Gemini 2.5 计算机使用模型(Computer Use Model) ,这是一款基于Gemini 2.5 Pro视觉理解与推理能力构建的专用模型,旨在赋予AI智能体(agent)与图形用户界面(GUI)直接交互的能力——就像人类一样进行点击、打字和滚动操作。
这意味着“AI终于开始学会‘用电脑’了。”
这次更新其实挺有里程碑意义的。过去我们习惯让AI通过API或者文本指令执行任务,但很多操作(比如网页登录、表单填写、文件上传)依然得靠人去点。
现在,谷歌直接让AI拥有“手和眼”——它能识别界面元素,看懂屏幕上的按钮、表单和下拉菜单,然后像人类一样去点击、输入、滚动。
官方把这称为 Computer Use Model,本质上是一个能让智能体直接与图形用户界面(GUI)交互的能力层。目前它已在 Gemini 2.5 Pro 中上线,并开放给开发者,通过 或 即可使用。
这套系统是怎么运作的?
简单来说,它是一个“观察—行动—反馈”循环系统(loop)。
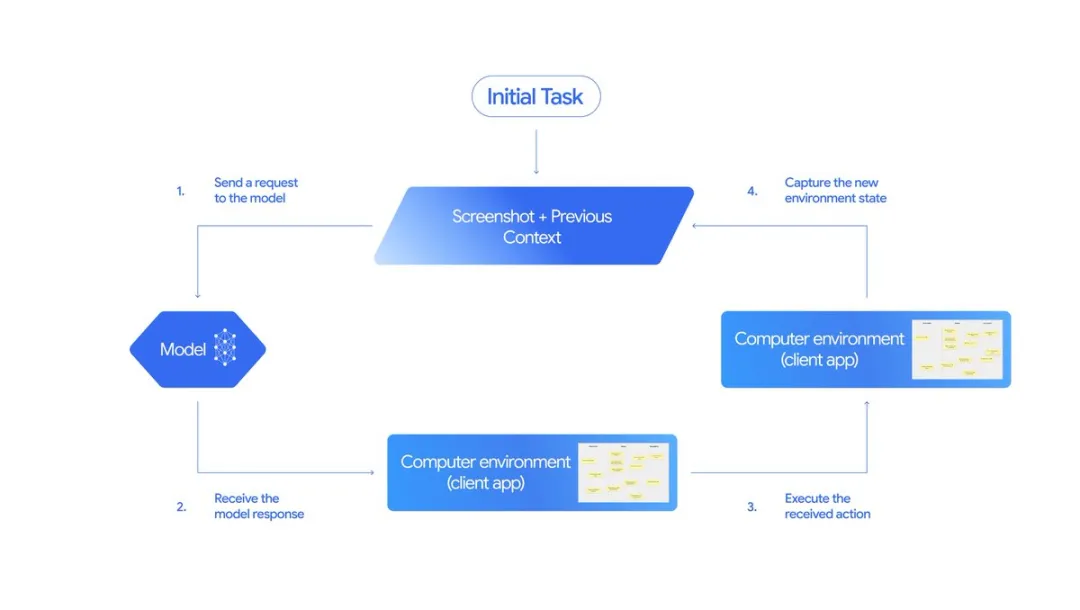
整个过程可以拆成四步:
输入阶段:模型接收到用户请求、当前屏幕截图以及最近的操作历史。开发者还能设置“禁止某些UI操作”或添加自定义函数。
分析与响应:AI分析这些输入后,生成具体动作,比如点击某个按钮、输入文字、或下拉选择。若是敏感操作(如支付),AI会自动请求用户确认。
执行操作:客户端根据模型返回的指令执行实际操作。
反馈与循环:操作完成后,系统会截取新的屏幕并反馈给AI,进入下一轮循环,直到任务结束或中止。
这个设计非常像人类在操作电脑时的思考方式——“看一眼、点一下、观察结果、再点一下”。
目前谷歌主要针对 网页操作 进行了优化(比如自动化Web任务、登录后操作等),但在移动端控制上也表现出不错的潜力。
性能:延迟低、精度高
从谷歌公开的测试结果看,Gemini 2.5 的Computer Use模型在多项基准测试中表现领先。
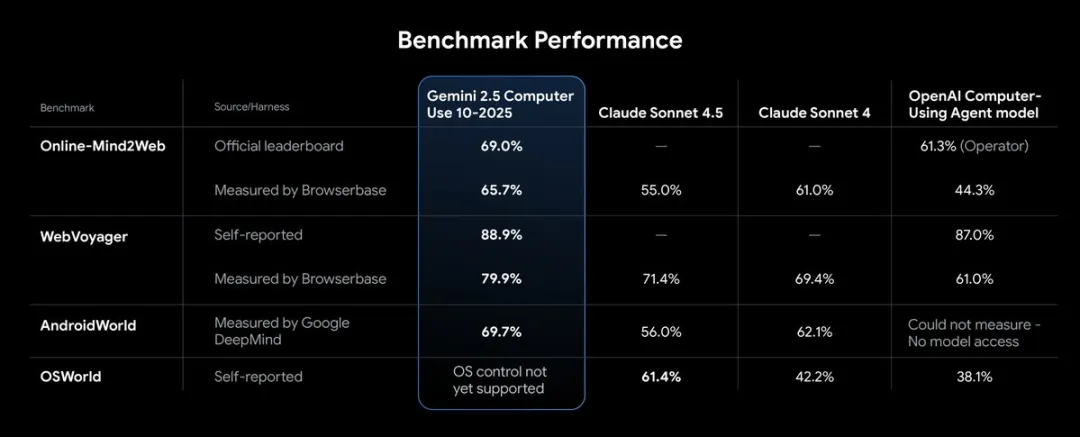
尤其是在 Browserbase 的 Online-Mind2Web 测试平台 上,浏览器控制的质量和延迟表现均为当前最优。
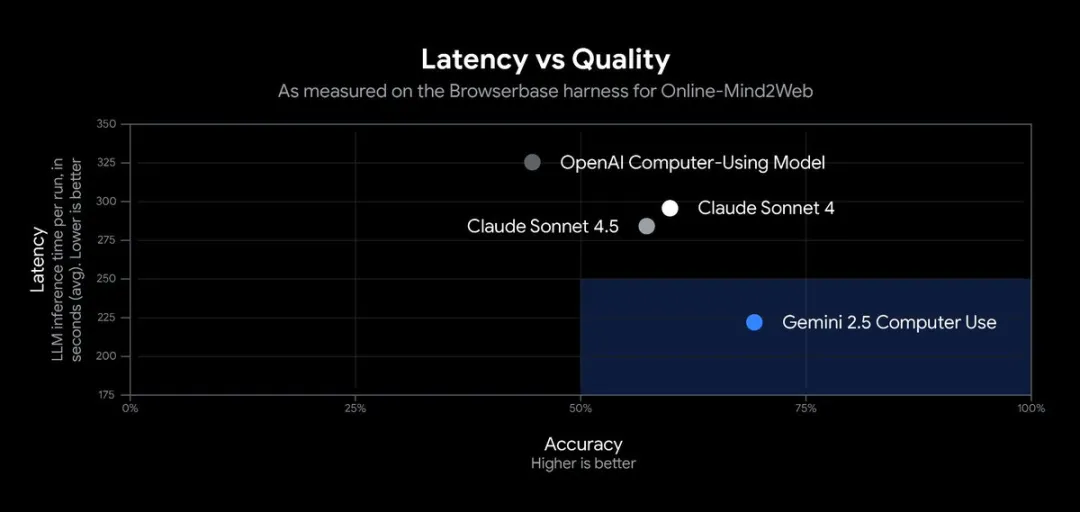
这意味着AI执行网页任务时更“流畅自然”,延迟更低,误点率更少——这一点在Agent自动化工作流中非常关键。
安全:三道保险
让AI能自由点击和输入,听起来很酷,但也很危险。谷歌在设计时非常谨慎,加入了多层安全防护:
模型内安全训练:在模型训练阶段就内置了防滥用机制,避免AI乱点、误操或被恶意诱导。
逐步安全服务(Per-step Safety Service):在AI每次执行动作前,都由外部安全服务审查其合理性。
系统指令控制(System Instructions):开发者可自定义规则,比如要求AI在执行支付、登录等高风险操作时必须暂停并征得用户确认。
这些机制能有效防止AI越权执行、绕过验证码、甚至控制医疗设备等高风险行为。
总结
Gemini 2.5 的Computer Use模型标志着智能体进入一个新阶段:从“语言理解”进化为“可视操作”。
我觉得这是一件值得关注的事。
它不只是AI性能的提升,更是人机交互方式的一次变革。未来的AI助手可能真的会帮你: 打开网页、登录账号、填写报表、提交工单,就像一个隐形的实习生,效率惊人。