OpenAI 刚刚发布了 GPT-5.6 的 Sol、Terra、Luna 三个新模型,但对于大多数国内开发者来说,这些高端模型仍然遥不可及。不过,Hermes 团队几小时前上线了一个新方案——MoA(Mixture of Agents)混合模型模式,用"多模型协作"的思路来提升 Agent 的任务处理能力。
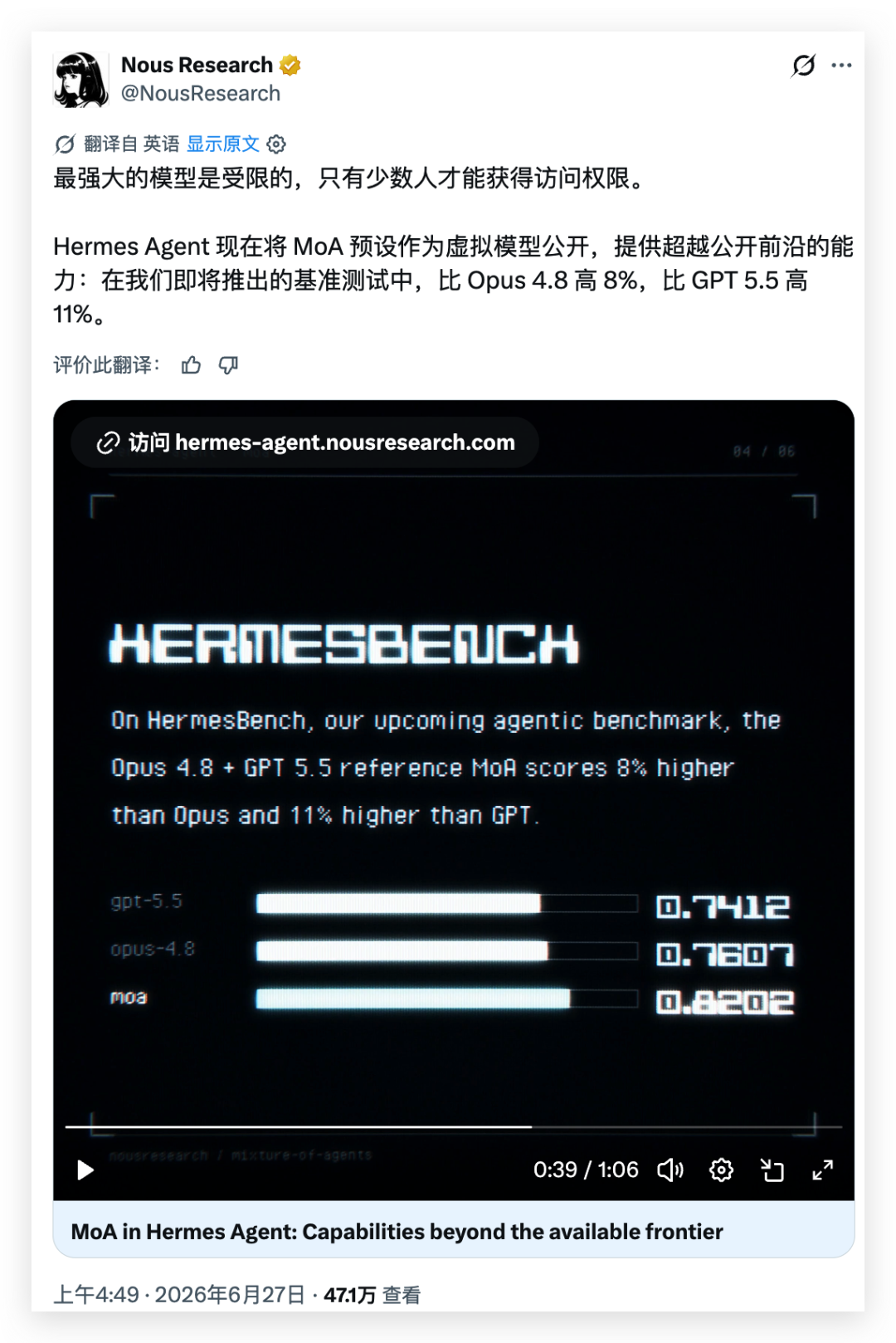
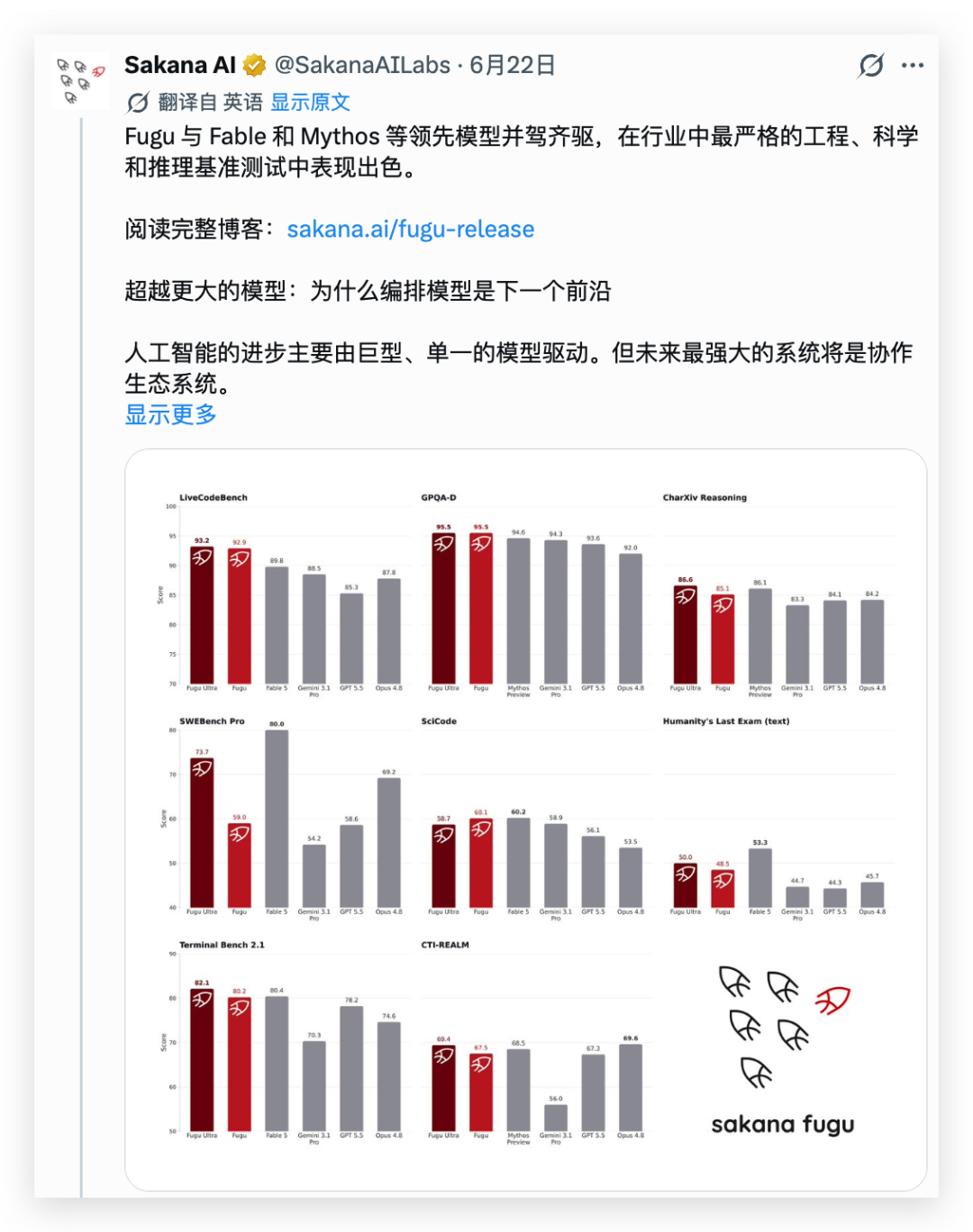
苏米注:MoA 的核心思路很直白——既然用不起最贵的模型,那就让多个中等模型群策群力,"三个臭皮匠顶个诸葛亮"。这不是 Hermes 的独创,本周日本团队发布的 Sakana Fugu 也是类似方案,用小模型调度多个不错的中等模型,号称能击败 Fable 5。Hermes 的区别在于"判官"不需要额外的小模型,而是直接使用你已经在 Hermes 中授权的任意模型。
什么是 MoA 模式
MoA(Mixture of Agents)让多个参考模型并行处理同一请求,然后将结果汇总给一个"判官"模型(Aggregator)进行最终裁决。参考模型各有所长,能够取长补短;判官模型负责整合输出,确保最终结果的质量。
配置 Hermes MoA 模式
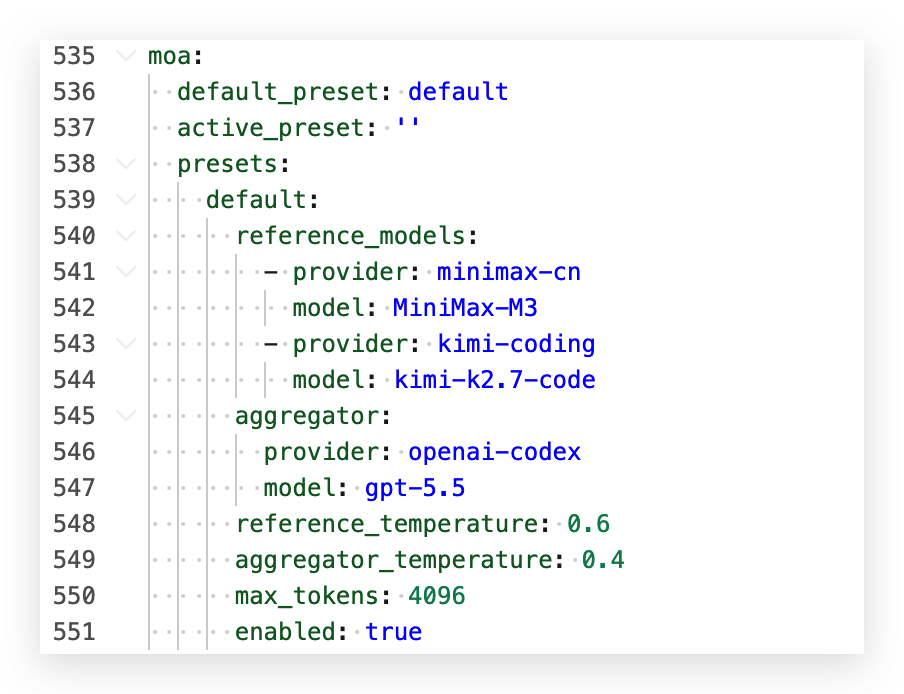
配置过程非常简单,在 Hermes 的 config.yaml 文件中按照以下格式写入(需要升级到 Hermes 最新版本):
moa:
default_preset: default
active_preset: ''
presets:
default:
reference_models:
- provider: minimax-cn
model: MiniMax-M3
- provider: kimi-coding
model: kimi-k2.7-code
aggregator:
provider: openai-codex
model: gpt-5.5
reference_temperature: 0.6
aggregator_temperature: 0.4
max_tokens: 4096
enabled: true注意事项:
- 模型名称:不要照抄示例,填写你已经完成授权/登录的模型
- 角色分配:将最强的模型设为 Aggregator(判官),其余作为 Reference(参考模型)
- 数量上限:Reference 模型最多可以设置 8 个
切换 MoA 模式
配置完成后,在 Hermes 的各种交互界面中通过 /moa 命令即可切换到 MoA 模式:
飞书上的 Hermes Agent:
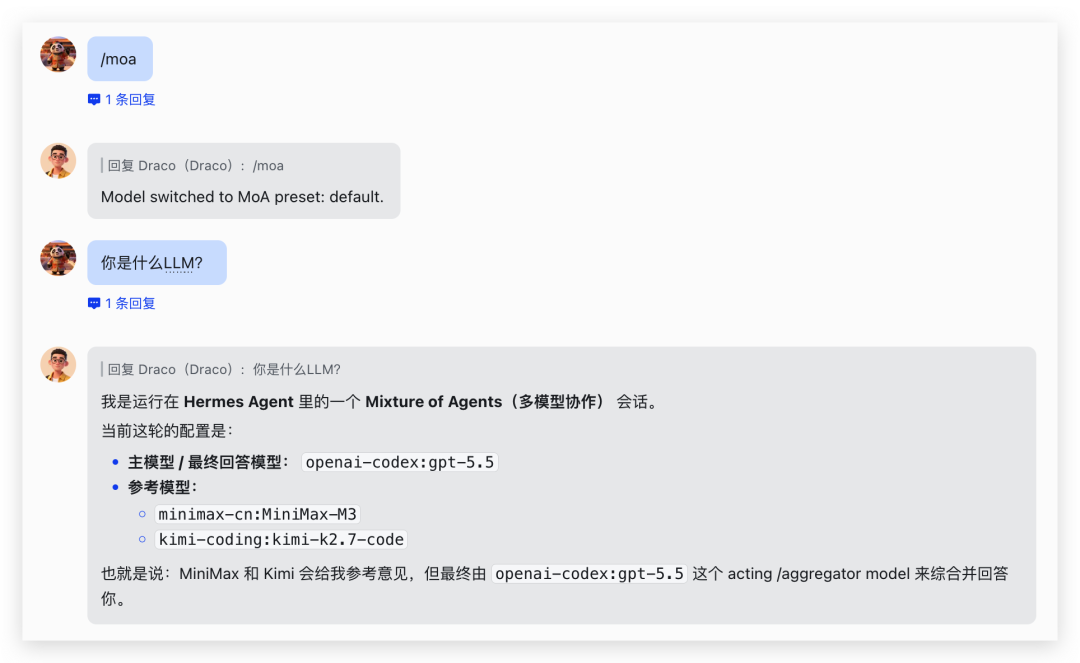
终端里的 Hermes TUI:
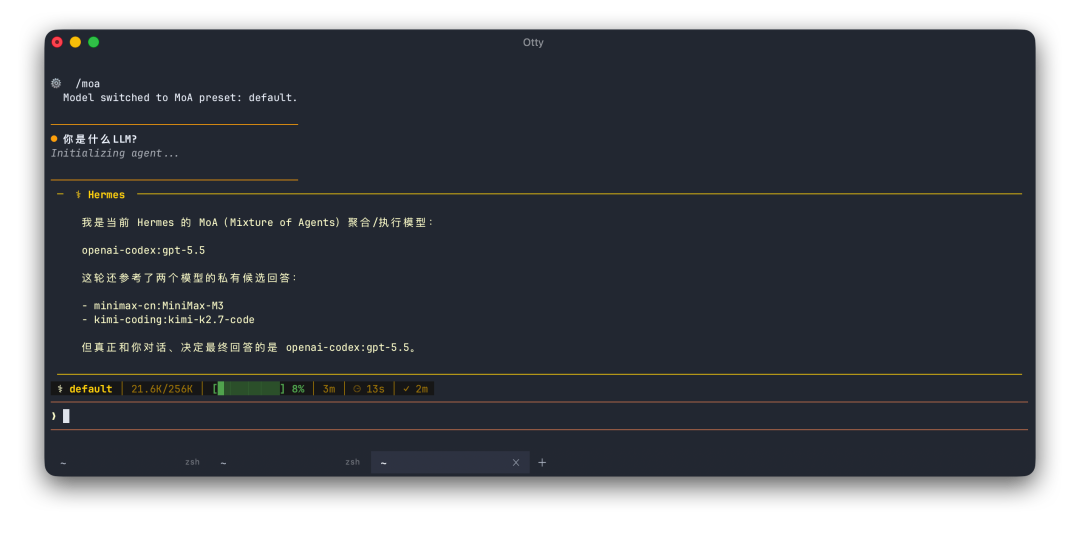
Hermes Desktop:
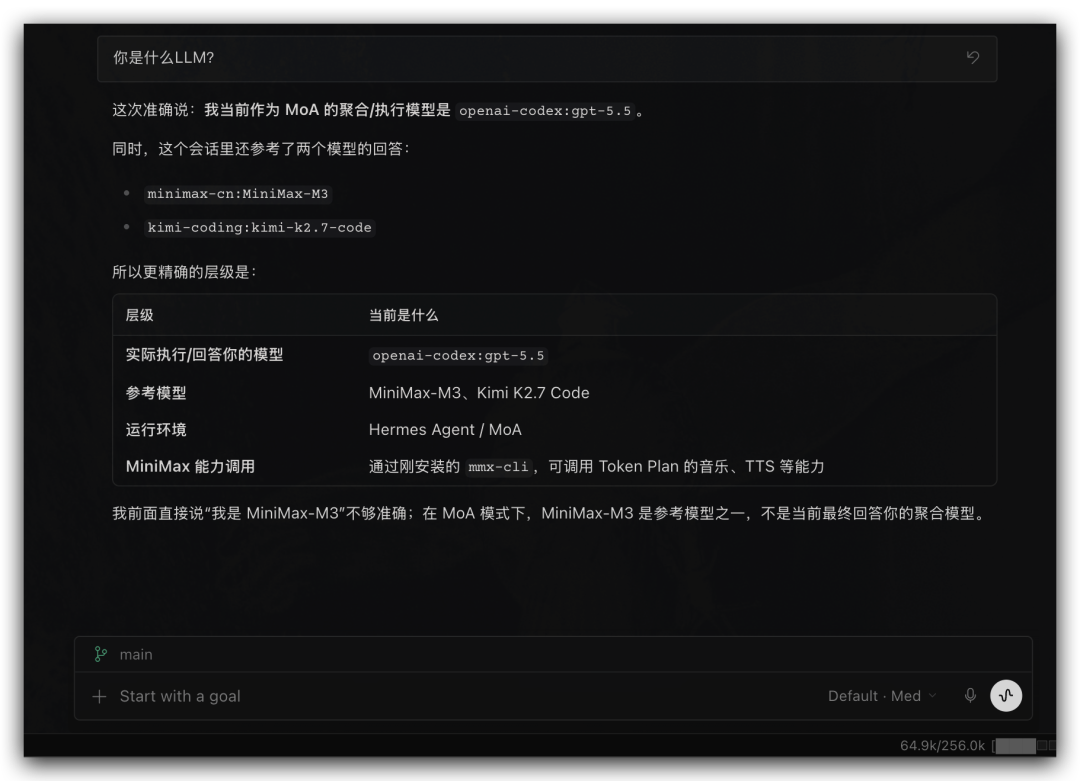
踩坑记录:在 Hermes Desktop 里切换 MoA 模式可能存在 bug,建议随时开着另一个 Agent 作为备选。如果遇到配置问题,可以把 Hermes MoA 官方文档 丢给你的 AI 助手,让它帮你排查。
优缺点分析
MoA 模式的本质是"token 换质量"——用更多的 token 消耗和更长的处理时间,换取更好的任务输出质量。
| 维度 | 说明 |
|---|---|
| 优点 | 多个参考模型各有所长,能取长补短,综合输出质量更高 |
| 缺点 | Token 消耗显著增加,响应时间也会慢不少 |
| 适用场景 | 复杂任务、长程规划、需要多角度分析的问题 |
| 不适用场景 | 简单问答、需要快速响应的场景 |
苏米观点
MoA 模式是 AI Agent 领域一个有趣的工程实践。它解决的不是"哪个模型最强"的问题,而是"如何在预算有限的情况下最大化输出质量"的问题。
对于已经订阅了多个 AI 服务(如 Kimi、MiniMax 等)的用户来说,MoA 让这些模型从"各自为战"变成了"协同作战",相当于把你手里的工具组合成了一个工作流。不过,对于预算有限或只需要处理简单任务的用户,MoA 的额外 token 消耗可能并不划算。
作者目前正在用复杂的游戏类项目测试 MoA 模式的实际效能,由于项目复杂且 MoA 耗时较长,尚需更多时间验证。后续有结果值得持续关注。