今天深度聊一聊一个被频繁问到的问题:智能体里的 Memory(记忆)到底分为短期记忆(Short-term memory)和长期记忆(Long-term memory)两类,它们分别指什么、差别在哪、又是如何实现的?
一、先搭个框架:智能体的“大脑”和“记忆”
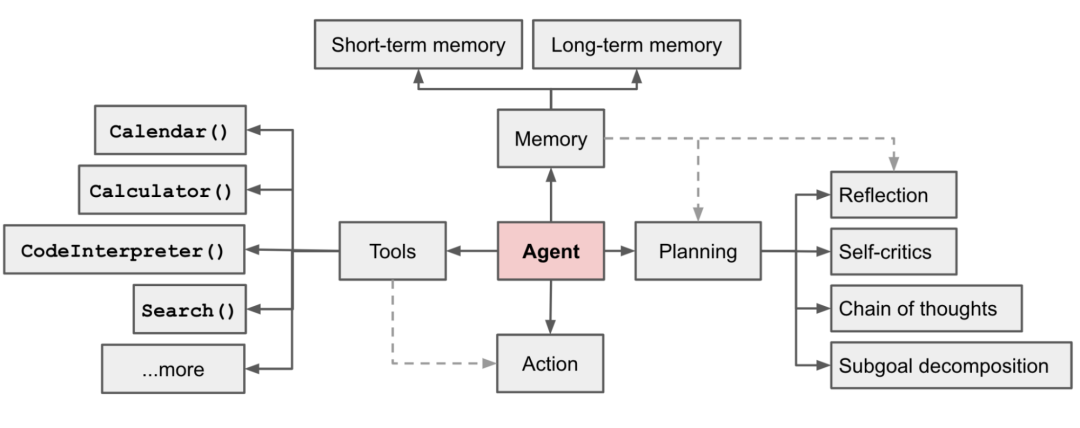
按照《LLM Powered Autonomous Agents》的划分,大语言模型(LLM)在自主智能体中相当于“大脑”,它与规划、工具和记忆等关键组件协同工作。其中,“记忆”又细分为短期与长期两部分,分别承担不同的角色。
二、短期记忆:只在当前会话里的记忆
它是什么:短期记忆可以理解为智能体在单一会话中维持的即时上下文能力。
工作原理:完全依赖大模型的“上下文窗口”。智能体会把此前的对话历史、以及中间推理步骤(如 Chain of Thought)拼进 Prompt,一并提交给模型。
天然局限:对话越长,越早的信息越容易被“挤”出上下文窗口,从而被丢弃或“遗忘”。
常见缓解方法:
- 滑动窗口:只保留最近的若干轮对话。
- 摘要法:把更早的大段对话浓缩成简短摘要,给新内容腾出窗口空间。
本质上怎么实现:短期记忆是通过“请求参数”维持的——我们在每次请求时附带上此前的对话历史,模型才知道“你们之前聊过什么”。
实操示例:以 Cherry Studio 为例
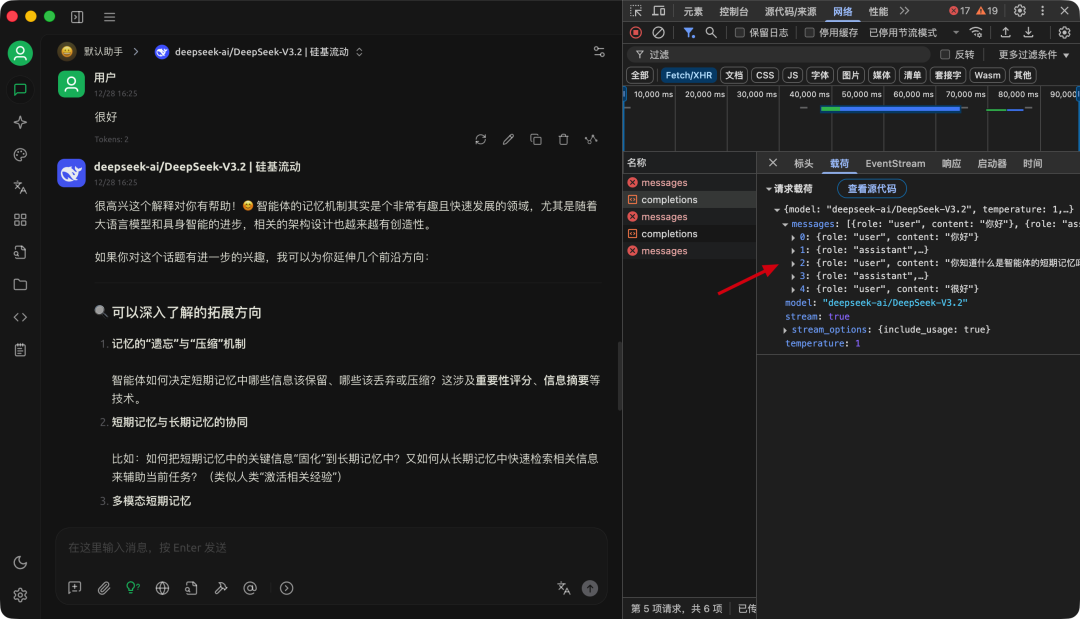
在 Cherry Studio 里,无论是默认助手还是自定义助手,模型设置中都会显示“上下文数”。
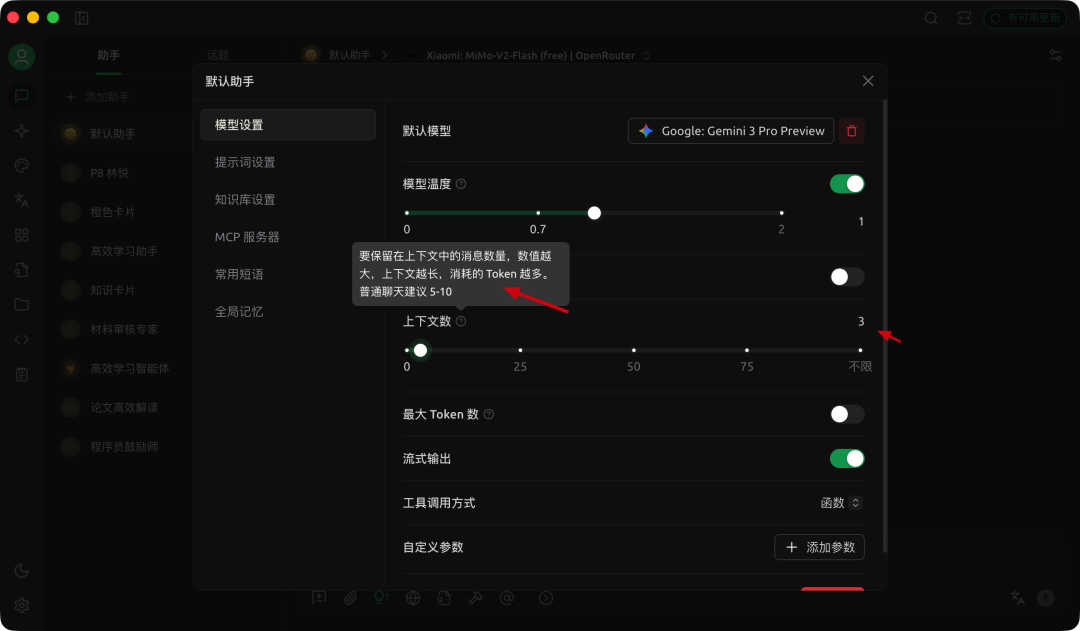
这代表能携带进当前请求的历史轮次。
比如你依次提问:“你好” →(第二个问题略)→ “很好” → “不需要”。
当对话轮次超过设置的“上下文数”时,最早那轮(如第一句“你好”)就可能被丢弃,模型在新一轮回答中不再能看到它。
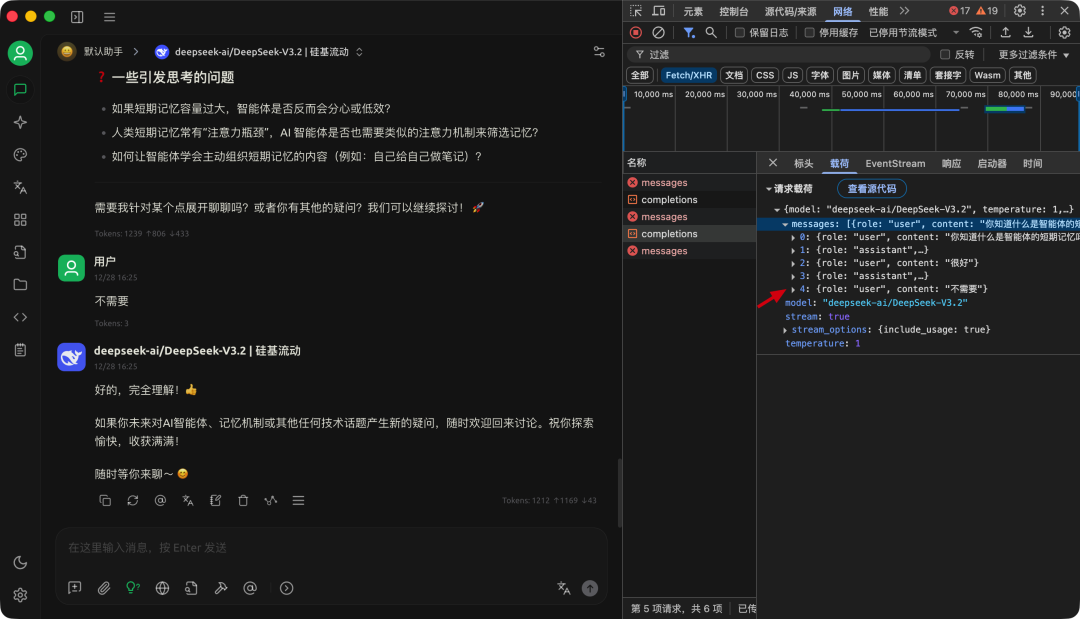
小提示:点击 Cherry Studio 客户端窗口后,按快捷键 Ctrl + Shift + I(Mac:Command + Option + I)可打开控制台,查看请求过程与上下文携带情况。
为什么不把“上下文数”拉满?
成本上升:多数大模型按输入与输出的 tokens 计费。上下文越长,费用越高。
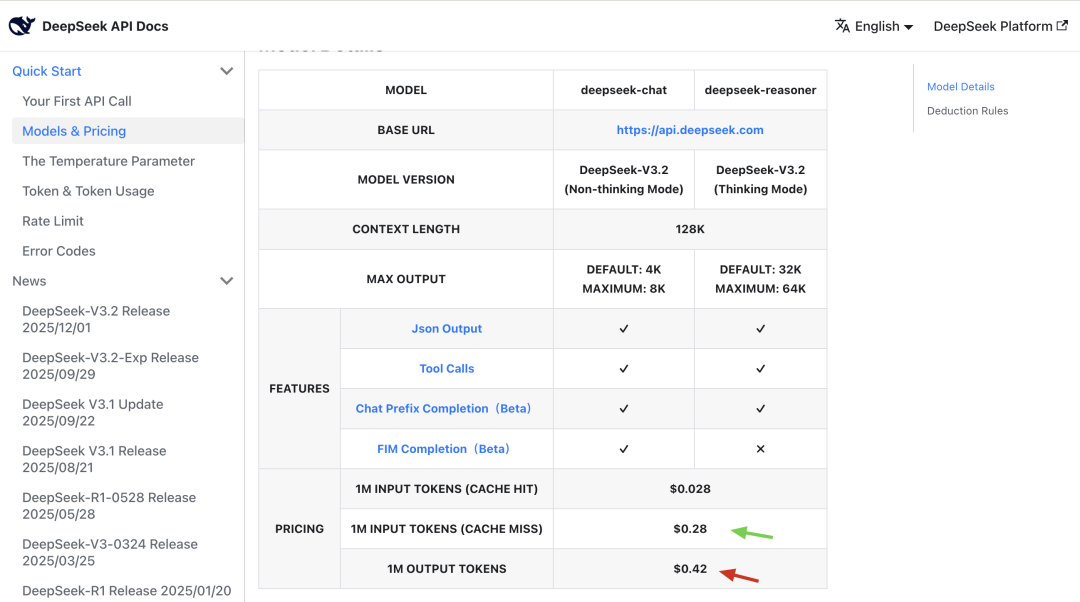
参考定价:DeepSeek 计费说明。
效果可能变差:上下文超长时,很多模型的综合能力反而会下降。
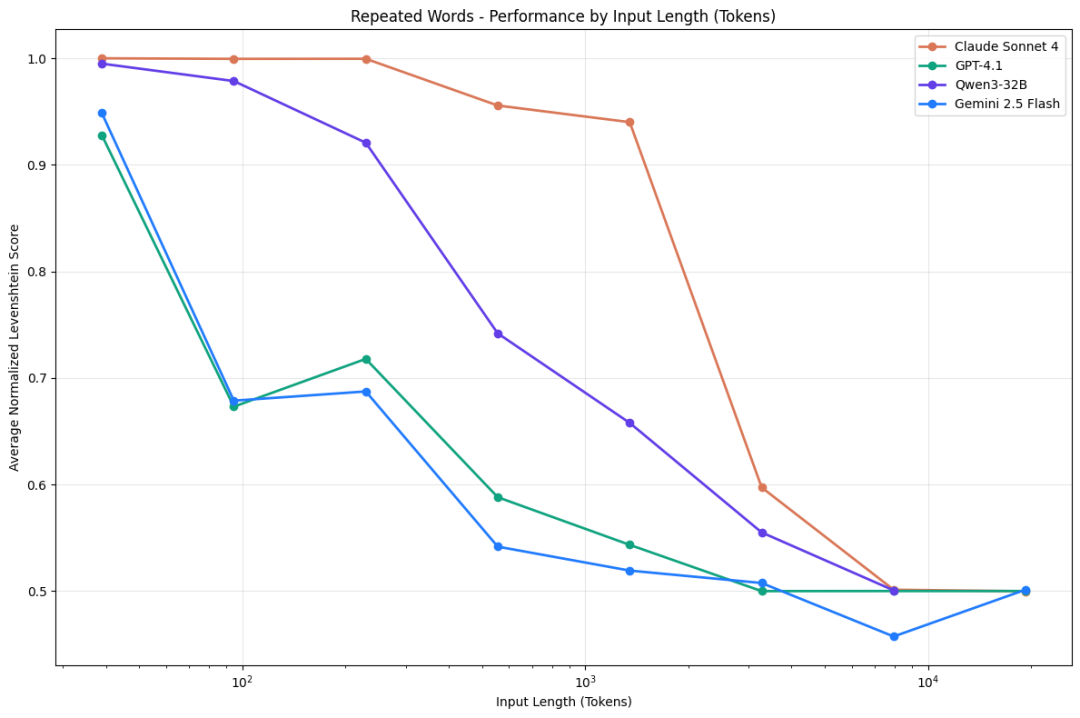
可参考研究:Context matters: how long contexts affect models。
会话隔离:短期记忆是“随请求带历史”的机制,不同会话之间不能自动共享关键信息。
三、长期记忆:跨会话、跨时间的“持久存档”
它是什么:允许智能体存储、检索并利用跨越数天、数月甚至数年的信息。
实现思路(RAG):通常采用检索增强生成(RAG)。智能体把重要信息向量化(Embeddings)并存入数据库,回答时通过语义匹配检索相关片段,再提供给大模型参考。
常见分类:
- 情境记忆(Episodic Memory):记录具体“经历”。例如:“用户上周二在上海出差,提到喜欢当地咖啡”。
- 语义记忆(Semantic Memory):存储抽象“事实”。例如:“用户对花生过敏”。
- 程序记忆(Procedural Memory):沉淀“技能/SOP”。例如:学会调用某个特定 API 的步骤。
实操示例:Cherry Studio 的“全局记忆”
Cherry Studio 通过“全局记忆”实现长期记忆。
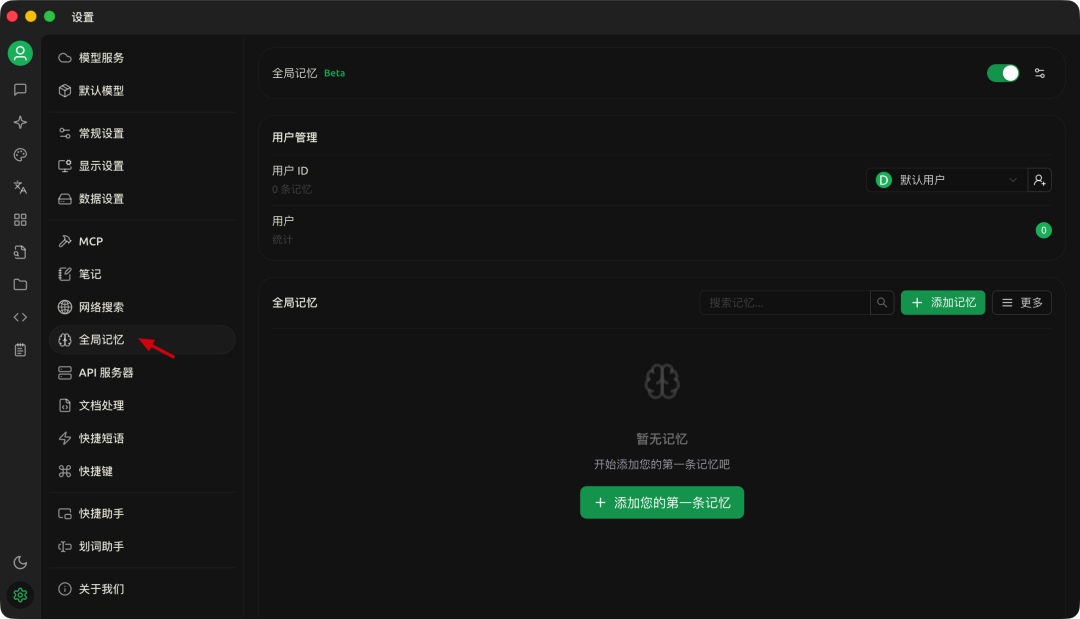
你既可以手动添加,也可以在智能体中开启自动记忆,让系统判断哪些信息需要保存并持久化。
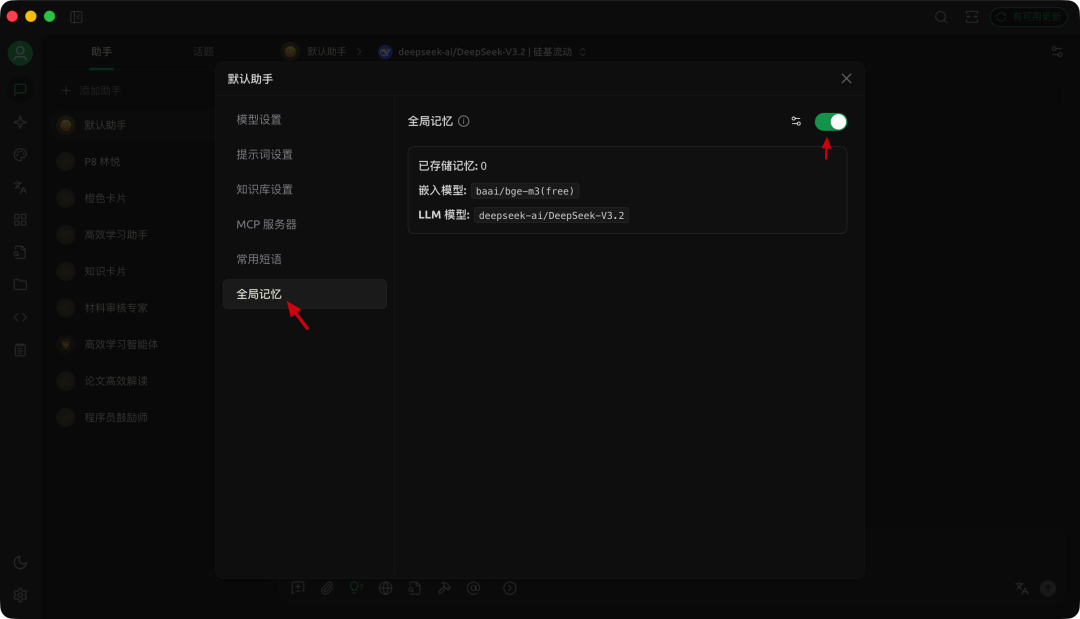
使用方式:在全局设置中开启“全局记忆”。
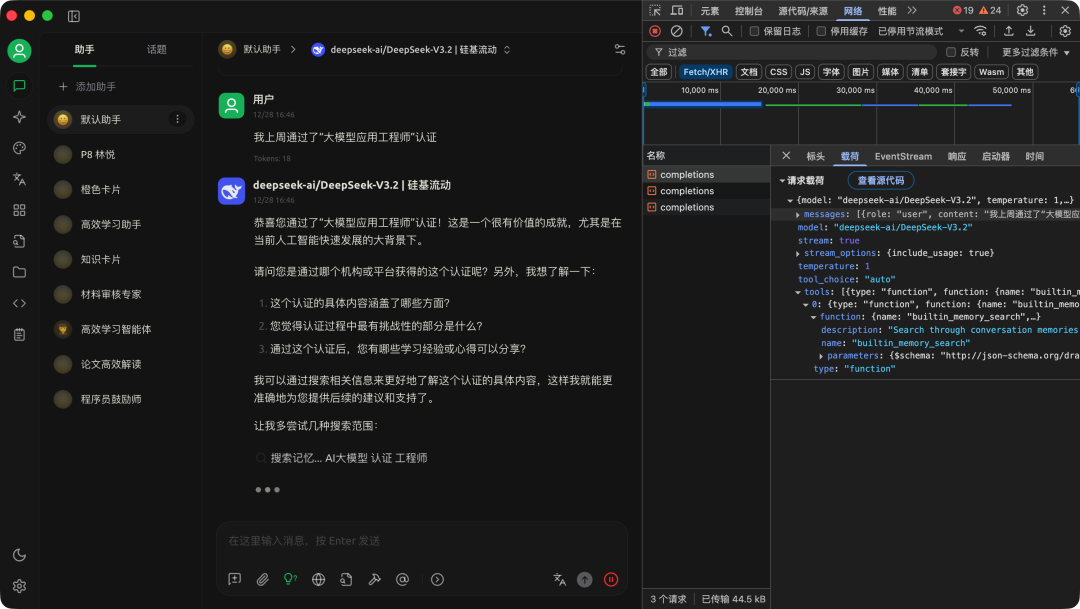
对话流程:用户发起对话时,系统会调用 Memory_Search 工具检索可能相关的记忆,把它们加入上下文,辅助大模型更好地回答。
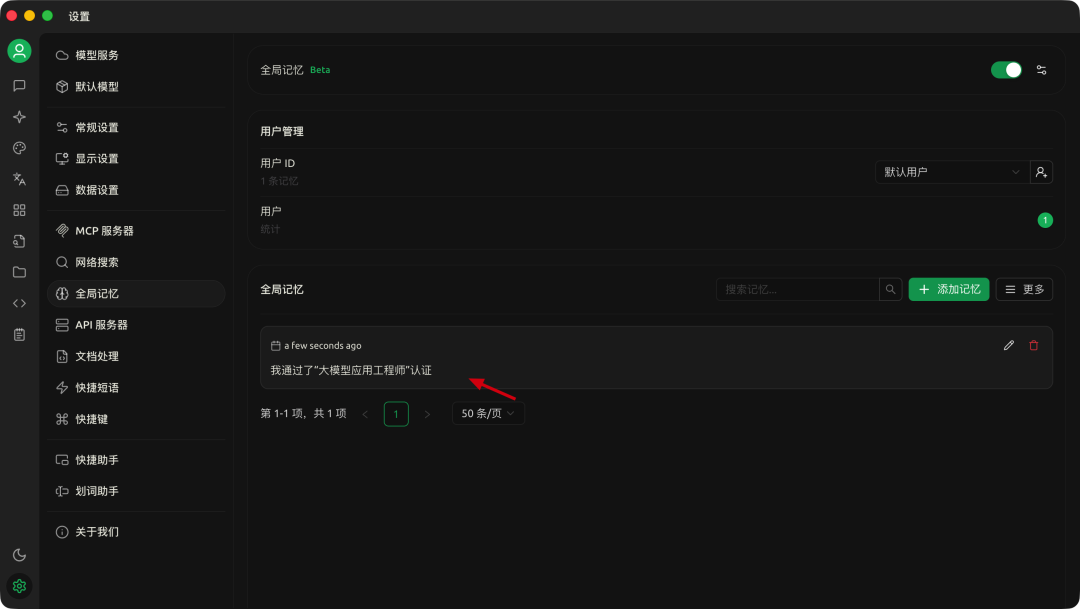
异步更新:回答完成后,系统会异步提取本次对话中的关键信息,如需新增、修改或删除记忆,会通过对应工具进行处理。
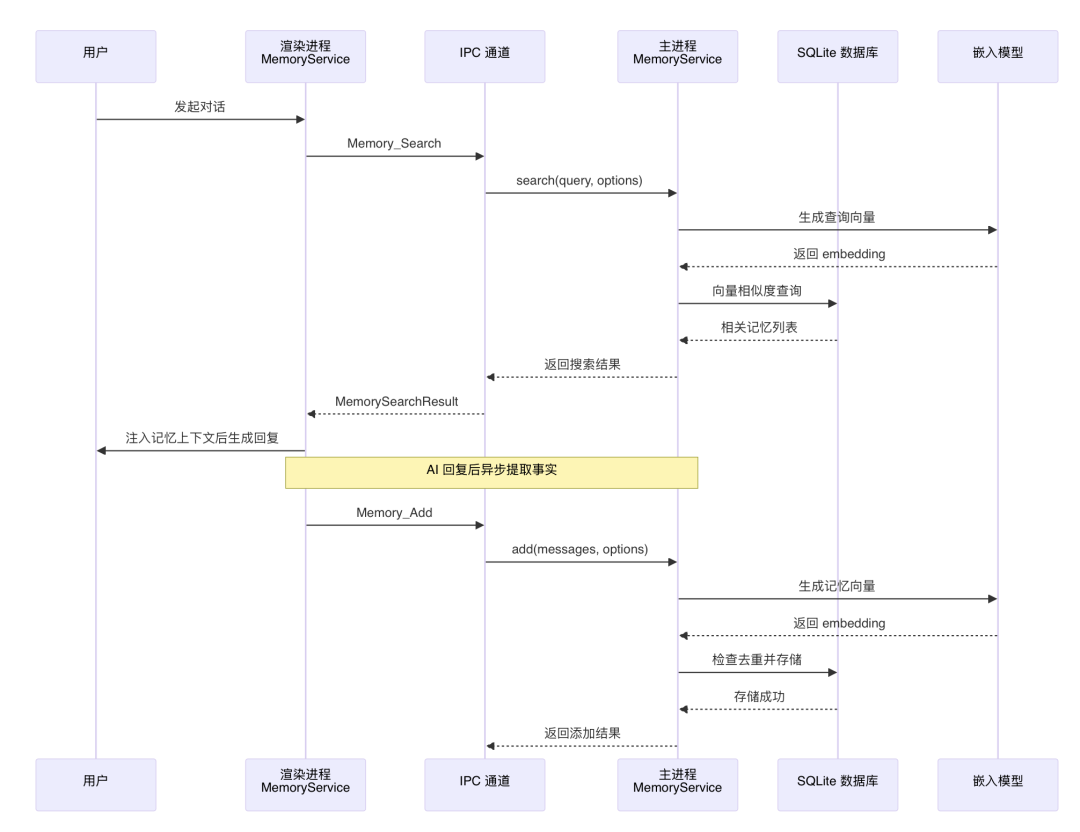
更多实现细节可参考 Cherry Studio 源码:https://github.com/CherryHQ/cherry-studio
长期记忆也有坑
- 自动记忆可能出错:若 AI 未与用户确认便自行写入记忆,可能留下错误信息。
- 不当“对齐”:部分模型在回答时会过度依赖检索到的记忆,导致结果跑偏,不符合用户当前意图。
一句话总结
短期记忆:靠在请求时携带“对话历史”实现,仅在当前会话内生效;窗口受限、成本与效果需权衡。
长期记忆:通过持久化存储(如向量数据库)和检索技术实现,可跨会话、跨时间复用信息。