OpenAI 曾发布一篇技术博客:3 个工程师、5 个月,产出了 100 万行生产级代码。没有一行是人手写的。通过约 1500 个 Pull Request 完成了一款内部产品的构建和迭代,每人每天平均合并 3.5 个 PR。
很多人第一反应是:他们用了什么特殊的模型?答案是:没有。用的就是市面上所有人都能用的 AI。那差距到底在哪?

AI 应用的三个阶段
过去两年,"学会用 AI"这件事经历了三个完全不同的阶段。很多人卡在某一个阶段里浑然不觉,还以为自己已经用得很溜了。
第一阶段:Prompt Engineering(2024年)
这是大多数人最熟悉的阶段。核心问题只有一个:怎么措辞?你在 ChatGPT 里反复调整问题的表达方式,加上"请用专业语气"、"分三步回答我"、"不要废话直接给结论"这类修饰语。整个交互模式是一问一答,你在乎的是那一次回答的质量。
第二阶段:Context Engineering(2025年)
到了这个阶段,大家意识到光靠一次好提示是不够的。真正的功夫在于:在 AI 运行的过程中,在合适的时机输入合适的内容。先给它看相关文档,再给它看你的需求,再给它看历史案例,最后才让它动手——这样的效果,比一次性把所有要求堆在一个提示词里要好得多。
2025 年 6 月,前 OpenAI 联合创始人 Andrej Karpathy 发了一条推文,为这个概念正式命名:"工业级 LLM 应用的核心功夫,是上下文工程——精心填充上下文窗口,让模型在每一步都拿到恰好足够的信息。"
三个月后,Anthropic 发布了系统性的 Context Engineering 方法论博文,这个概念从一条推文变成了完整的工程实践。
第三阶段:Harness Engineering(2026年)
即便把 Context Engineering 做到极致,很多复杂任务还是做不了。问答没问题,简单任务没问题。但要让 AI 独立完成一个完整功能的开发、测试、集成?大概率半途而废,或者产出一堆看起来像那么回事、实则漏洞百出的东西。
2026 年 2 月,HashiCorp 联合创始人 Mitchell Hashimoto 在他的博客里给出了答案,并正式命名了这个新概念——Harness Engineering。
他的定义值得反复咀嚼:每当你发现 Agent 犯了一个错误,你就花时间工程化一个解决方案,让这个错误永远不再发生。
注意,这里说的不是"写一行提示词让 AI 下次注意"。而是用代码、配置、自动化脚本,把约束永久固化下来。
它们是包含关系,不是替代关系
很多人看到"Harness Engineering"这个新词,第一反应是"Prompt Engineering 过时了?"完全不是。
Philipp Schmid(Hugging Face 工程师)用了一个很直观的类比:AI 模型是 CPU,上下文窗口是 RAM,而 Harness 就是操作系统。你不会在没有操作系统的 CPU 上直接跑程序——同理,让 AI 在没有 Harness 的环境里"裸跑",效率和可靠性都会大打折扣。
Harness Engineering 的四根支柱
综合 OpenAI、Anthropic 以及大量一线团队的实践,Harness Engineering 可以提炼为四大支柱。
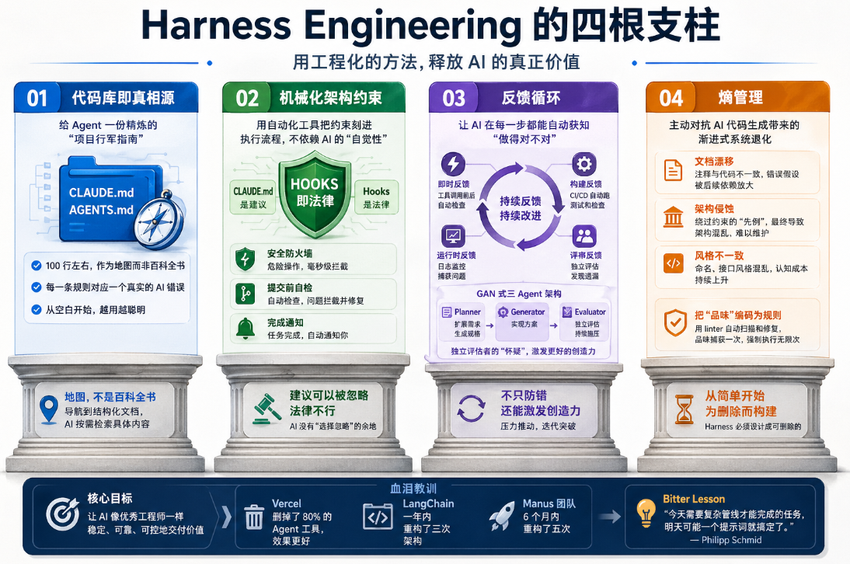
支柱一:代码库即真相源
给 Agent 一份精炼的"项目行军指南",让它每次启动都自动读取。在项目根目录放一个配置文件——Anthropic 体系叫 CLAUDE.md,OpenAI 体系叫 AGENTS.md。AI 每次启动自动读取,获取项目的技术栈、常用命令、编码规范和行为禁区。
核心原则:它应该是地图,而不是百科全书。OpenAI 团队曾尝试把所有信息塞进一个庞大的配置文件,失败了。上下文窗口是稀缺资源,一个 500 行的说明书反而让 AI 不知道哪些信息和当前任务相关。黄金标准是 100 行左右,作为导航目录指向结构化的文档,AI 按需检索具体内容。
Hashimoto 分享了一条维护法则:配置文件里的每一条规则,都应该对应过去一个真实的 AI 错误。从空白开始,每次 AI 犯错就补一条规则,让它越用越聪明。
支柱二:机械化架构约束
用自动化工具把约束刻进执行流程,不依赖 AI 的"自觉性"。配置文件写的是"你应该这样做",是建议。而 Hooks(钩子)执行的是"你必须这样做,否则操作被阻止",是法律。
CLAUDE.md 是建议,Hooks 是法律。建议可以被忽略,法律不行。
三个具体场景:
- 安全防火墙:AI 准备执行一条清理命令,但路径写错了。PreToolUse Hook 在命令执行前触发,检测到危险模式,10 毫秒内硬性拦截
- 提交前自检:AI 写完代码准备提交,Hook 自动先跑一遍代码质量检查。发现问题就拦截并反馈给 AI,AI 自动修复后再次尝试提交
- 任务完成通知:你让 AI 跑一个耗时 15 分钟的任务,然后去泡咖啡。任务完成时,Hook 自动弹出桌面通知
这里有一个反直觉的洞察:给 AI 更多约束,反而能提升它的产出质量。当你约束它"必须用 React 组件、遵循项目的命名规范、通过 Service 层调用后端",它在收窄后的解空间里反而更容易找到正确答案。
支柱三:反馈循环
让 AI 在每一步都能自动获知"做得对不对",而不是做完所有事才发现全错了。Anthropic 的比喻极其精准:AI 的每个新会话开始时没有之前的记忆,就像轮班的工程师没有交接记录。
反馈循环分四个层次:
- 即时反馈:工具调用前后,自动检查格式、安全、语法
- 构建反馈:提交 PR 时,CI/CD 自动跑测试和代码检查
- 运行时反馈:部署后,日志和监控捕获性能问题
- 评审反馈:功能完成后,独立评估者检查设计层面的遗漏
最前沿的探索是 Anthropic 提出的 GAN 式三 Agent 架构:Planner 负责把模糊需求扩展为可执行规格,Generator 负责实现,Evaluator 负责独立评估。
他们发现了一个根本性问题:当 AI 被要求评估自己的工作时,它会表现出不合理的自信和宽容。解决方案不是"让 AI 学会自我批评",而是把评估彻底交给独立的角色。
支柱四:熵管理
主动对抗 AI 代码生成带来的渐进式系统退化。这是最容易被忽视的支柱,但可能是 Harness Engineering 里最具原创性的洞察。
三种典型的退化模式:
- 文档漂移:AI 改了代码,但忘了更新注释。三个月后,另一个 AI 依赖这条注释写了新功能,然后才发现不对
- 架构侵蚀:项目约定所有数据库查询必须通过 Repository 层。某次 AI 觉得多写两个方法太麻烦,直接在 Controller 层写了 SQL。代码能跑,但这个"先例"一旦出现,下一个 AI 也跟着绕过约束
- 风格不一致:周一的 AI 用 camelCase,周三的 AI 用 snake_case,周五的又换回去了。三种风格在同一个项目里共存
OpenAI 的解法:把"品味"编码为规则。团队对代码质量的判断标准,不是写在文档里祈祷 AI 遵守,而是写成 linter 规则自动扫描。错误消息本身就是修复指南。
概括是:品味捕获一次,强制执行无限次。
苏米注:熵管理这个概念非常精准。AI 生成的代码不会让程序崩溃,但整个代码库在缓慢退化——注释过时、架构侵蚀、风格不一致。这些问题单独看都不严重,但累积效应是致命的。
一组颠覆直觉的数据
2026 年 3 月,LangChain 做了一个控制变量实验。在 Terminal Bench 2.0 基准测试上,模型完全不换,只调整了三个 Harness 变量:系统提示词、工具配置、中间件 Hooks。
结果:排名从 30 名开外跃升到 Top 5,提升了 13.7 个百分点。作为对比,同期如果通过换一个更强的模型来提升成绩,通常能获得约 6.8 个百分点的提升。
优化 Harness 的效果,是换模型的两倍。
核心公式由此清晰:产出质量 = 模型能力 × Harness 设计水平
标杆案例
| 项目 | 团队 | 核心启示 |
|---|---|---|
| OpenAI Codex | 3 人团队 | 五大核心原则 + 六层分级架构约束,Harness 是 Agent-First 开发模式的根基 |
| Stripe Minions | 企业级 | 近 500 个 MCP 工具,每周 1300+ PR,Blueprint 机制:AI 动手前先生成计划,人类批准后才执行 |
| LangChain | 开源团队 | Doom Loop 检测中间件:当 AI 反复修改同一文件却无法通过测试时,自动介入提示重新评估 |
| GStack | Garry Tan | 纯 Markdown 流程,28 个角色按 Sprint 顺序运行,60 天产出 60 万行代码 |
工程师角色的变化
Mitchell Hashimoto 这样描述自己现在的角色:"我是软件项目的架构师。我仍然负责代码结构、数据流设计、状态管理。但具体的代码编写,越来越多地交给了 AI。"
用厨师来类比:过去,厨师亲自做每一道菜。现在,厨师负责设计菜单、训练厨房团队、检查每道菜的出品质量。这不是降级,而是升级。
复杂度并没有消失,只是从"写代码的复杂度"转移为"设计环境的复杂度"。而这个新的地方,更适合发挥人类在系统思维上的优势。
几点冷思考
在所有令人兴奋的数字面前,有几点清醒是必要的:
- 验证缺口:Harness 擅长检查代码是否"合规",但对代码是否"正确"(功能逻辑是否符合业务预期)的验证仍然不够
- 遗留代码困境:目前几乎所有成功案例都是从零开始的新项目。对于已有数万行遗留代码的系统,如何设计 Harness 使 AI 能在其中安全工作,还没有经过验证的方法论
- Harness 必须设计成可删除的:今天需要复杂管线才能完成的任务,明天可能一个提示词就搞定了。Vercel 删掉了 80% 的 Agent 工具,效果反而更好
从哪里开始
不需要一步到位搭建复杂的系统。最小可行的起点:
在你最常用的项目里创建一个 CLAUDE.md(或 AGENTS.md)文件,写下三件事:项目用什么技术栈、哪些命令是常用的、哪些文件绝对不能碰。然后在使用过程中,每次 AI 犯错,就把那个错误背后的规则补进去。
从一个 100 行以内的文件开始,随着使用不断积累。这是 Hashimoto 的方法,也是那些做出惊人产出的团队实际在做的事。
真正的门槛从来不是技术,而是思维方式的转变——从"怎么写好一个提示词",到"怎么为 AI 搭建一个好的工作环境"。
参考资料:
- OpenAI Harness Engineering 博文(2026 年 2 月)
- Mitchell Hashimoto个人博客(2026年 2 月)
- Anthropic Context Engineering & Long-Running Agents 系列博文(2025 年 9 月-2026 年 3 月)
- LangChain Terminal Bench 2.0实验报告(2026年 3 月)