本地4B开源模型,把任何 App 当 Skill 用
之前分享过 CUA(Computer Use Agent)开源项目,能让 AI Agent 直接操控电脑界面,相当于把任何 App 都变成 Agent 的 Skill。但评论区有两个高频反馈:
- 太耗 token 了——截图上云、理解界面、定位元素、执行操作,每一步都在烧 token
- 截图上云,安全吗——企业级场景下确实有隐私顾虑
有数据表明,在自动编程流程里,GUI 测试消耗的 token 甚至占到整体的一半以上,是最大的单项开销。
这里介绍一个解决方案:Mano-P——一个开源的端侧 GUI-VLA(视觉-语言-动作)Agent 模型,加上推理加速框架 Cider,可以在本地 Mac 上运行,截图和任务数据不出设备。
Mano-P 是什么
Mano-P 是一个开源的端侧 GUI 操作模型,能够像人一样看屏幕,并操作电脑。
目前开源了两个尺寸:
- Mano-P 1.0-72B:在 OSWorld Benchmark 专项排行里排第一,成功率 58.2%,超过第二名 13 个百分点,但需要通过高配设备来跑
- Mano-P 1.0-4B:专门为端侧设计的轻量版,可以直接跑在 Mac mini / MacBook 上,量化后峰值内存才 4.3GB
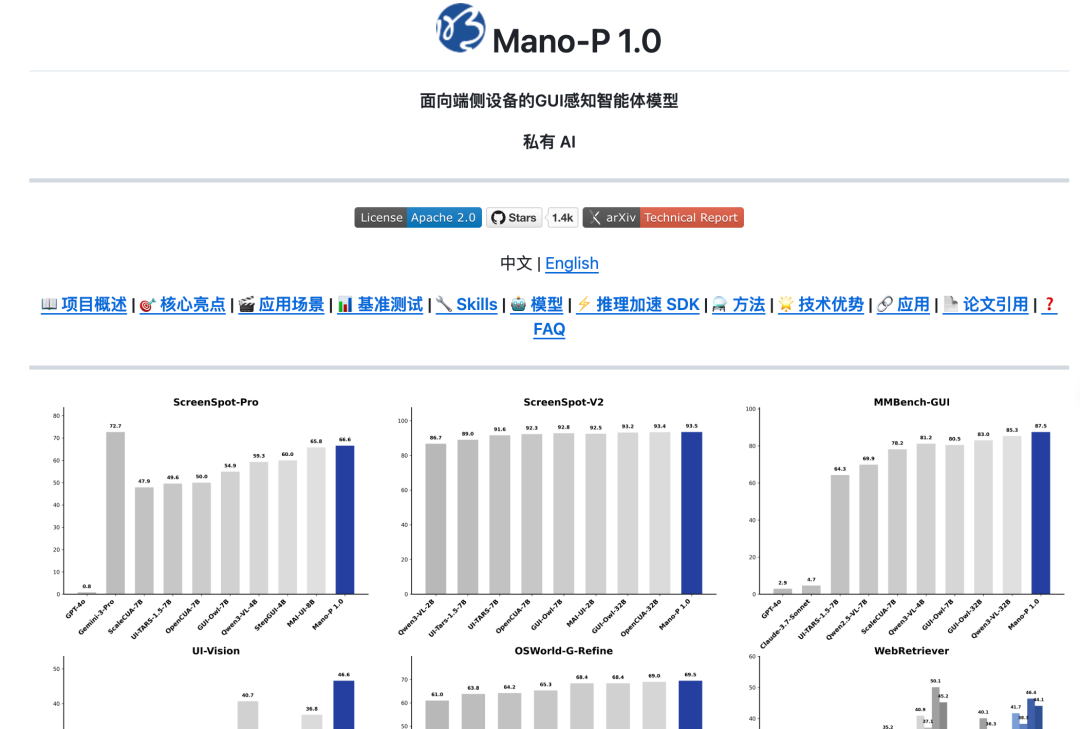
4B 版本在 CUA 任务上的准确率已经跟云端大模型相当。训练数据底子扎实:20,000+ 条浏览器操作轨迹、40,000+ 条桌面操作轨迹,覆盖 300 万+ 动作。
它的核心能力是纯视觉驱动,不依赖 CDP 协议,不解析 HTML,直接「看」屏幕截图来理解界面、定位元素、执行点击和输入。
这意味着它不局限于浏览器,桌面软件、3D 应用、专业工具、甚至游戏界面,理论上都能操作。之前用 Playwright 这类工具做浏览器自动化,本质上是在操作 DOM 树,碰到 Canvas 渲染的页面、非浏览器的桌面应用,直接失效。而 Mano-P 的纯视觉路线没有这个限制。

Cider:解决本地推理效率问题
Mano-P 解决了 token 和隐私问题,但本地跑模型,速度和效率是绕不开的坎。
Cider 是一个基于 Apple MLX 生态的推理加速框架,让模型在 Mac 上跑得更快、更省内存。它真正调用了 Apple GPU 的 INT8 计算能力。
Apple 的 M 系列芯片原生支持 INT8 计算,但 MLX 一直没把这个能力完全用上,只做了权重量化,没做激活量化。Cider 补齐了这块,它是第一个在 Apple GPU 上实现硬件加速 INT8 TensorOps 的框架。

实测下来,W8A8 模式比 MLX 原生的 W4A16 快 1.4 到 1.9 倍。而且 Cider 不只是给某一个模型用的,Qwen、Llama、Mistral 这些主流开源模型都能接入使用。
安装部署
官方推荐的硬件:Apple M4 芯片 + 32GB 内存的 Mac mini 或 MacBook。4B 模型跑起来还是轻松的,完全不卡。

安装后,通过 Skill 把 Mano-P 接入 Codex(也可以接入别的 Agent,比如 Claude Code 等)。
实测效果
测试一:自动浏览小红书并互动
让 Mano-P 去搜 AI 话题→浏览前三个帖子→点赞→并评论。小红书的 UI 比较复杂:信息流、弹窗、多种交互方式混在一起。
结果完成了任务。一个值得注意的细节是,第一个帖子打开时已经是点赞状态,Mano-P 习惯性地点了点赞按钮(实际上是取消了点赞),但它很快意识到不对,立马又把点赞重新点了回来。
这说明它不是在机械执行,而是能根据界面的视觉反馈来判断操作是否正确,并自动纠偏。这个能力对于 GUI Agent 来说非常关键。
测试二:用 tiktok-gen 做 E2E 测试
开发者场景:让 Codex + Mano-P 配合来跑 GUI 测试。
- Codex 负责调度和监督
- Mano-P 负责 GUI 操作:打开项目前端→测试注册、登录→资产中心上传图片和音频素材→文案素材生成→最后产出一份测试报告
4B 小模型的 GUI 操作能力确实不错,但偶尔会跑偏或者卡住,这时候 Codex 作为监督者就能及时纠偏,把任务拉回正轨。
这个组合比单独用 Codex 的 CUA 效果更好。单独用 Codex 自己做 GUI 操作,速度倒是快一些,但也会跑偏,而且没有另一个 AI 帮它纠偏,出了问题只能自己死磕。
更大的优点:整个过程不需要用到 Codex 的视觉能力。视觉理解这块完全由 Mano-P 在本地完成,Codex 只负责安排任务和纠偏。这意味着截图不会上传到云端,能省不少 token,私密性也更好。
整个过程除了慢一点,稳是真的稳。慢的原因主要是三个:一是 Codex 本身的思考耗时;二是本地配置没达到官方推荐标准;三是 Codex 和 Mano-P 之间的信息同步还不够丝滑。

测试三:玩游戏 🎮
让大模型玩 4399 上的扫雷。之前用 Playwright 去操作 4399 上的扫雷,完全做不到——4399 的游戏界面是 Canvas 渲染的,Playwright 操作的是 DOM 树,在 Canvas 面前直接失效。
Mano-P 是纯视觉路线,确实能操作:一步一步打开了 4399,搜索到扫雷,顺利进入了游戏界面,能点击到扫雷的方块。
但它并不太理解扫雷的游戏逻辑,玩得比较随机,没有根据数字去推理哪些格子安全。不过 Playwright 做不到的事,4B 小模型通过纯视觉还是能做。
总结
Mano-P 4B 的定位很明确:自动化执行给定的 GUI 任务,而不是全程独立思考怎么做。页面元素定位、按钮点击、表单填写、跨步骤任务执行,这些它都能做得不错。
搭配一个聪明的大模型(比如接入 Codex 配合 GPT-5.5)一起用,效果最好。大模型负责调度和纠偏,Mano-P 负责实际的 GUI 操作。
回到开头的两个痛点:token 成本和数据安全。Mano-P + Cider 的组合,确实一定程度上解决了这两个问题。本地 GUI 操作不花或少花 token,数据不出设备——这不是安全协议上写的「我们承诺不看你的截图数据」,而是物理上数据就没出过你的电脑。
苏米注:端侧 AI 的方向越来越清晰了——端侧模型不需要具备通用性,而是在某一个具体场景深耕、打穿。Mano-P 专注 GUI 操作这一件事,在本地就能跑,更私密、更省钱、更可控。对于注重数据安全的团队来说,这是一个值得关注的方向。
项目地址:https://github.com/MININGLAMP-AI/MANO-P