轻微的笑声和语调起伏,几乎能听出“人味”。
这个项目叫 OpenAudio(原名 Fish-Speech)。
它不仅是一个高质量的开源 TTS 模型,更像是“情感可控”的语音生成平台。
在 TTS 技术还停留在“声音自然”阶段时,OpenAudio 已经开始探索“声音表达”的下一步。
项目介绍
OpenAudio 是一个由 开发的开源 TTS 系统, 目标是打造一个能与商业级产品(如 OpenAI Voice Engine、ElevenLabs)抗衡的多语言语音合成模型。
它的特别之处在于:
-
不只是能「说得准」,还可以「说得像人」。
-
支持多语言、情感、语调、特殊音效标记,让生成语音更有表现力。
-
采用大语言模型(LLM)架构训练,实现更强的语义理解与表达能力。
功能亮点
高质量语音合成
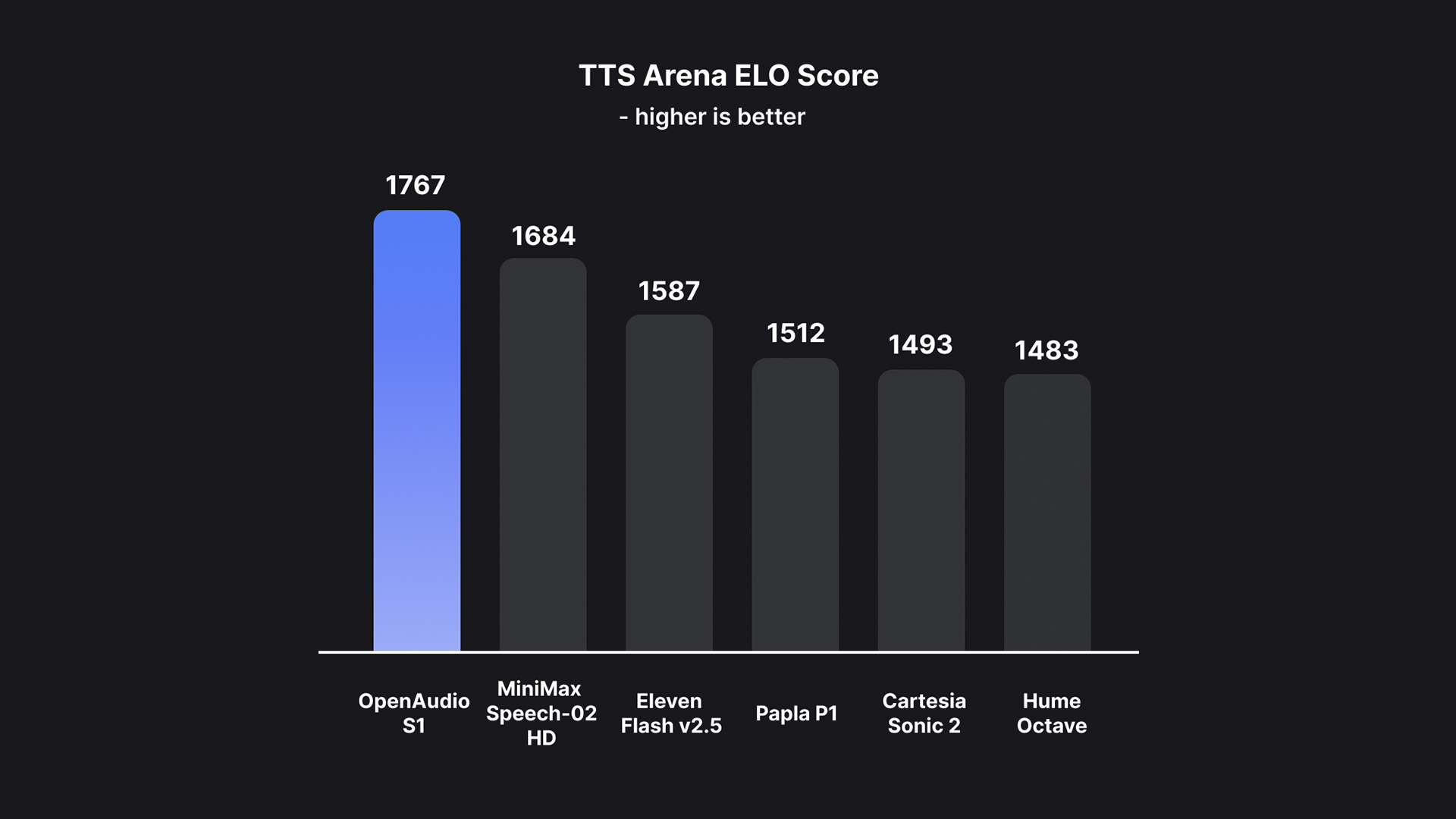
在 Seed-TTS Eval 评测中,OpenAudio-S1 模型在英文文本上取得:
-
WER(词错误率)0.008
-
CER(字符错误率)0.004 这意味着它的发音准确率几乎逼近完美。
可控的情感与语调
你可以在文本中直接插入情感标记,例如:
-
基本情感:
(angry)、(sad)、(excited) -
高级情感:
(disdainful)、(anxious)、(hysterical) -
语调标记:
(shouting)、(whispering) -
特殊音效:
(laughing)、(sobbing)
这种控制方式让生成语音不仅自然,更能表达复杂的情绪氛围——这在虚拟角色配音、游戏对白、虚拟主播等场景中极具潜力。
多语言与跨语言支持
无需音素标注即可处理多语言文本,目前支持: 英语、中文、日语、韩语、法语、德语、阿拉伯语、西班牙语等。 你可以直接复制粘贴混合语言文本,它都能正确朗读。
双模型架构
| 模型 | 参数量 | 特点 |
|---|---|---|
| OpenAudio-S1 | 40亿 | 旗舰版本,功能最全,质量最高 |
| OpenAudio-S1-mini | 5亿 | 精简版,推理更快,支持 Hugging Face 部署 |
两种模型都集成了 RLHF(基于人类反馈的强化学习),进一步提升了自然度。
部署与使用指南
在线体验
-
可直接生成语音
-
或使用 Hugging Face Space 测试 mini 模型
本地部署
-
支持 Linux / Windows(macOS 即将支持)
-
提供 Gradio WebUI 与 PyQt6 GUI 两种推理界面
-
在 NVIDIA RTX 4090 GPU 上,实时因子约为 1:7,推理速度极快
部署过程相对简单:
git clone https://github.com/fishaudio/fish-speech
cd fish-speech
pip install -r requirements.txt
python app.py
即可启动 WebUI 界面进行推理。
适用场景
-
AI 配音 / 内容创作:为视频、播客、虚拟人物生成多情感语音
-
游戏对白 / NPC 对话:可控语气让游戏角色更生动
-
多语言教学 / 语言训练:自然发音与语调帮助学习者更好模仿
-
智能体语音输出:让 Agent 不再单调机械
对于开发者而言,它不仅是一个工具,更是一种新的交互可能性。
技术细节
| 模块 | 技术特性 |
|---|---|
| 模型架构 | LLM 驱动的 TTS(非音素依赖) |
| 数据训练 | 多语言 + 情感语料 |
| 推理加速 | 支持 torch.compile 优化 |
| 模型评估 | Seed-TTS 指标(WER、CER) |
| 前端框架 | Gradio + PyQt6 GUI |
总结
我认为 OpenAudio 代表了 TTS 技术的一个重要分水岭: 过去的目标是“让机器会说话”; 现在的目标是“让机器会表达”。
对于开发者而言,它的开源意义不仅在于技术突破,更在于开放了“语音情感表达”的新范式。 如果你正在做智能体、内容生成或虚拟交互相关项目,OpenAudio 值得你亲手跑一遍。
项目资源:
GitHub:https://github.com/fishaudio/fish-speech
文档: