本文介绍如何从零构建一个本地AI Agent,实现真正的数据主权——记忆是本地Markdown文件,技能是文件夹中拖入即用的说明书。
为什么需要本地AI Agent?
云端AI助手像"黑盒",你不知道它记住了多少数据,也不清楚调用工具时后台流转了什么。本地AI Agent让你完全掌控数据,所有配置都是本地文本文件,透明可控。
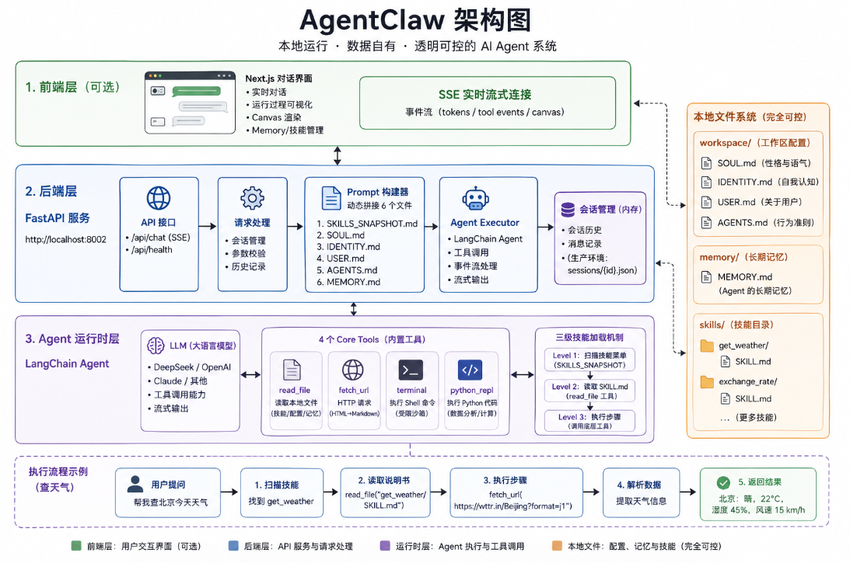
系统架构
整个系统分三层:
- 前端:Next.js对话界面(可选,没有也能用API)
- 后端:FastAPI,本地8002端口,处理请求、读写文件、推送事件
- Agent运行时:LangChain构建,处理请求、调用工具、循环执行直到给出回答
最关键的设计是System Prompt的构成方式。每次对话开始,后端将6个本地文件拼成完整System Prompt:
- SKILLS_SNAPSHOT.md — 告诉Agent"你会什么"
- SOUL.md — 性格和语气设定
- IDENTITY.md — 自我认知
- USER.md — 用户背景信息
- AGENTS.md — 行为准则,包含技能调用协议
- MEMORY.md — 长期记忆
全部是本地Markdown,随时可用编辑器修改。这就是"透明可控"的根基。
技能系统:三级加载机制
技能不是函数,是说明书。每个技能是一个文件夹,内含SKILL.md,描述"什么情况下用"、"分几步做"、"调哪个工具"。
Level 1:System Prompt中只放技能名和一句描述(约30 Token)
Level 2:Agent匹配到相关问题后,读取SKILL.md说明书
Level 3:照着说明书用底层工具执行
以查天气为例:
- 用户:"帮我查北京今天天气"
- Agent扫描SKILLS_SNAPSHOT → 找到get_weather技能
- 调用read_file("get_weather/SKILL.md")
- 读到:"用fetch_url访问https://wttr.in/Beijing?format=j1,解析JSON..."
- 调用fetch_url(url)
- 解析数据 → 返回"北京:晴,22°C,湿度45%"
想加新技能,只需建文件夹、写SKILL.md,重启服务即可,不用改后端代码。
内置工具
Agent出厂自带6个底层工具:
- read_file:读取本地文件(技能定义、工作区配置、记忆文件),带路径限制防止穿越攻击
- fetch_url:HTTP GET请求,HTML自动转Markdown节省60-70% Token
- terminal:受限Shell命令执行,带高危命令黑名单
- python_repl:Python代码执行,适用于计算、数据处理等
环境准备
前置条件:Python 3.10+,可选Node.js 18+(跑前端)。
目录结构:
agentclaw/
└── backend/
├── .env
├── app.py
├── api/
│ └── chat.py
├── graph/
│ ├── agent.py
│ └── prompt_builder.py
├── tools/
│ ├── read_file_tool.py
│ ├── fetch_url_tool.py
│ ├── terminal_tool.py
│ └── python_repl_tool.py
├── workspace/
├── memory/
└── skills/
依赖安装:
pip install fastapi uvicorn \
langchain langchain-community langchain-experimental langchain-openai \
html2text python-frontmatter python-dotenv pydantic
核心代码实现
1. 工作区文件
AGENTS.md是最关键的文件,必须写清技能调用协议:第一步永远是read_file读取SKILL.md,禁止跳过。
2. 技能扫描器
启动时扫描skills/目录,提取每个技能的名字和描述,生成技能菜单注入System Prompt。使用XML格式,Claude系列模型对XML结构的路由准确率更高。
3. System Prompt构建器
动态拼接6个部分,文件不存在则留空。总长度超40000字符时截断。
4. Agent运行时
使用LangChain的create_tool_calling_agent和AgentExecutor,max_iterations=12(经验值,太小复杂任务会停,太大bug时循环烧Token)。
5. FastAPI入口与SSE流式输出
关键接口/api/chat,使用StreamingResponse推送SSE事件流。注意添加Cache-Control: no-cache和X-Accel-Buffering: no头,否则Nginx后面SSE会攒批推送。
创建第一个技能
以天气查询为例:
mkdir -p backend/skills/get_weather
backend/skills/get_weather/SKILL.md:
---
name: get_weather
description: 获取指定城市的实时天气信息。
version: 1.0.0
---
# 天气查询
## Steps
1. 从用户消息中提取城市名称
2. 中文城市名转英文(如"北京"→"Beijing")
3. 使用fetch_url访问:https://wttr.in/{城市}?format=j1
4. 从JSON中提取温度、天气状况、湿度、风速
5. 用自然语言回复用户
启动服务后,curl测试:
curl -X POST http://localhost:8002/api/chat \
-H "Content-Type: application/json" \
-d '{"message": "帮我查一下北京的天气", "session_id": "test"}'
正确的事件流顺序:先read_file读技能说明书,再fetch_url拉数据。
长期记忆
在AGENTS.md的记忆协议中告诉Agent何时写入MEMORY.md。Agent会在对话中自动学习用户信息并追加到该文件。
每次启动Agent,都会读取MEMORY.md"想起"你是谁、在做什么,实现真正的长期记忆。
常见问题
- Agent stopped due to max iterations:AGENTS.md写得太模糊,Agent循环调工具。查看verbose日志,在SKILL.md或AGENTS.md中加明确指引
- root_dir路径错误:ReadFileTool的root_dir必须用绝对路径,用os.path.abspath()计算
- SSE不流式输出:添加Cache-Control: no-cache和X-Accel-Buffering: no
- 模型不遵循技能调用协议:换更强模型,Claude对指令遵循最严格
- langchain_experimental ImportError:单独安装pip install langchain-experimental
完整依赖
fastapi>=0.111.0
uvicorn[standard]>=0.30.0
langchain>=0.2.0
langchain-community>=0.2.0
langchain-experimental>=0.0.62
langchain-openai>=0.1.0
langgraph>=0.1.0
html2text>=2024.2.26
python-frontmatter>=1.1.0
python-dotenv>=1.0.0
pydantic>=2.7.0
下一步
跑通后端后,还可以扩展:
- 前端:Next.js 14连接SSE接口,做Canvas面板、Memory编辑页、技能管理页
- 知识库RAG:用LlamaIndex加search_knowledge工具,从本地PDF/Markdown检索
- 浏览器自动化:browser-use配合Playwright,操控浏览器
- 会话持久化:写入sessions/{id}.json保留对话历史
Anthropic官方技能仓库github.com/anthropics/skills和agentskills.io有各种现成技能,格式完全兼容,可直接使用。