DeepSeek登上了《Nature》封面。
要知道,《Nature》是全球顶级的科学期刊,能在上面发表AI成果的,几乎都代表着划时代的突破。之前能上去的案例,像 AlphaGo、AlphaFold,都是AI发展史上浓墨重彩的一笔。而这一次,轮到了一家国内大模型厂商。
作为一个每天泡在各种AI产品里的产品经理,我第一反应是:为什么是DeepSeek? 它到底做对了什么,才有资格和这些重量级成果并列?
我结合论文和之前的跟进体验,总结了三点核心原因。
1. 成本
DeepSeek-R1 的训练成本只有 29万美元(约200万人民币)。
对比一下:Grok-4 的训练成本是 4.9亿美元,足足是 DeepSeek-R1 的 1689倍。

什么意思?同样的钱,能训练一个 Grok-4,还是能训练 1600多个 DeepSeek-R1。这不仅仅是“便宜”,而是颠覆了整个行业对于大模型训练“必须烧钱”的认知。
还记得今年年初,DeepSeek-R1 发布时,美股都被震了一下。很多人不信,质疑是不是“炒作”。结果大量同行去复现,最后证明:真·能跑出来。
2. 数据
当时还有不少声音怀疑 DeepSeek 是不是偷偷蒸馏了别人的模型。
结果团队直接把训练数据集细节公开了,用行动回击了这些质疑。
这套数据大约有 15.4万道题,覆盖五大类:
-
数学:2.6万题,专注推理计算
-
编程:2.5万题(算法竞赛题 + 代码修复),提升代码生成与调试能力
-
STEM:2.2万题,涵盖物理、化学、生物
-
逻辑:1.5万题,训练推断与分析
-
通用:6.6万题,创意写作、问答、角色扮演、无害性评估等
这种透明度,在大模型圈其实很罕见。也正因为如此,Nature 才认可了它的原创性和科学贡献。
3. 算法
最让我感兴趣的,是 DeepSeek 真正把强化学习用在推理能力提升上,而且是第一个做成功的。
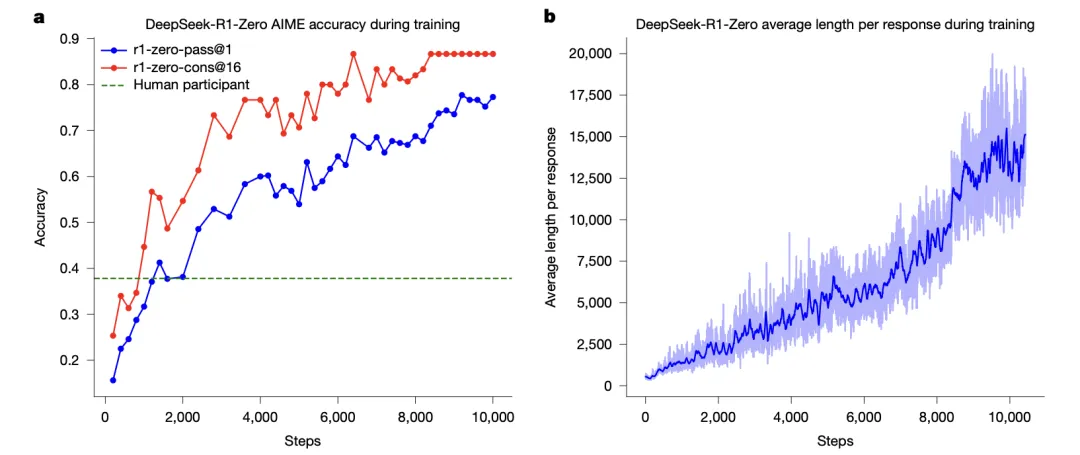
传统的做法,需要大量人工标注推理过程,成本高得吓人。DeepSeek 走的是“自演化”路线:
-
只看最终答案是否正确,把它作为奖励信号
-
底座用 DeepSeek-V3-Base
-
算法用 GRPO 强化学习
-
再通过少量冷启动 + 拒绝采样 + 监督微调,把模型一步步打磨出来
这种做法有点像“把学生丢进考场,只看最后成绩”,结果还真让模型学会了“如何思考”。
更关键的是,这一突破不仅节省了训练成本,还让 DeepSeek-R1 成为了当时最强的推理模型之一。甚至和闭源的 O1 相比,也丝毫不逊色。
感想
说实话,我在体验过那么多 AI 产品之后,这次还是被 DeepSeek 震撼到了。
它证明了:顶级大模型,不一定要靠烧钱砸出来。
它用行动告诉大家:开源 + 透明,也能走上顶级舞台。
它还打开了一条新路:强化学习不止能玩游戏,还能让模型学会更强的推理。
如果说 2025 年中国 AI 技术的里程碑事件之一是什么,我觉得 DeepSeek-R1 肯定榜上有名。
从某种程度上,它让闭源阵营的“老大哥们”意识到:开放和创新的结合,可能才是最有杀伤力的武器。
文章地址: