OpenCode 近日正式发布 OpenCode Data Report,开发者现可通过官方页面实时获取大模型调用数据。报告涵盖了 2026 年 4 月 18 日至 6 月 12 日期间的编码代理领域数据,揭示了当前 AI 编码市场的"性能 - 成本"博弈格局。
数据显示,DeepSeek V4 系列凭借极低的推理成本和高缓存命中率占据主导地位,而 Kimi (Moonshot) 和 GLM-5.1 也快速崛起。本文将基于 OpenCode 官方数据,对各大模型的表现、成本及市场趋势进行深度解析。
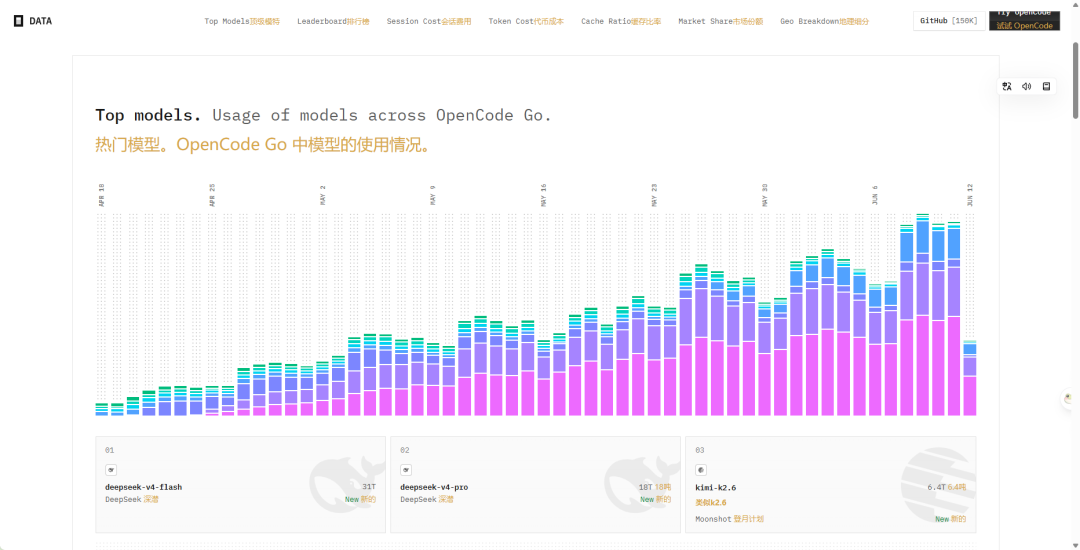
1. Top Models:模型排名
按令牌使用量(Token Usage)排序,OpenCode 平台上前几名的模型分别是:
- DeepSeek-v4-Flash:31T(占比最高)
- DeepSeek-v4-Pro:18T
- Kimi-K2.6:6.4T
- GLM-5.1:2.4T
- Qwen3.6-Plus:2.3T
DeepSeek V4 系列优势明显,累计约 49T 的使用量。单次会话平均使用的令牌数方面,DeepSeek-Flash 表现突出(约 6.6M tokens)。新发布模型如 Kimi 和 DeepSeek 用户增长迅速,而部分老模型同比增速显著。
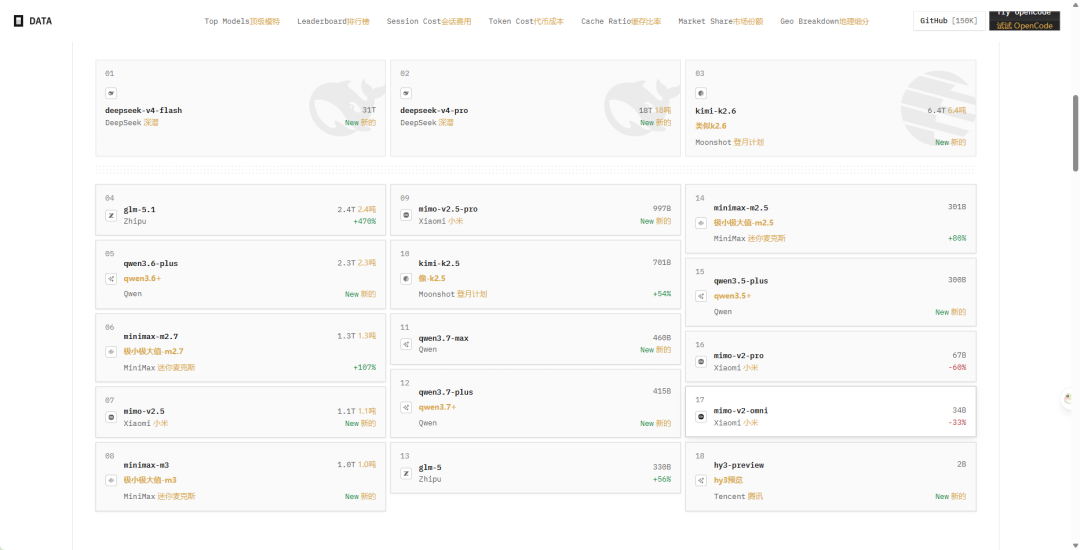
2. Session Cost:会话成本分析
会话成本即一次编码交互的平均花费。OpenCode 数据显示,各模型的平均每会话成本差异巨大:
| 模型 | 会话成本 ($) | 估算令牌/会话 |
|---|---|---|
| mimo-v2.5 | $0.0579 | ~5.8M |
| deepseek-v4-flash | $0.0662 | ~6.6M |
| mimo-v2.5-pro | $0.4775 | ~4.8M |
| deepseek-v4-pro | $0.5501 | ~6.9M |
| qwen3.7-plus | $0.6371 | ~7.0M |
| minimax-m3 | $0.7293 | ~7.3M |
| qwen3.6-plus | $0.7597 | ~7.6M |
| kimi-k2.6 | $0.9663 | ~3.6M |
| glm-5.1 | $1.1666 | ~1.4M |
| qwen3.7-max | $1.5882 | ~1.9M |
计算公式:每会话成本 ≈ 输入令牌数×输入价格 + 输出令牌数×输出价格 - 缓存节省。OpenCode 提示基础定价为输入 $1.74/1M、输出 $2.52/1M、缓存令牌 $0.05/1M。在高缓存率条件下,多数输入令牌按 $0.05 而非 $1.74 计费,大幅降低成本。
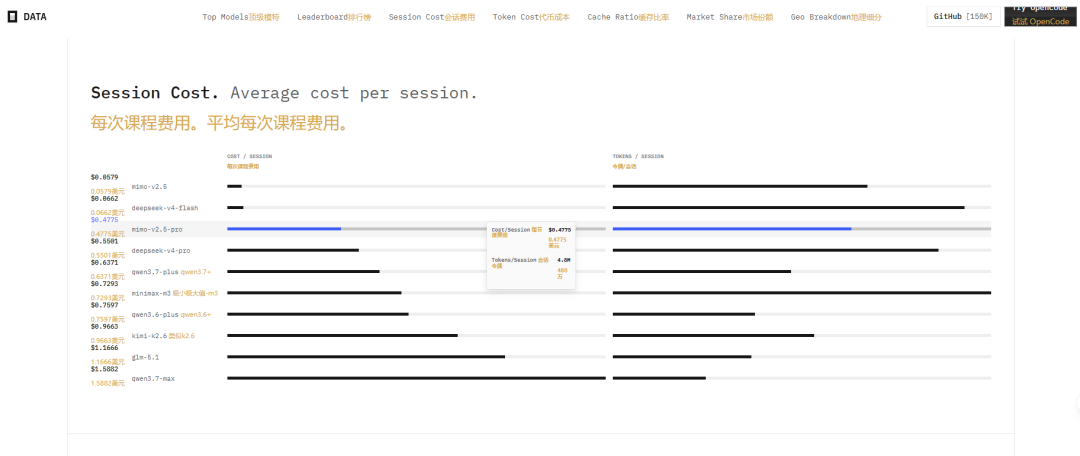
3. Token Cost:每百万令牌价格
各模型的令牌定价差异明显,决定了规模化使用成本。部分模型的每 1M tokens 价格(美元)如下:
- DeepSeek-v4-Flash:$0.01
- MiMo-v2.5:$0.01
- DeepSeek-v4-Pro:$0.08
- MiniMax-m3:$0.09
- MiMo-v2.5-Pro:$0.10
- Qwen3.7-Plus:$0.18
- Kimi-K2.6:$0.24
- Qwen3.6-Plus:$0.26
- GLM-5.1:$0.41
- Qwen3.7-Max:$0.84
DeepSeek V4 系列和 MiMo-v2.5 拥有极低的定价($0.01),而 Qwen3.7-Max 高达 $0.84,价格差距高达 80 倍以上。
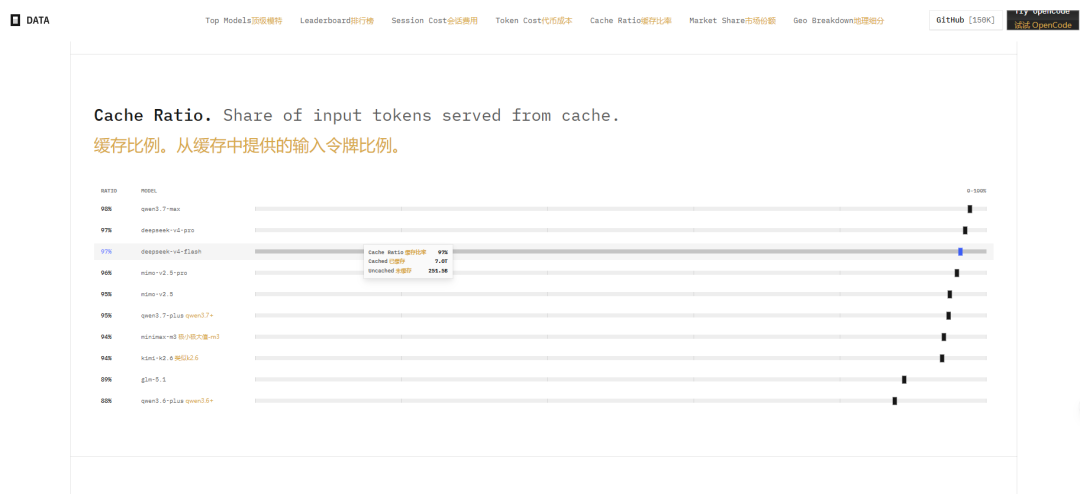
4. Cache Ratio:缓存命中率
输入令牌缓存命中率是降低成本的关键。数据表明:
- Qwen3.7-Max:98%(榜首)
- DeepSeek-v4-Pro:97%
- DeepSeek-v4-Flash:97%
- MiMo-v2.5-Pro:96%
- MiMo-v2.5:95%
- Qwen3.7-Plus:95%
- MiniMax-m3:94%
- Kimi-K2.6:94%
- GLM-5.1:89%
- Qwen3.6-Plus:88%
整体输入缓存命中率约为 97%,累计缓存令牌 7.0T。命中率最高的是 Qwen3.7-Max 和 DeepSeek 系列。高命中率意味着实际使用成本远低于名义价格。
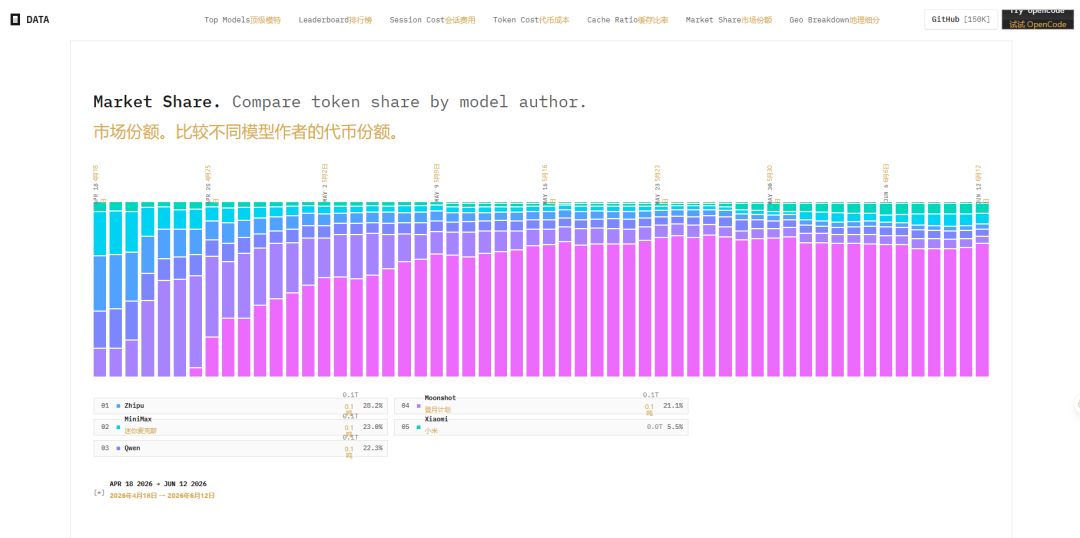
5. Market Share:模型作者市场份额
按模型作者汇总的令牌市场份额排名前五:
| 排名 | 作者/品牌 | 份额 |
|---|---|---|
| 1 | Zhipu (GLM) | 28.2% |
| 2 | MiniMax | 23.0% |
| 3 | Qwen (阿里) | 22.3% |
| 4 | Moonshot (Kimi) | 21.1% |
| 5 | Xiaomi | 5.5% |
Zhipu 的 GLM 系列占据最多令牌市场(28%),其次是 MiniMax (23%)、阿里 Qwen (22%)、Moonshot Kimi (21%)。尽管 DeepSeek 在单模型上用量巨大,但其作者不在前五榜单中,说明尚未形成庞大的"作者"品牌效应。
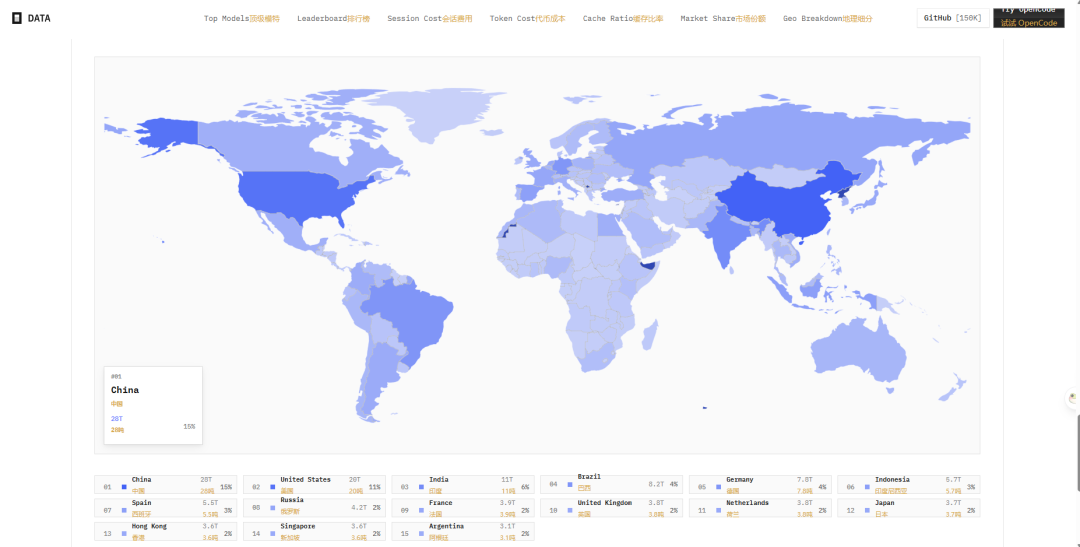
6. Geo Breakdown:地理分布
OpenCode 官方列出了各国令牌使用量前 15 名:
- 中国:28T (15%)
- 美国:20T (11%)
- 印度:11T (6%)
- 巴西:8.2T (4%)
- 德国:7.8T (4%)
中国用户使用量最高(占 15%),美国次之(11%)。亚洲地区(中国、印度、日本、印尼、香港、新加坡)和北美占比靠前。
7. 深度分析:为什么是 DeepSeek 和 Qwen?
DeepSeek 系列优势原因
DeepSeek V4-Flash/Pro 在各项指标上表现卓越。其关键优势在于:
- 成本极低:Flash 版价格低至 $0.01/1M。
- 长上下文:提供 1M token 长上下文,有效支持大型会话。
- 集成优化:与 OpenCode 等主流编码代理深度集成。
- 高缓存命中:97% 的命中率意味着大部分请求可以从缓存快速响应。
Qwen3.7-Max 高缓存命中率原因
Qwen3.7-Max 缓存命中率高达 98%,可能原因包括:在 OpenCode 内多作为默认模型使用,用户请求具有高度相似性和可重用性;Qwen 系列强调一致性和稳定性,答复标准化,有利于缓存匹配。
Kimi 与 GLM 市场份额对比
Zhipu (GLM) 的市场份额(28.2%)略高于 Moonshot (Kimi)(21.1%)。GLM-5.1 作为大型通用模型,用户基础更广;Kimi 系列虽为新模型,但增长显著。GLM 目前领先,但 Kimi 增速也快。
8. 策略建议
基于 OpenCode 数据,对从业者的建议:
- 关注低成本高效模型:优先采用 DeepSeek-V4 等低推理费率模型。
- 利用缓存策略:尽可能复用相同上下文输入,或加强模型侧的上下文缓存。
- 关注区域偏好:中国用户倾向于 GLM/Kimi,英语市场可能青睐 Qwen/DeepSeek。
- 跟踪市场动态:模型排名变化迅速,建议定期基准测试新模型。
- 重视模型差异化:结合具体用例需求选择模型,不应单纯以价格为唯一判断。
总体而言,缓存技术与成本控制是当前开源编码代理市场竞争的核心。