作为产品经理,我一直在追踪知识管理工具与AI结合的演进路径。腾讯ima近期上线了Copilot功能,这标志着该产品从单纯的信息存储工具向Agent(智能体)形态延伸。官方将其定义为“从工具变成伙伴”,其核心差异化在于引入了完整的记忆系统,使得AI能够基于用户的历史行为和背景信息提供定制化响应。

本文将基于我近期的内测体验,梳理ima Copilot的核心机制,并提供具体的配置与测试流程,供关注知识库Agent化方向的同行参考。
一、 核心机制:记忆系统的工作维度
ima Copilot的差异点主要体现在其对上下文的处理逻辑上。该系统被划分为四个功能模块,共同构成了其“专属Agent”的基础:
Copilot设定(人设配置)
功能:定义AI的输出风格与逻辑路径。
说明:可设定回答的正式程度,以及遇到问题时的处理策略(如直接给结论 vs. 先分析再作答)。
用户档案(背景信息)
功能:固化用户的基础职业信息。
说明:录入用户所在行业、岗位性质及常用工具。Copilot在生成内容时会自动套用这些背景,减少每次对话的Prompt前置解释成本。
长期记忆(历史沉淀)
功能:记录历史问答及处理逻辑。
说明:系统会留存用户之前提出的问题及最终的解决路径。当检测到相似场景时,会调用历史处理逻辑,而非每次从零开始推理。
经验技巧(技能学习)
功能:保存用户主动教授的处理规则。
说明:用户可以通过自然语言教授Copilot特定的处理方式(如“按学科分类整理”),系统会将这些规则固化为经验,用于后续同类任务。
二、 实操步骤:配置与流程详解
以下为创建并配置ima Copilot的标准流程:
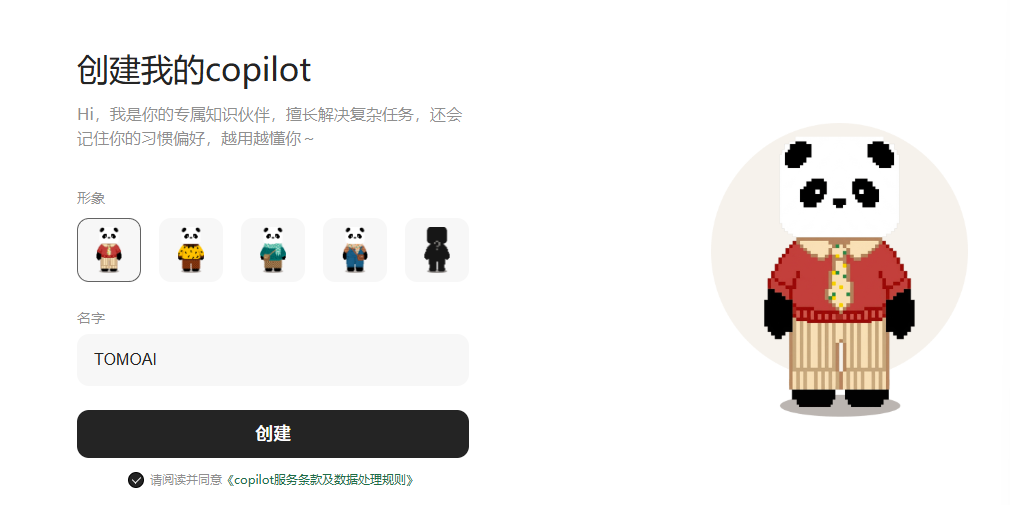
步骤1:基础配置与模型选择
- 操作:在ima内创建Copilot实例,完成命名与形象选择。
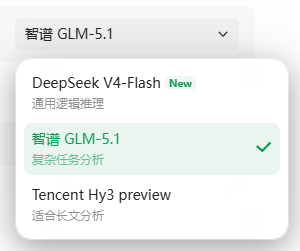
- 模型分配:当前提供三个模型选项(DeepSeek-V4-flash、GLM 5.1、腾讯混元)。系统默认根据任务类型自动匹配模型,用户也可选择接入自有API Key,使用自定义模型以节省平台算力。
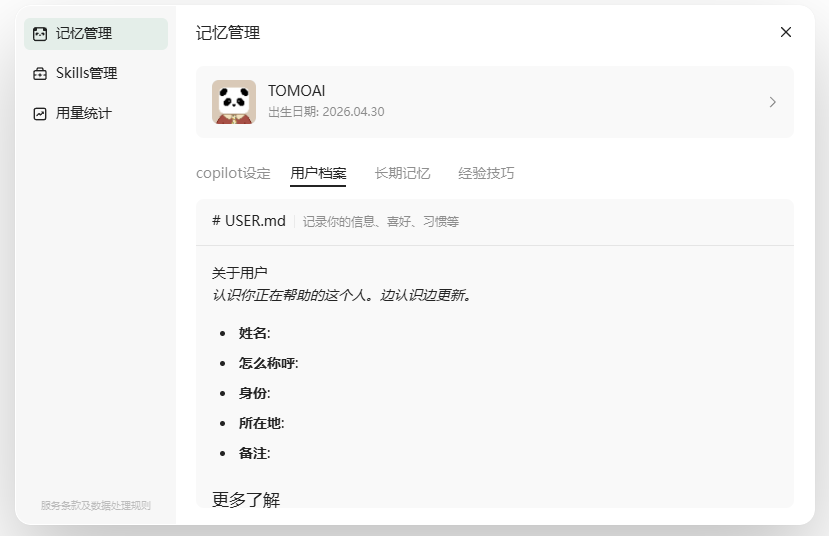
步骤2:初始化设定
- 操作:通过对话形式完成初始设定,定义“你是谁”及“我是谁”。
- 注意:记忆管理文件目前不支持直接编辑修改,必须通过对话交互逐步沉淀信息。
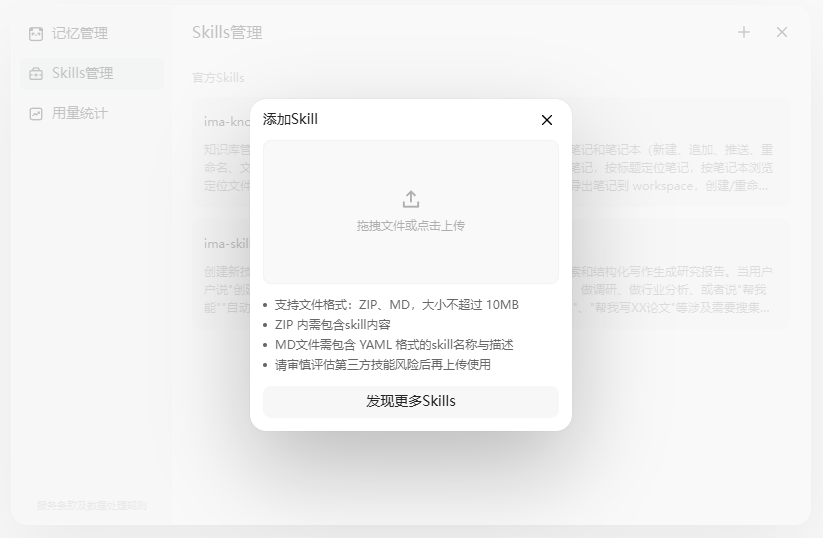
步骤3:技能包(Skills)配置
官方技能:内置4个与知识库强相关的Skill,包括知识库整理、笔记管理、Skill生成器、报告生成。

自定义技能:支持用户上传JSON等格式的自定义Skill文件。
步骤4:浮窗交互模式
- 操作:Copilot以浮窗形式常驻ima界面。
- 特性:具备当前上下文感知能力。在浏览网页、查看本地文件或知识库笔记时,无需手动上传,可直接向Copilot提问当前页面的内容摘要,或指令其将当前内容转为结构化笔记存入知识库。
三、 场景测试与效果评估
为验证其处理能力,我进行了三项典型任务的测试:
测试1:内容选题生成(白话输入)
- 输入:无特殊Prompt,直接使用口语化描述需求。
- 结果:输出了一份结构完整的选题清单,但内容颗粒度较粗,偏向概括性描述。
- 评估:适合作为头脑风暴的起点,但无法直接用于高垂直度的专业内容生产。
测试2:基于知识库生成专属Skill
- 流程:通过“@”关联特定知识库 -> 指令Copilot生成长文写作Skill -> 等待处理(耗时较长) -> 系统自动生成并入库。
- 结果:生成的Skill可正常调用,且支持打包导出(已上传至GitHub开源库测试跨平台可用性)。
测试3:长文本结构化生成(“成书”测试)
- 输入:一个包含多年零散笔记的知识库。
- 输出:耗时约1.5小时,生成了一本包含目录、案例、数据表格的完整书籍结构预览。
- 质量评估:文本具备基本的可读性与逻辑连贯性,排版结构达到了可直接用于印刷初稿的标准。
- 成本评估:该任务消耗算力213.3点(内测初始算力500点,日常登录补充100点),属于高算力消耗任务。
四、 差异化与适配性分析
基于上述测试,对ima Copilot进行结构化评估:
五、 总结
从产品演进的角度看,ima Copilot目前的定位是一个基于个人知识图谱的深度处理引擎,而非一个通用的自动化执行Agent。
它的核心价值在于降低了“提示词工程”的门槛——通过记忆系统和知识库的直接绑定,用户不需要每次详细描述背景,AI即可产出符合上下文语境的内容。特别是其支持跨用户知识库访问的特性,在一定程度上改变了传统知识管理工具“信息孤岛”的属性。
然而,作为一个Agent产品,它目前在“执行层”仍显被动。缺少定时任务和精细化标签操作,意味着它更擅长做“被呼叫时的深度处理”,而不适合作为自动化流水线的一环。对于知识管理重度用户而言,这是一次提升信息利用率的实质性更新;但对于寻求全链路自动化的专业用户,目前的技能包配置和触发机制尚需进一步完善。