折腾一周 AI 记忆,我发现两款超级牛的 AI 知识库
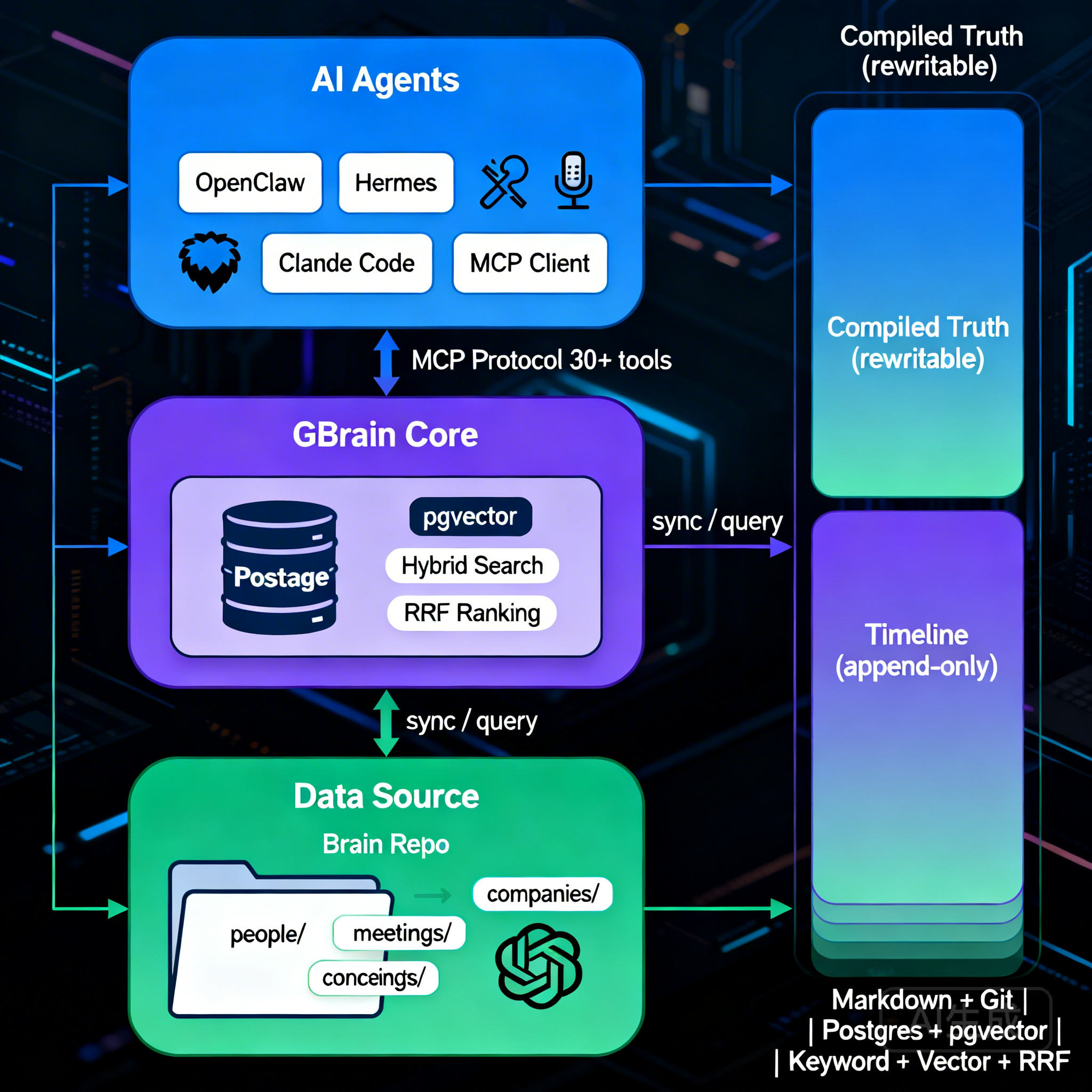
最近在做一个智能体,说实话看到 OpenClaw 的记忆不好可能会去吐槽,但是自己实战后才发现他的记忆已经做的很不错了。今天我看到了 GBrain 的架构让 AI 既能"快速回忆当前认知",又能"深度追溯历史证据"——召回时分层,检索时混合,更新时追加,全程可追溯。
一句话定位
Garry Tan 的「第二大脑」——专为 AI Agent 设计的 Memex 系统,让知识实现复利增长。
核心数据(Garry 本人的生产环境)
作者本人因为有太多的个人数据用 AI 存储,所有自己做了一套 AI 知识库结构。
| 指标 | 规模 |
| Markdown 文件 | 10,000+ |
| 人物档案 | 3,000+(含关系图谱) |
| 日历数据 | 13 年(21,000+ 事件) |
| Apple Notes | 5,800+(2009 年至今) |
| 会议转录 | 280+(含 AI 分析) |
| 原创想法 | 300+(按论题组织) |
核心架构:Compiled Truth + Timeline
每页 Markdown 采用双区结构:
# 人物/公司/会议名称
## Compiled Truth(顶部·当前最佳理解)
- 随时重写,反映最新认知
关键设计:证据链 append-only,Compiled Truth 可重写——既保证可追溯,又支持认知迭代。
Brain-Agent 核心循环
- 信息到来(会议/邮件/推文/链接)
- 实体检测(人/公司/原创想法)
- READ:先查大脑(gbrain search / get / query)
- 带上下文回应
- WRITE:更新大脑页面(编译新信息、追加 Timeline、交叉引用)
- Sync:gbrain 索引变更
- 下次信号到来时,Agent 已更聪明
Dream Cycle(夜间自动维护)
Garry 描述了夜间自动维护机制,确保知识库保持最新状态。
小结
这套 AI 知识库架构的核心价值在于:
- 分层召回:快速回忆当前认知 + 深度追溯历史证据
- 混合检索:结合多种检索策略
- 追加更新:证据链 append-only,保证可追溯性
- 全程可追溯:所有认知迭代都有据可查
对于想要构建个人 AI 知识库或智能体记忆系统的朋友,这套架构值得参考。
声明:本站原创文章文字版权归本站所有,转载务必注明作者和出处;本站转载文章仅仅代表原作者观点,不代表本站立场,图文版权归原作者所有。如有侵权,请联系我们删除。
未经允许不得转载:AI 知识库架构实战:Garry Tan 的「第二大脑」系统设计详解