前几天,Google DeepMind 发布了 Gemma 4,这个新一代开源大模型家族。配合他们之前的 Google AI Edge Gallery App,你现在可以在手机上、完全离线地跑一个相当聪明的 AI。
Gemma 4 是一个能看图、听声音、调工具、做多步推理的大语言模型。
Gemma 4 是什么?
Google 正式发布 Gemma 4,这是其开源模型系列的最新一代,脱胎于 Gemini 3 的同一套研究成果。"Gemma"一名源自拉丁语,意为"宝石",寓意精炼而有价值。

这次一共发布了四个版本:
| 版本 | 参数量 | 内存需求 | 适用设备 |
|---|---|---|---|
| E2B | 23 亿 | ~4GB | 手机/树莓派 |
| E4B | 45 亿 | ~5.5GB | 手机(推荐) |
| 26B | 252 亿 (MoE) | 16-18GB | 电脑 |
| 31B | 307 亿 | 17-20GB | 电脑(满血版) |
也就是说,E2B 和 E4B 是给手机准备的,26B 和 31B 是给电脑准备的。
对于大多数人,建议很明确:直接选 E4B。它在智能程度、速度和资源占用之间取得了最好的平衡。
在手机上运行
整个过程分三步,非常简单。
1. 下载 Edge Gallery App
设备要求:
- Android 12+ 或 iOS 17+
- 至少 2GB 可用存储空间
Android 用户:直接在 Google Play 搜索 "Google AI Edge Gallery" 下载。
iOS 用户:在国区的 Apple ID 登录后打开 App Store 也可以搜索下载。

2. 下载模型
打开 App 后,你会看到一个模型推荐列表。对于大多数用户,建议:
- 首选 Gemma-4-E4B-it(指令微调版)。约 3.6GB,智能和速度最均衡。
- 手机较旧或内存紧张,选 Gemma-4-E2B-it,更小更快。
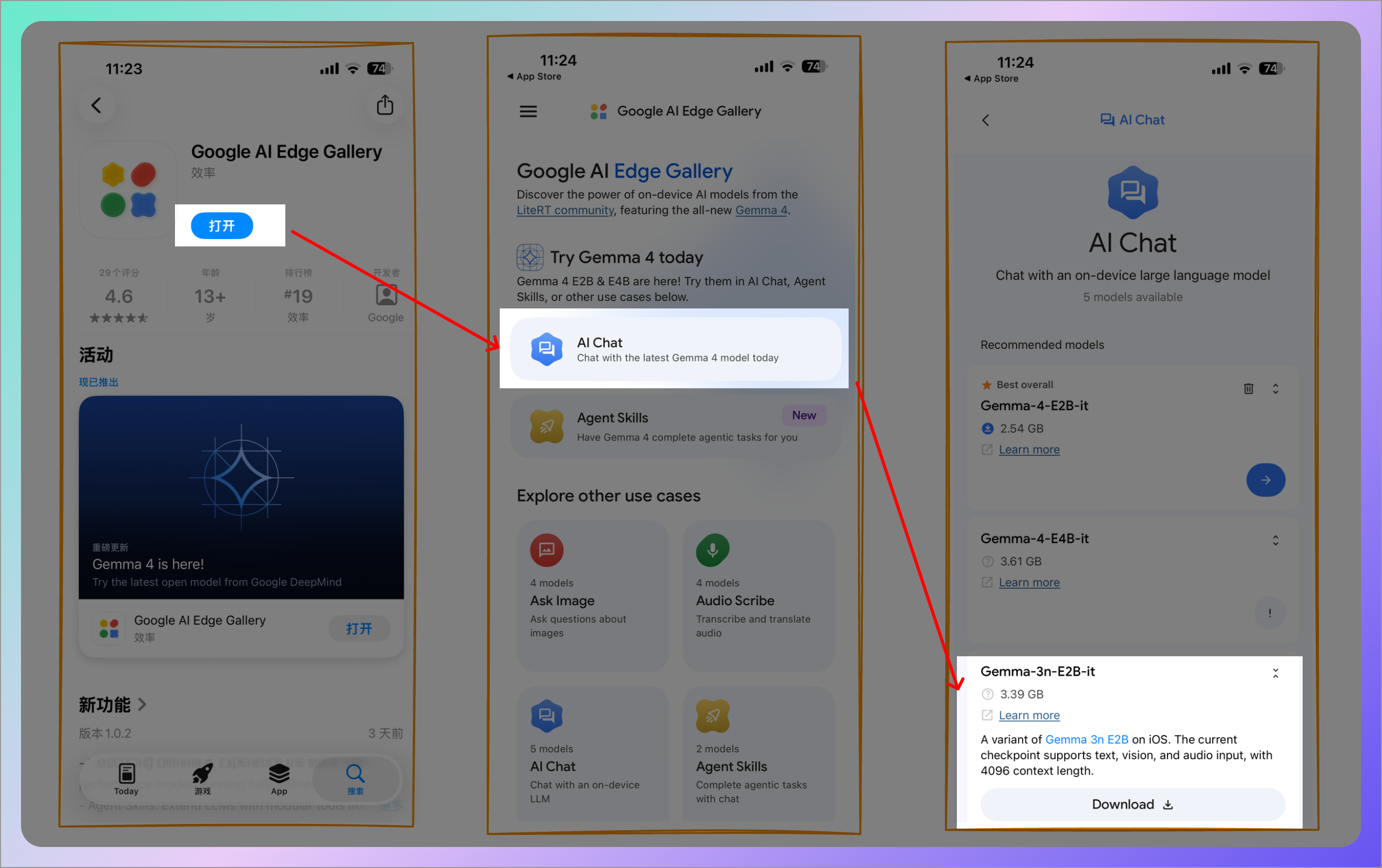
下载完成后,模型就永久存在你手机上了,以后完全离线使用。
核心能力
1. AI Chat(AI 聊天)
最基础的用法,你可以跟 Gemma 4 自由对话,问它任何问题。手机在离线断网情况也可以使用。
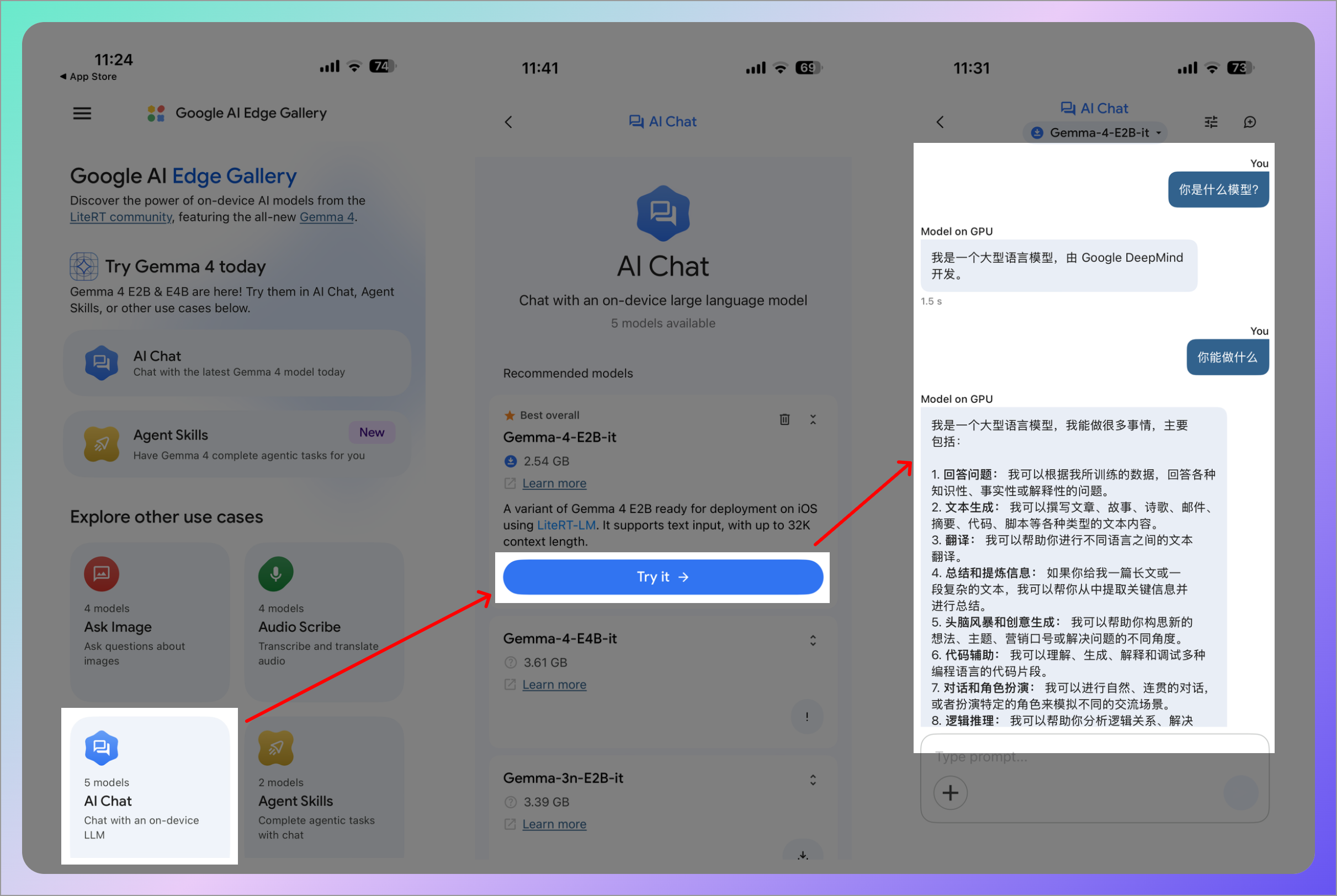
特别推荐试试 Thinking Mode,模型会展示它的逐步推理过程。
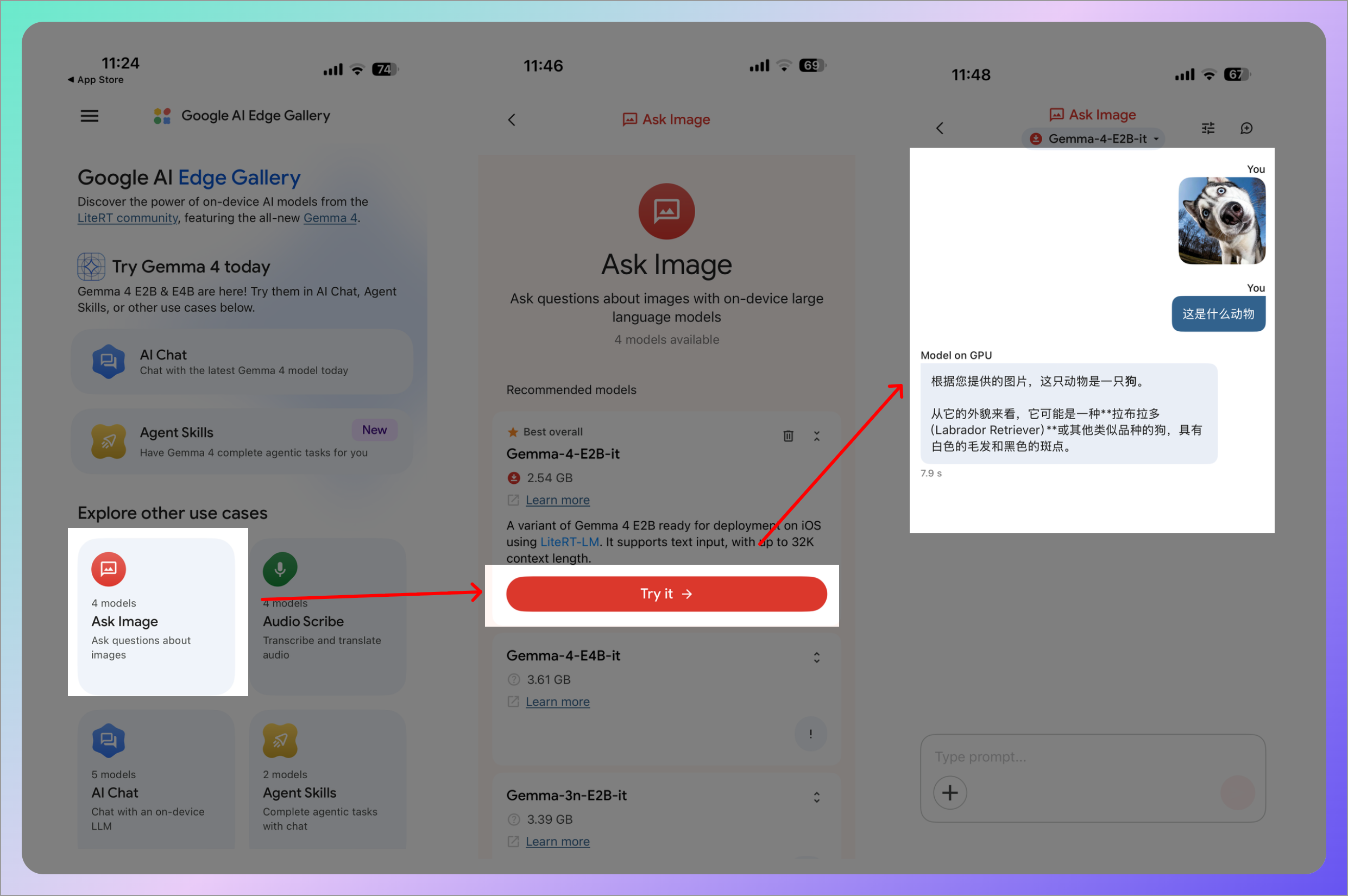
2. Ask Image(图像问答)
拍张照片或从相册选一张,直接向 AI 提问。因为是原生多模态,不需要先做 OCR 再理解文字,模型直接看图就能理解。
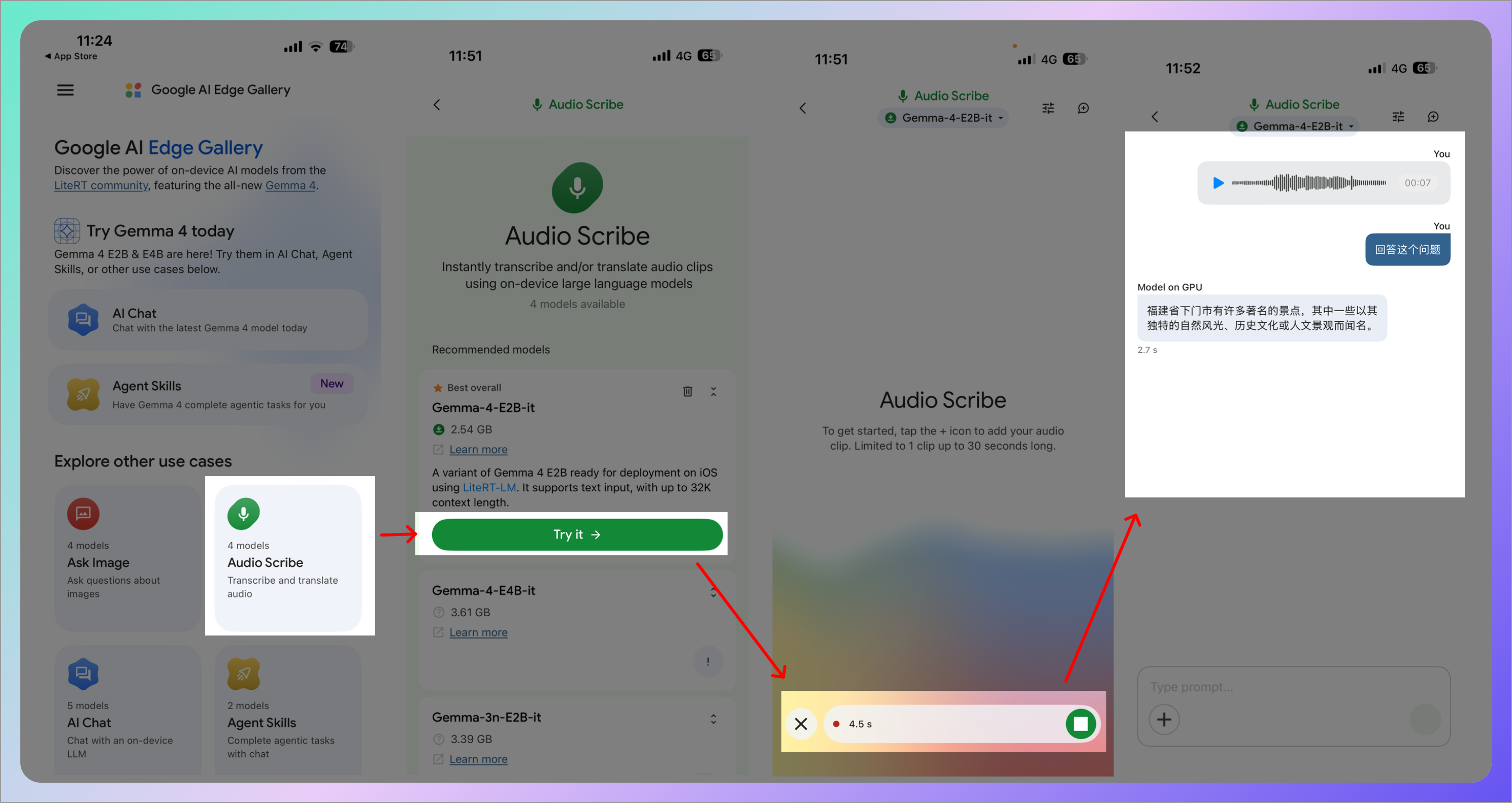
3. Audio Scribe(语音转写)
实时的离线语音转文字,还可以翻译。开会、采访、记笔记都很好用。并且可以完全离线,你的语音数据不会离开手机。
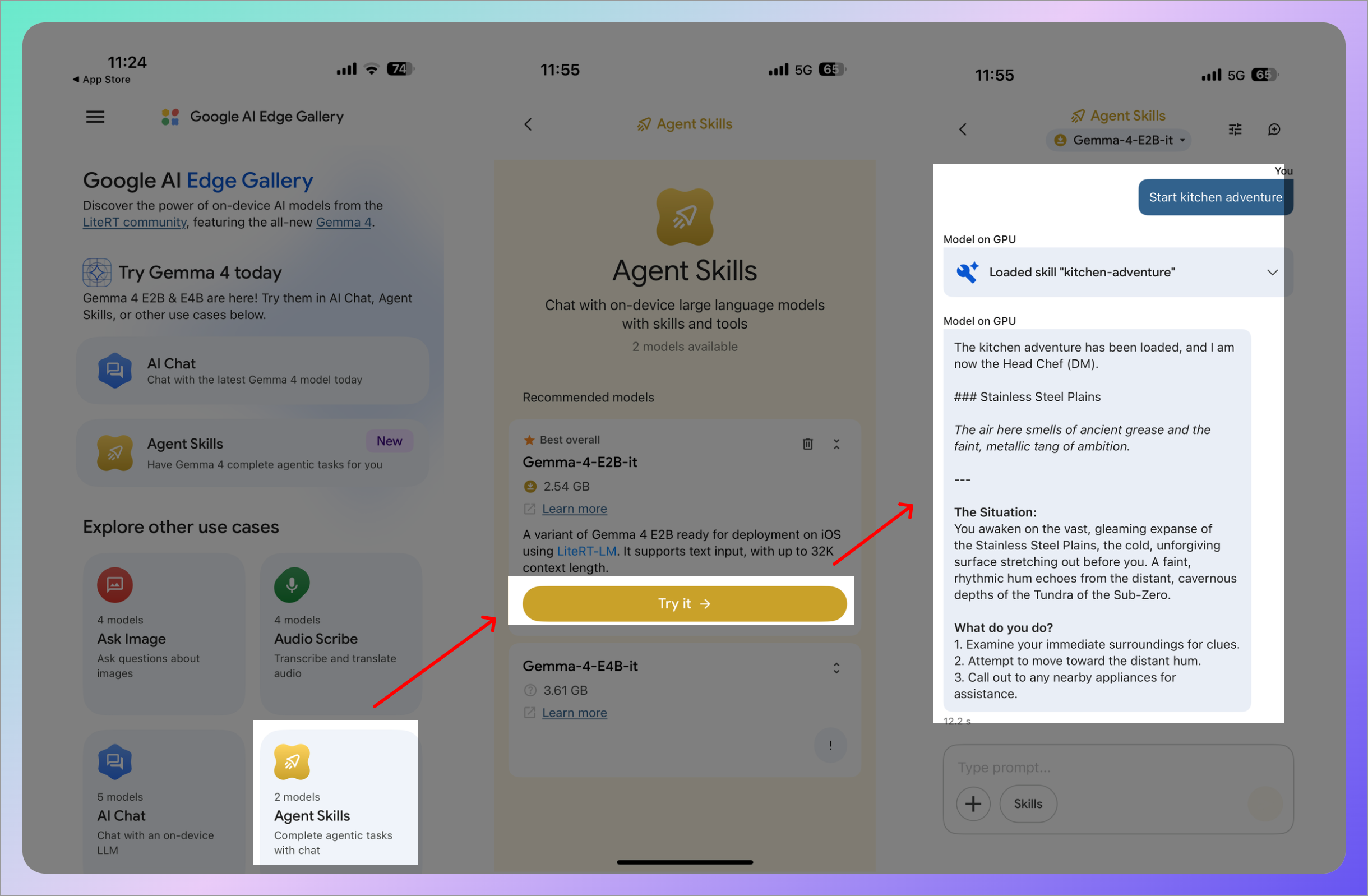
4. Agent Skills(智能体技能)
这是进阶玩法。Gemma 4 可以调用外部工具来完成复杂任务。比如查询维基百科、把数据生成可视化图表、给照片配上氛围感音乐。
5. Prompt Lab(提示词实验室)
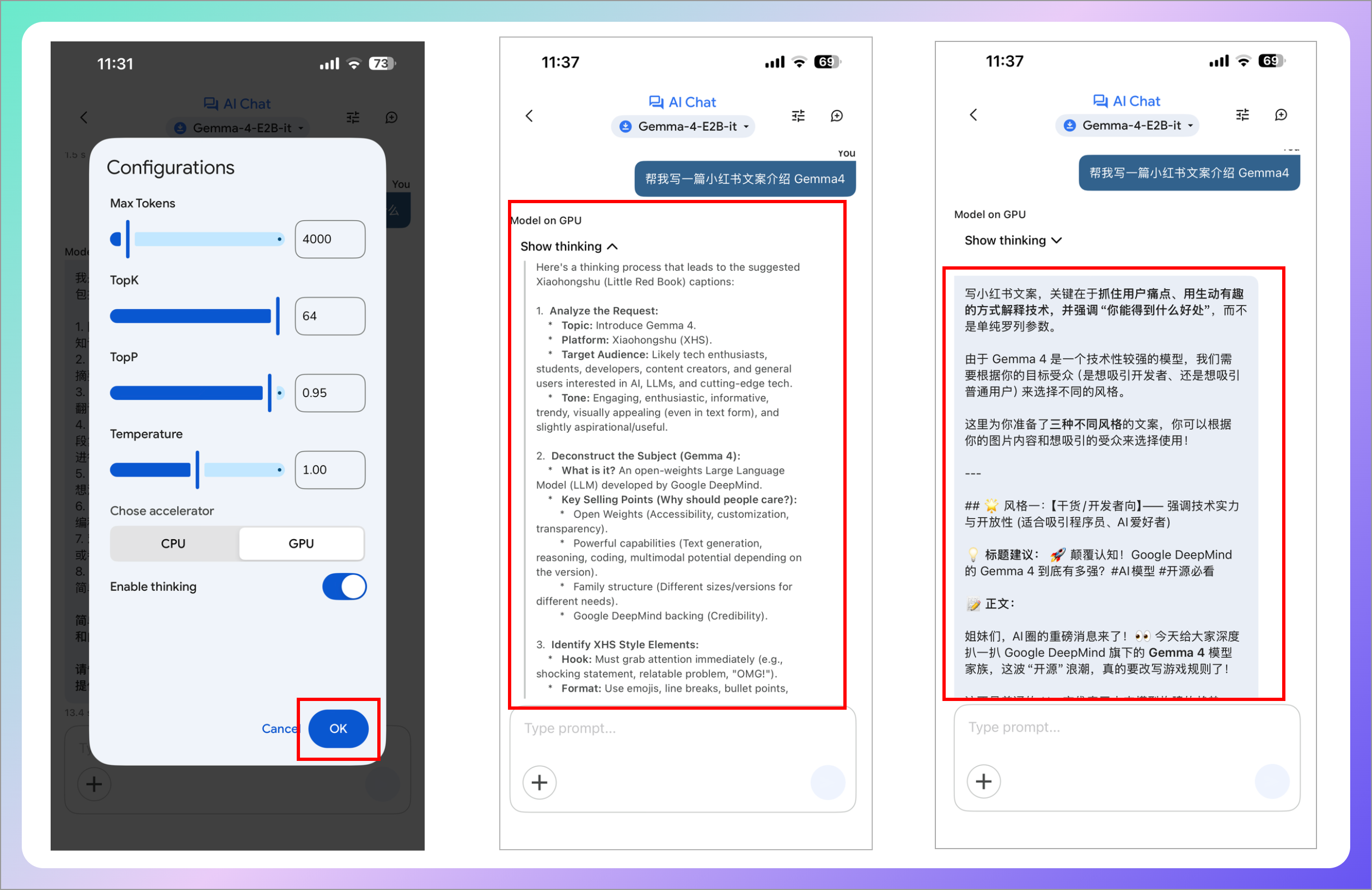
进阶玩家专用。你可以调整温度、top-k 等生成参数,对比不同提示词写法带来的输出差异。
使用感受
这几天的使用感受:
- 速度方面:在我的手机上响应很快,基本是秒回。离线状态下和在 Wi-Fi 下体验一致。
- 能力方面:日常对话、知识问答、文案润色这些任务完全够用。多步推理和 Agent 功能是亮点。
- 隐私方面:所有数据都在手机本地处理,不上传任何内容。你让它处理公司文件、个人照片、私密对话,完全不用担心数据泄露。
当然也有局限。跟 GPT-4o、Gemini Pro 这种顶级云端模型比,在超复杂任务上还是有差距。超长文本处理也受限于手机的内存。但话说回来,它是跑在你手机上的、完全离线的、免费的模型,能做到这个程度,已经相当厉害了。
另外,Google AI Edge Gallery APP 不会保存历史对话记录,需要及时做好保存。
相关链接
- Gemma 4 官方博客:https://blog.google/innovation-and-ai/technology/developers-tools/gemma-4/
- Gemma 4 模型文档:https://ai.google.dev/gemma/docs/core
- Gemma 4 模型卡片:https://ai.google.dev/gemma/docs/core/model_card_4