作为一名长期做产品的用户,我几乎每天都会挑几款AI产品做深入体验。
本周把时间花在了 MiniMax 的新模型 M2.1 上。

核心看法很明确:M2.1 在多语言编程和移动/Web UI生成上有实质提升,响应速度也更快;但在商业套餐的额度设计上,
对高频使用者并不友好。
是否值得切换,取决于你是更看重“速度”还是“持续高频”使用。
这次更新的核心变化
功能重点:面向多语言编程场景,同时增强移动端与 Web 场景的 UI 设计与效果生成。
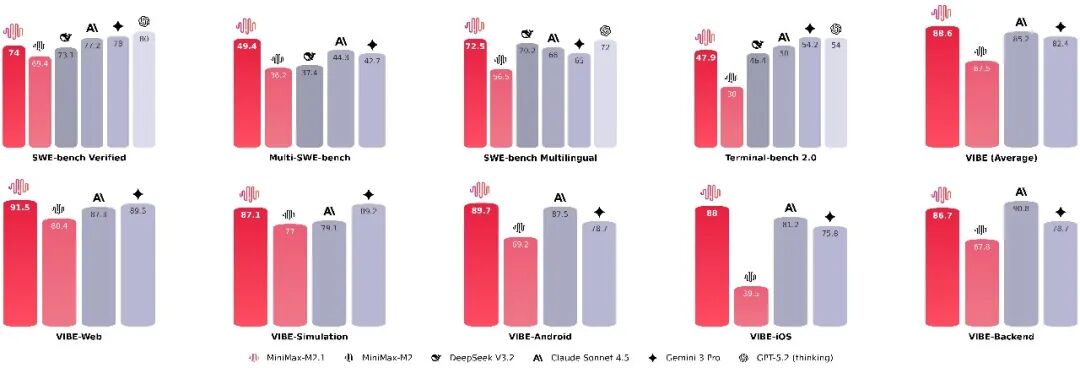
技术特征:官方强调更节省 token、Agent 调用更稳定、整体推理与生成效果更强。
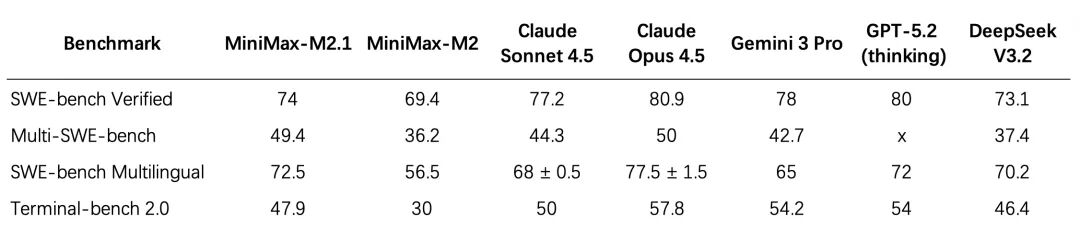
性能声明:官方测试显示,部分场景下超过 Anthropic Sonnet 4.5,并接近 Opus(信息来源为官方,实际表现仍需结合具体任务验证)。
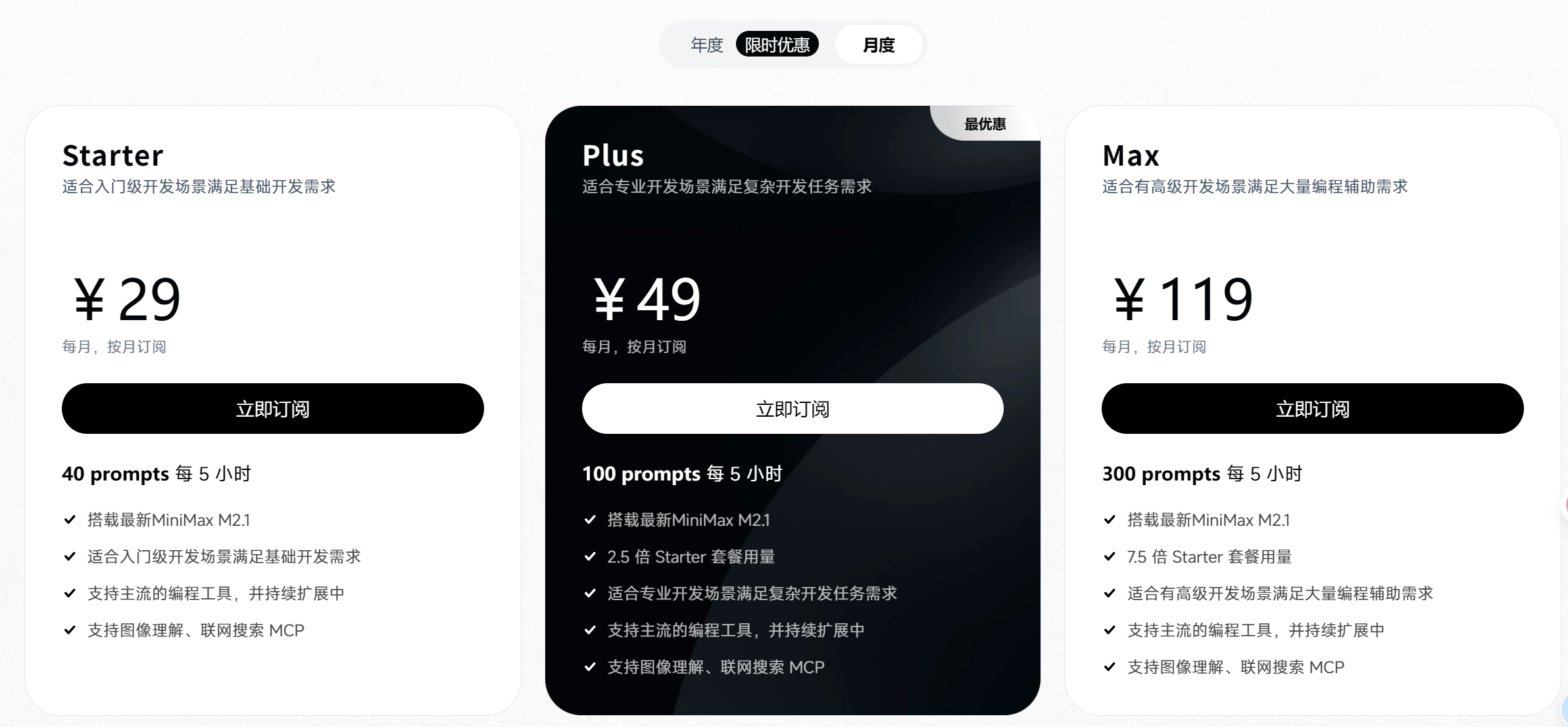
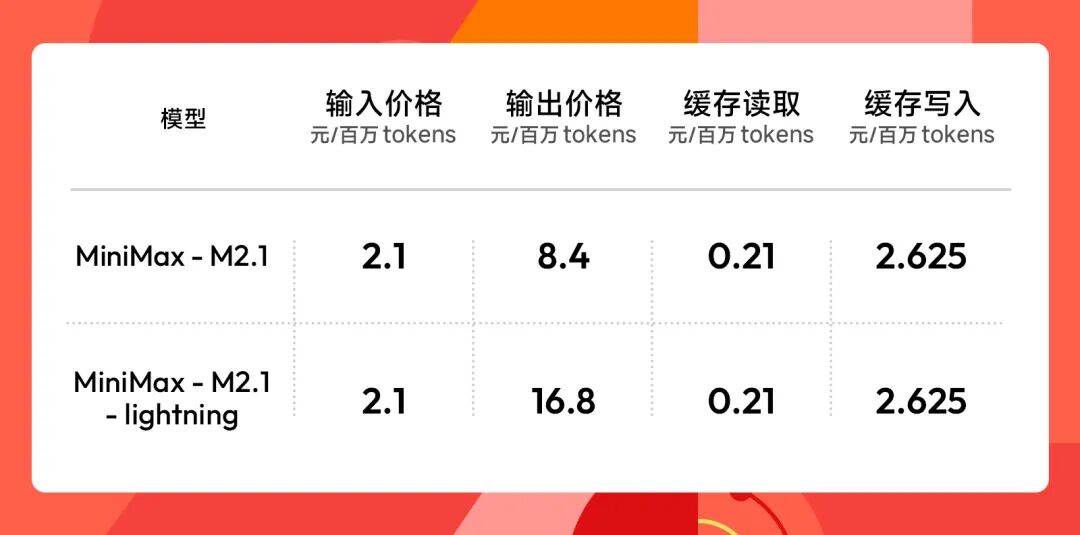
接入与价格:购买 Coding Plan 的用户可直接使用 M2.1,价格保持不变。购买链接:MiniMax Coding Plan
我的实际体验:速度很快,但不是“全场景碾压”
我用 M2.1 做了几类常见工作流:
- 跨语言代码生成(Python/TypeScript/Go 之间互转、小型工具脚本):响应明显更快,代码结构清晰,基本无需等待。
- 前端页面与组件草稿(移动端与 Web):能输出可运行的初版结构,样式与交互需要继续细化,但落地速度比我过去的同类模型要快。
- 多步骤 Agent 调用:连续调用的稳定性确实提升,长链路任务中中断情况减少(以我自己的流程为样本)。
和 GLM 4.7 的直接对比上,感受是“速度优势明显,但不同任务各有胜负”。例如,GLM 在部分中文场景下的语义理解与指令跟随更稳,而 M2.1 在代码生成的首轮产出速度上更有优势。没有绝对的赢家,选择更多是场景取舍。
套餐与使用门槛
MiniMax Plus 套餐:49 元,提供 100 次 prompt 调用。对高频用户而言额度偏紧,容易超额。
Coding Plan:支持使用 M2.1,价格不变(具体额度以官网为准)。
免费试用路径:Trae CN 国内版本已接入 M2.1,适合做初步体验。但我在使用中遇到性能和设计上的瓶颈,可能无法完全反映模型的最佳表现。
如果你每天都有较高调用量,套餐额度会直接影响可用性与成本。速度固然重要,但稳定的调用预算同样关键。
谁更适合用 M2.1
适合的场景:
强调首响应速度的敏捷开发与原型验证。
跨语言代码生成与多端 UI 初稿构建。
需要更稳定 Agent 长链路的自动化任务。
不那么适合的场景:
每天高频、大量调用(现有 Plus 套餐额度偏紧)。
对中文复杂业务语境深度理解有更强要求的任务(可与 GLM 4.7 对比后决定)。
对比概览
| 维度 | MiniMax M2.1 | GLM 4.7 | 备注 |
|---|---|---|---|
| 功能范围 | 多语言编程、移动/Web 场景的 UI 生成更突出 | 通用编程与中文理解能力强 | 两者均为通用大模型,可按任务对比 |
| 技术特征 | 强调 token 利用率与 Agent 稳定性 | 强调综合理解与生成能力 | 以官方说明与常规使用感受为准 |
| 速度体验 | 首轮代码产出更快 | 部分场景响应稍慢 | 与任务类型和上下文长度相关 |
| 表现声明 | 官方称部分场景超过 Sonnet 4.5、接近 Opus | 无直接官方对比 | 需以实测任务验证 |
| 套餐适配 | Plus 49 元/100 次,额度偏紧 | 更适合高频使用(具体以官网为准) | 预算与调用量决定适配性 |
| 试用路径 | 可通过 Coding Plan;Trae CN 可体验 | 官方渠道为主 | 第三方平台可能限制模型性能 |
获取与试用
购买与接入:MiniMax Coding Plan(M2.1 可用,价格不变)。
免费体验:可在 Trae CN 国内版本尝试 M2.1;适合初步感知,不适合严肃评估。
结语
把产品落到使用场景,结论会更清晰:M2.1 的速度和多语言编程体验值得关注,但套餐额度决定它是否适合你的日常。
我的做法是:速度敏感的原型与跨语言任务用 M2.1,高频且稳定的日常工作继续用更宽松的套餐方案(如 GLM 4.7)。
如果你还在观望,建议先用第三方做初步体验,再在正式环境做针对性验证,避免单一声明影响判断。