作为一名长期在一线负责需求梳理、跨团队协作和输出落地的产品经理,我最怕两件事:一句话说不清、一件事做不稳。
近期在内容产品的时候我测试了多模型对比,这两个问题被 AI 放大了:同一个任务,GPT 表现不错,换Claude 就是不对劲,放 Gemini 又像在另一个星球;
到了 O3、O4 mini 这种推理模型,官方还提醒你别用传统提示词技巧,更是让人抓耳挠腮。
现在用AI干活感受是:上下文工程再强,提示词工程也不会消失。
它们不在一个层级,上下文是数据基础设施,而提示词是沟通协议。
模型越来越聪明,反而更需要我们更准确地表达。
我把提示词当成产品,不是魔法,而是工程化的规范。
下面这套我测试了上千遍通用提示词工程框架,是我在多个模型、多个业务场景里反复测试出的稳定方法:一套提示词,跨平台可适配,输出来得稳、改起来不痛苦。
提示词工程是沟通协议,不是咒语
总有人喜欢把一段提示词说成是「咒语」,而我把提示词写成一个结构化协议。
协议的优势有三点:
信息可维护:像 PRD 一样拆分组件,谁改什么一目了然。
跨模型迁移容易:同一「信息结构」换不同「适配参数」。
质量可度量:每个组件都能对应输出指标,支持 A/B 迭代。
更重要的是,它让你从「会用某个模型的土法」升级为「会搭一个跨模型的工作流」。
像写 PRD 一样写提示词
我把提示词拆成七个组件,并分为三层:
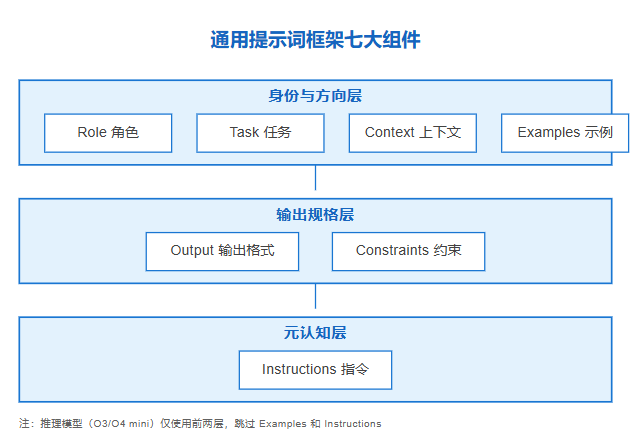
身份与方向层
Role(角色):模型是谁、为谁服务、该怎么说。尽量具体,例如「面向非技术团队的高级技术写作工程师」,比「技术写作工程师」更能暗示思维方式和受众。
Task(任务):用动词开头,拆成 2–4 个子目标。不是让模型按步骤执行,而是给它明确的思考路径。
Context(上下文):把所有必需资料集中在一个地方,尽量不要让模型去猜。单一信息源比模糊先验更稳。
输出规格层
Examples(示例):少样本学习的利器,给 2–3 个高质量案例,输出一致性会显著提升。对格式化、代码、文档尤其有效。
Output(输出格式):规格要具体,「三列 Markdown 表格」比「一个表格」有效得多。字数、结构、格式都写清。
Constraints(约束):风格、内容边界、安全护栏。约束不是削弱创造力,而是减少不确定性。
元认知层
Instructions(指令):对思维过程的引导,例如「先规划再输出」「信息不确定时请说明」。它直接影响幻觉率和可靠性。
我习惯用简单的标签封装这些组件(类似 XML),便于维护与版本化:
你是【具体角色】,受众是【目标用户】,风格:【正式/亲切/技术性】
【动词】【主要目标】
子目标:
1. 【子任务一】
2. 【子任务二】
3. 【子任务三】
【所有必要信息、文档、数据】
输入/输出示例各 2–3 个
- 【风格约束】 - 【内容限制】 - 【安全/质量标准】
1. 先规划 2. 不确定则说明 3. 按请求格式输出模型差异化
统一框架不等于一个模板走天下。不同模型对组件的敏感度差异很大。
我的做法是设一组「适配拨盘」,按模型类型调权重。
GPT-4/5:上下文能力强,角色持久
Role 可以详细,长对话能保持身份。
Task 不必太啰嗦,隐含意图也能读懂。
Examples、Instructions 能提升一致性与可解释性。
O3 / O4 mini 等推理模型:简约主义
跳过 Examples,过多示例会干扰内置推理。
Instructions 只说「做什么」,不讲「怎么做」。移除思维链类提示。
Context 只保留必需信息,精简到骨。
Claude 3.5/4:正向表达更有效
角色要具体到场景与受众,提升明显。
少用「不要做 X」,多用「请做 Y」的正向约束。
Gemini:多模态友好,清晰分解更稳
把图片、表格、图表直接塞进 Context,能被很好地整合。
明确子目标列表,它会逐项系统处理。
Perplexity:检索增强,先让「能搜到」
Context 用关键词密集的描述,搜索友好。
跳过 Examples,避免检索层被示例误导。
Instructions 里明确时间范围与检索边界。
这些差异的底层逻辑是什么?本质上是模型架构与训练目标的不同。标准语言模型追求上下文连贯性,推理模型优化逻辑推导过程,检索增强模型侧重信息召回精度。框架的七个组件是通用的,但各组件的"权重"需要根据模型类型动态调整。

高级技术
在掌握基础框架后,两个高级技术能将输出质量推向新高度。
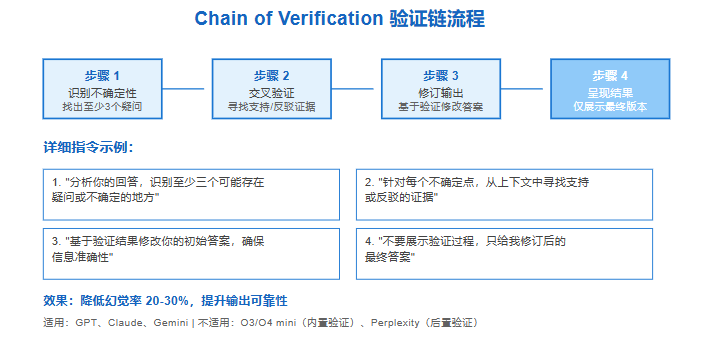
验证链(Chain of Verification)
- 识别不确定点(至少 3 个)。
- 用上下文交叉验证(找支持或反驳证据)。
- 据验证结果修订初稿。
- 只呈现修订后的最终版本。
这套流程对 GPT、Claude、Gemini 很有效,能显著降低幻觉率。
注意:对 O3/O4 mini、DeepSeek 等推理模型慎用,它们已有内部验证,外置验证链可能造成重复计算;
对 Perplexity 采用「后置验证」,先拿初答,再用新提示触发验证,避免干扰检索。
反向提示(Reverse Prompting)
让 AI 设计最优提示词,思路是把提示词设计权交给模型:你描述目标,让模型按最佳实践产出「最优提示词」,再用该提示词执行或由你审查后执行。
它有效的原因很简单,模型知道自己偏好什么样的输入结构。
实际体验里,竞品分析、技术写作、数据说明书这类任务,反向提示能补齐我们容易遗漏的维度、格式与约束。
实战案例:一位产品经理需要分析竞品功能,直接写提示词可能遗漏关键要素。使用反向提示后,GPT-4 生成的提示词包含了详细的对比维度(功能完整度、用户体验、技术架构、定价策略)、输出格式(对比表格+评分矩阵)、约束条件(基于公开信息、避免主观臆断)——这些都是人类可能忽略的细节。
从方法到工作流实战指南
将框架从理论转化为可执行的工作流,需要系统化的实施路径。
初始化模板与配置
建立基础模板(如上标签结构),再为模型创建适配配置:
创建一个基础模板文件(prompt_template.txt),内容如下:
你是【具体角色】专家,
你的受众是【目标用户】,
沟通风格:【正式/亲切/技术性】
【动作动词】【主要目标】
子目标:
1. 【子任务一】
2. 【子任务二】
3. 【子任务三】
【提供所有相关信息、文档、数据】
示例 1:
输入:【示例输入】
输出:【期望输出】
示例 2:
...
- 【风格约束】
- 【内容限制】
- 【质量标准】
1. 逐步思考你的方法
2. 如果信息不确定,明确说明
3. 以请求格式提供最终答案
这个模板是模型无关的——你可以直接用于任何 AI 平台。
根据目标模型调整模板。创建一个配置文件(model_config.yaml):
GPT-4:
context_max: 128000 # 充分利用上下文窗口
examples_count: 3-5 # 推荐示例数量
instructions: "详细" # 可以使用思维链(CoT)
O3-mini:
context_max: 16000 # 精简上下文
examples_count: 0 # 不使用示例
instructions: "简洁" # 移除思维链(CoT)
Claude-4:
role_emphasis: "高" # 强化角色定义
constraint_style: "正向" # 使用"做什么"而非"不做什么"
Perplexity:
context_style: "关键词" # 搜索友好
examples_count: 0 # 跳过示例
instructions: "包含时间范围" # 明确搜索边界真实场景验证
以"生成技术文档"任务为例,完整流程如下:
你是资深技术文档工程师,
你的受众是初级开发者,
沟通风格:清晰、结构化、避免行话
创建接口(API)端点的技术文档
子目标:
1. 解释端点的功能和用途
2. 列出所有参数及其类型
3. 提供请求和响应示例
4. 说明常见错误及解决方案
端点:POST /api/v2/users
功能:创建新用户账户
参数:username(字符串), email(字符串), role(枚举类型:admin/user)
认证:需要承载令牌(Bearer Token)
- 每个参数必须包含类型和是否必需
- 示例代码使用 curl 和 Python
- 错误码必须包含 HTTP 状态和错误消息
1. 先规划文档结构
2. 确保所有参数都有明确说明
3. 示例代码必须可直接运行
如果使用 O3-mini,调整为:
技术文档工程师,受众:初级开发者
创建 /api/v2/users 端点的完整文档,包含参数、示例、错误处理
POST /api/v2/users - 创建用户
参数:username(字符串), email(字符串), role(admin/user)
认证:承载令牌(Bearer Token)
- 参数说明必须包含类型和必需性
- 示例使用 curl 和 Python
注意:移除了示例(Examples)组件和详细的指令(Instructions)组件。
迭代与质检
运行提示词后,检查三个关键指标:
完整性:是否覆盖了所有子目标?
格式一致性:输出是否符合输出格式(Output)定义?
质量:是否满足约束(Constraints)的要求?
如果输出不理想,不要立即修改整个提示词,而是单点优化:
-
输出格式错误 → 调整 的具体性 -
内容遗漏 → 细化 的子目标 -
语气不符 → 强化 的描述
别一上来重写提示词,先做「单点微调」:格式问题→改 Output 的具体性;内容遗漏→细化 Task 的子目标;语气不符→强化 Role 的风格说明。每次改动只动一个组件,便于归因与复盘。
把提示词库当版本化来优化
这部分是我做 PM 的「职业病」,但确实管用:
- 版本管理:提示词按组件拆分版本,记录适配参数与输出指标;上线新模型时只改配置。
- 评测与 A/B:定义任务级 KPI(覆盖率、错误率、格式一致性、验证成功率),每次迭代做对照实验。
- 权限与合规:在 Constraints 中固化红线(隐私、敏感内容、合规措辞),把风险前置到协议里。
- 知识回流:把好的 Context 做成可复用片段(RAG 索引、内部知识库),减少重复供料。
- 团队习惯:把「先框架后输出、先验证后发布」写进流程,变成组织的「肌肉记忆」。
提示词工程 vs 上下文工程
2025 年技术圈出现一个误导性的说法:"上下文工程(Context Engineering)会取代提示词工程(Prompt Engineering)"。这就像说"自动驾驶会让学驾照变得没用"——表面有道理,实际是混淆了层次。
上下文工程是导航系统,提示词工程是驾驶技能。
导航再好,指令不清也会「迷路」。常见误区是以为「数据多」自然等于「理解好」。
事实恰恰相反:AI 拿到更多上下文后,反而更需要你明确提取维度、分析方法与交付规格,否则会在信息海里失速。
我的原则是:上下文工程解决「知道什么」,提示词工程解决「要做什么、怎么交付」。两者一起,才是可落地的生产力。
结语
跨平台 AI 应用的核心挑战不是掌握每个模型的独特技巧,而是建立统一的思维框架。
这套七组件协议的价值,是把不同模型共同需要的信息结构抽象出来,再用适配拨盘去调权重。
对 GPT、Claude、Gemini 用完整框架并善用示例;对 O3/O4 mini 精简到角色、任务、输出;对 Perplexity 优化上下文的搜索友好性。
验证链能显著降低幻觉,反向提示能借力模型的「自知之明」。
从今天起,把提示词当产品规格,把提示词库当组织资产。
下一个模型发布时,你不需要重学一门方言,只要调整几颗拨盘。
产品经理最重要的能力,是把不确定性变成可控的流程,提示词工程也应如此。
参考资料
OpenAI 平台文档 - 提示词工程指南(Prompt Engineering Guide)(https://platform.openai.com/docs/guides/prompt-engineering) Anthropic Claude 文档 - 提示词设计(Prompt Design)(https://docs.anthropic.com/claude/docs/prompt-design) Google AI 开发者文档 - Gemini 提示词指南(Gemini Prompting Guide)(https://ai.google.dev/gemini-api/docs/prompting-intro) 验证链降低大语言模型幻觉(Chain-of-Verification Reduces Hallucination in Large Language Models)(https://arxiv.org/abs/2309.11495) 少样本提示可能导致推理模型性能意外下降(Few-shot Prompting May Cause Unexpected Degradation in Reasoning Models)(OpenAI 研究博客) 2025 年上下文工程的崛起(The Rise of Context Engineering in 2025)- AI 工程趋势报告