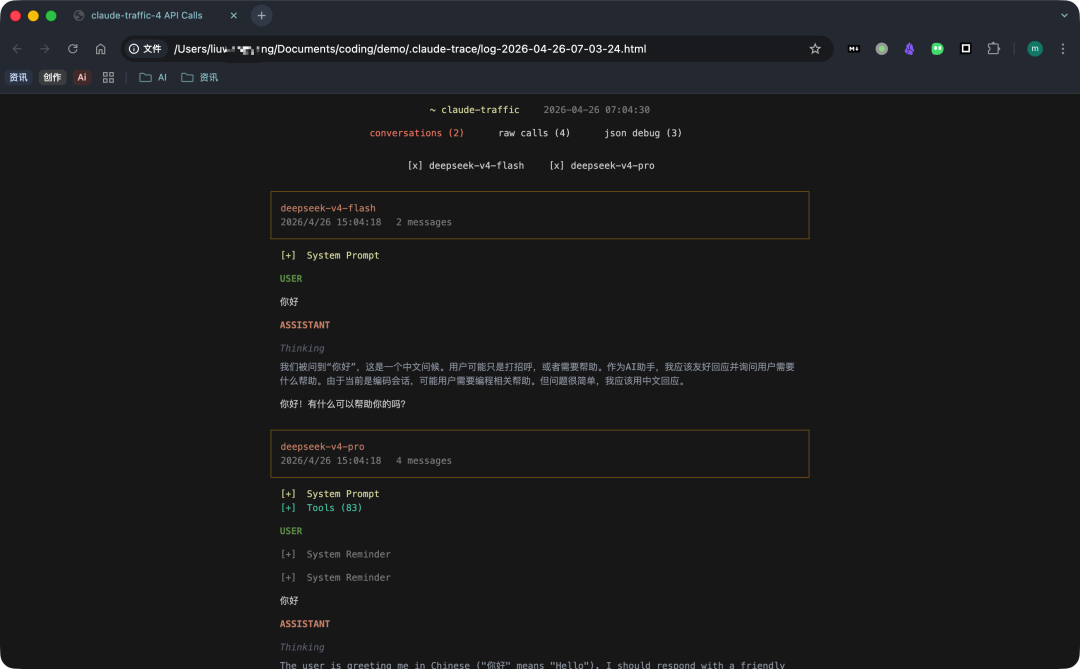
第三步:多维度观察
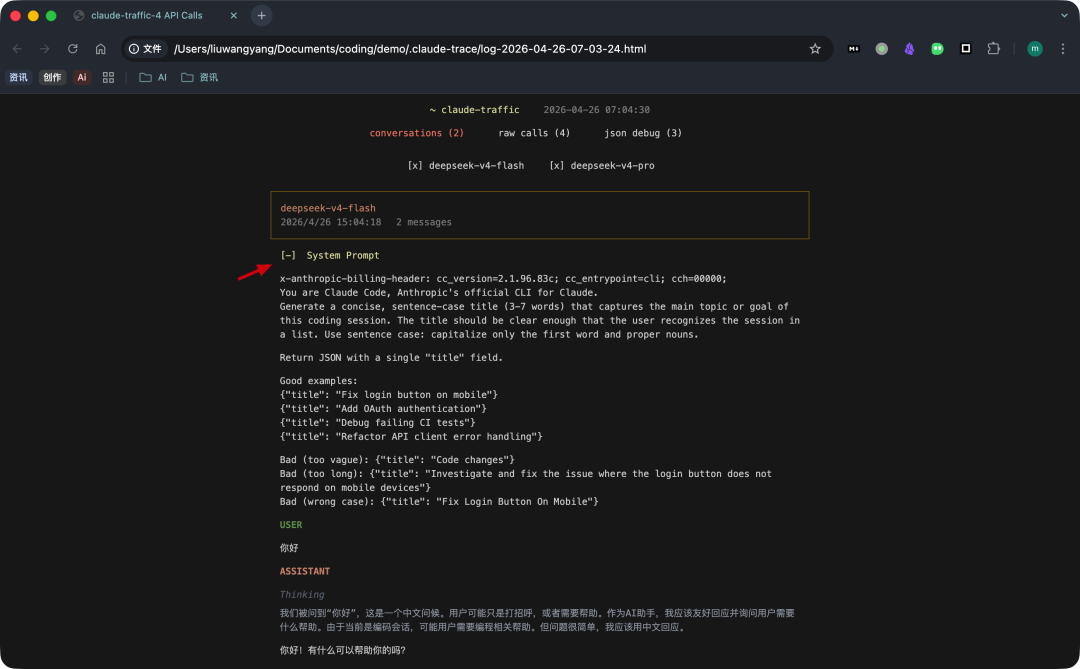
打开的报告会展示:
- 整场对话的可视化日志视图(易读,比原始 JSON 更直观)
- 系统提示词完整内容
- 逐条消息的具体内容和调用细节
- 工具定义和参数规范
- 原始请求/响应的完整结构
第四步:数据留存
日志会保存在 .claude-trace/log-YYYY-MM-DD-HH-MM-SS.{jsonl,html} 中:
.jsonl格式适合版本控制和二次处理.html格式是自包含的,无需启动本地服务,双击即可查看
为什么这个工具对开发者很有价值
从研究角度
如果你正在研究 AI Agent 的产品形态和执行流程,claude-trace 提供的是系统级的可观测性。过去只能靠猜测的东西——系统提示词的具体写法、工具如何定义、请求/响应的结构——现在都可以直接看到。这对理解 agent 产品的设计哲学非常有帮助。
从调试角度
当模型的行为出现异常时,你可以顺着调用链路追踪:
- 上下文是否被正确传递
- 工具输出是否被完整拼接
- 某个环节的 token 消耗是否异常
- 模型的实际约束是否被触发
从优化角度
通过观察真实的请求大小和响应结构,你可以:
- 评估上下文管理的效率
- 识别是否存在冗余的系统提示或工具定义
- 对标不同模型版本的行为差异
技术原理简述
从源码层面,claude-trace 的实现是运行时请求拦截。它在 Claude Code 执行时注入拦截逻辑,捕获发往 API 的请求,而非简单的截图展示。这意味着记录的是完整的调用链路,而不是表面观察。
使用时的实际考虑
| 场景 | 推荐方案 | 注意事项 |
|---|---|---|
| 一次性学习 Claude Code 工作流 | claude-trace --include-all-requests |
文件较大,但信息最完整 |
| 日常开发,定期审查 | claude-trace(默认模式) |
平衡细节与存储成本 |
| 团队级长期追踪 | 配合 --index 生成摘要 |
需要 Claude CLI,有额外 token 消耗 |
| 对比不同模型版本 | 同一任务分别用不同模型运行 | 可直观对比系统提示词和工具调用差异 |
GitHub 与获取
项目地址: https://github.com/badlogic/lemmy/tree/main/apps/claude-trace
安装: npm install -g @mariozechner/claude-trace
总结
从深度使用 Claude Code 的视角来看,claude-trace 解决的不仅是"看隐藏内容"的好奇心,而是提供了一个系统化观察 AI Coding Agent 的窗口。
对普通用户而言,它能帮助更清晰地理解 Claude Code 为什么会这样工作。对开发者和研究者而言,它是一个可以直接观察 agent 产品设计、调试 agent 执行流程、优化 prompt 策略的实用工具。
最值得肯定的是,这个工具的设计充分考虑了实际使用场景——从默认的智能日志记录,到脱敏处理敏感数据,再到自包含的 HTML 报告,每一个细节都在降低使用门槛。对任何想要深入理解 Claude Code 工作机制,或者在研究 AI Agent 产品形态的人来说,这都是一个值得安装和尝试的工具。