面壁智能发布MiniCPM-V 4.6,这是MiniCPM-V系列端侧多模态家族中体量最小的新成员,整体参数规模仅约1.3B,但在性能和推理效率上表现突出。

1B参数意味着什么?
模型参数量大致决定了硬件要求。1B量级意味着手机、普通笔记本电脑都能运行,不需要专用服务器或高端显卡集群。
过去能在手机上跑的多模态AI,要么能力有限,要么体验不佳。MiniCPM-V 4.6改变了这一现状。
部署到手机上,整个模型包仅2.5GB。token生成速度快,图片识别描述准确,本地运行的体感流畅,少了网络延迟的等待感。
性能对比
在1B参数量级,主要竞品是阿里的Qwen3.5-0.8B(0.8B参数)和谷歌的Gemma4-E2B-it。MiniCPM-V 4.6全面领先。
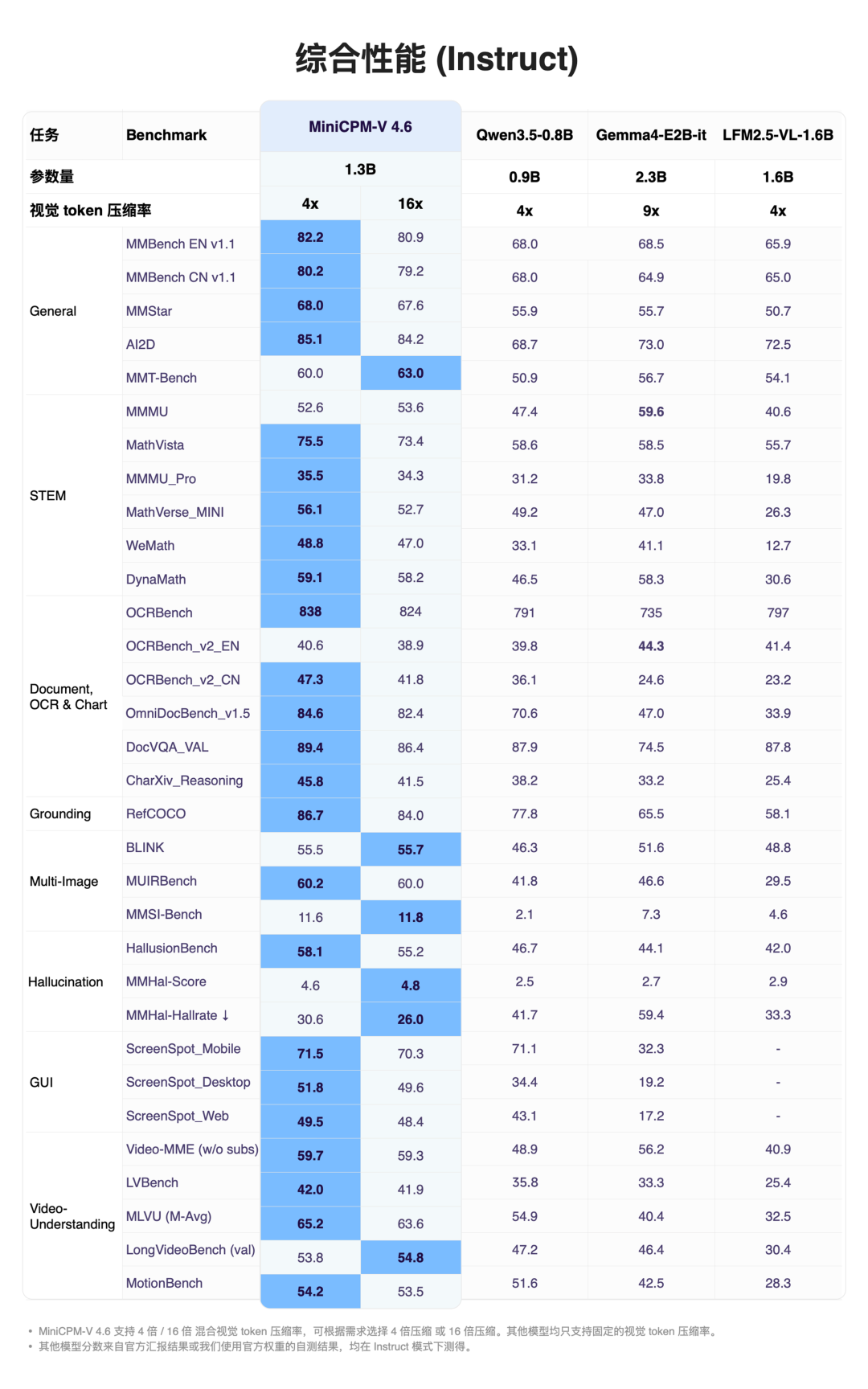
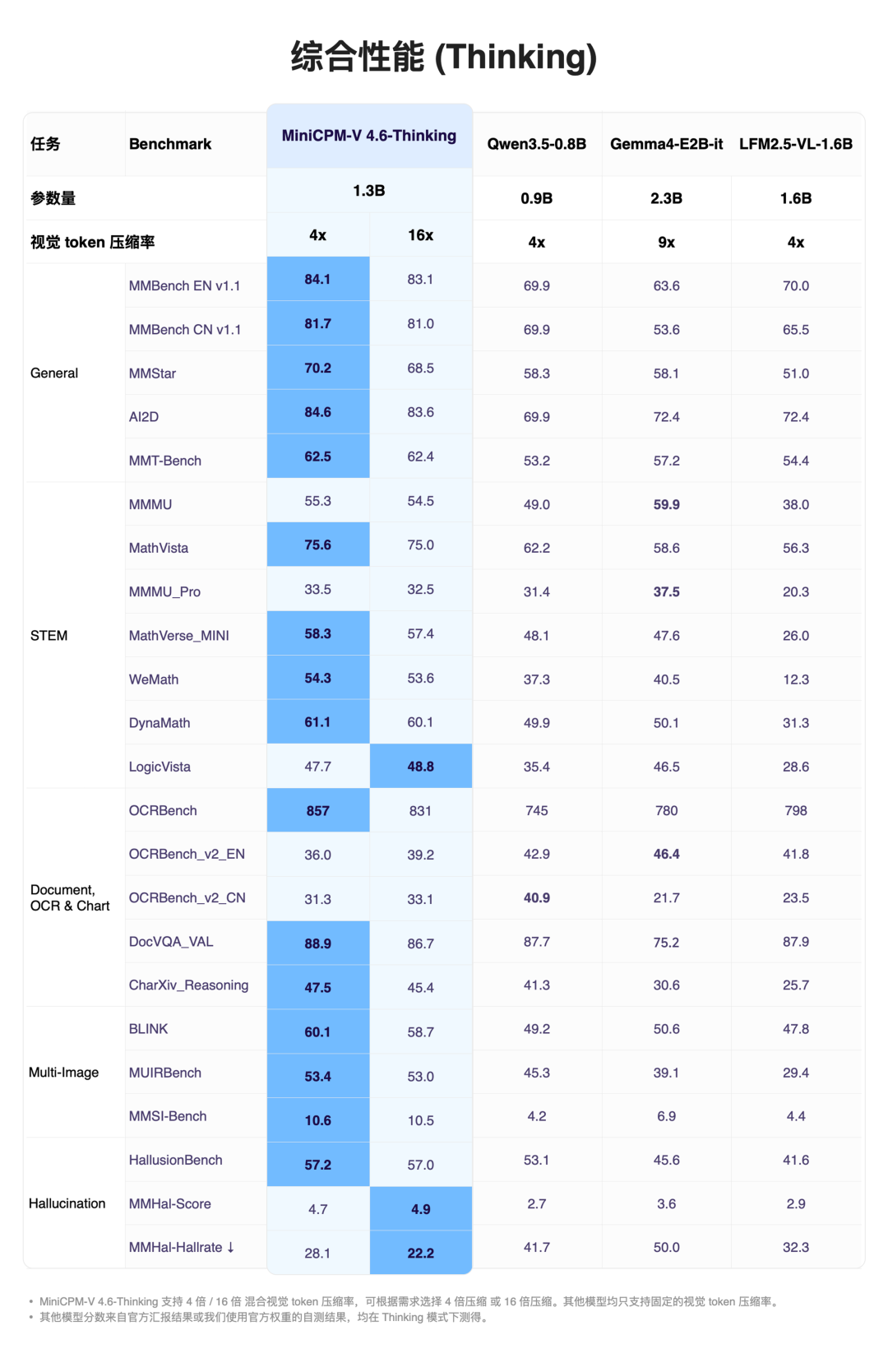
多模态任务综合能力
MiniCPM-V 4.6在多模态任务评测中表现优于Qwen3.5-0.8B和Gemma4-E2B-it。
效率基准
MiniCPM-V 4.6仅用了Qwen3.5-0.8B 2.5%的token消耗量,就超过了它的得分。同样的一道题,它用了对方1/40不到的"思考量",就答得更好。
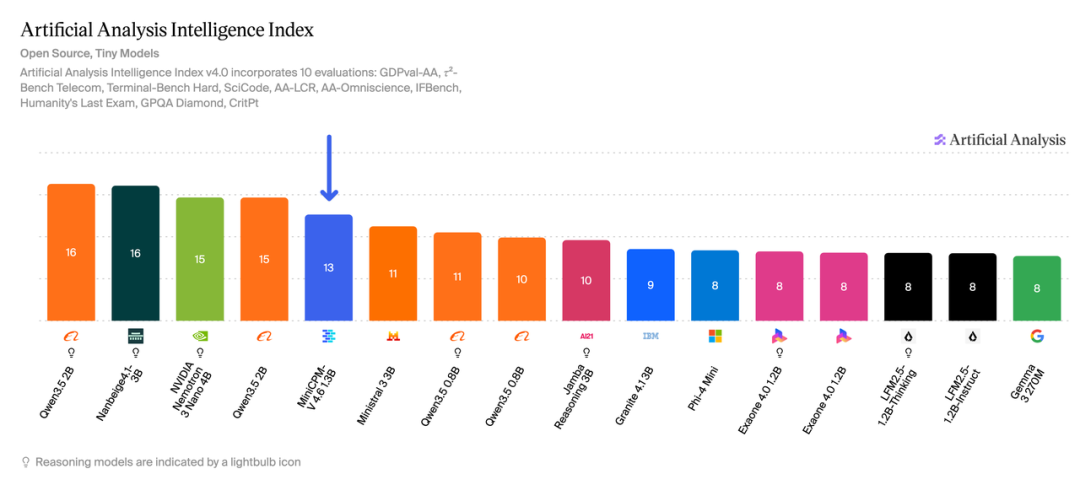
这背后的规律被称为"密度定律"——用更少的计算量,完成更多的事。该理论2024年已发表在Nature子刊上。
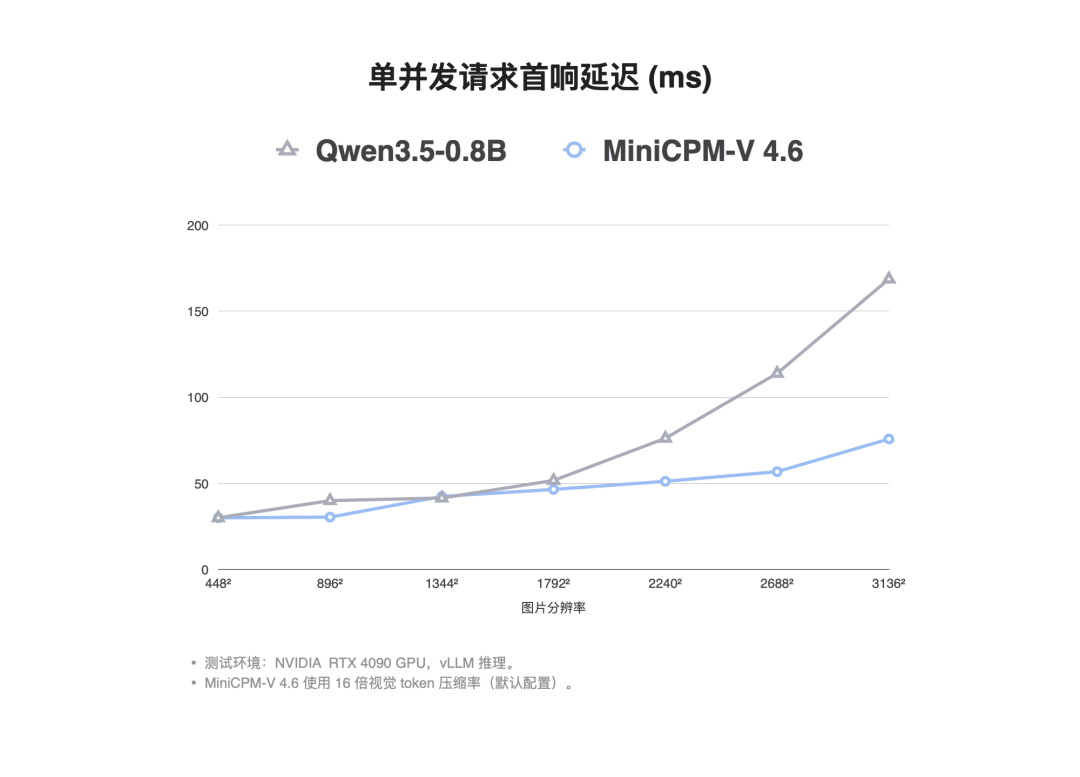
推理速度
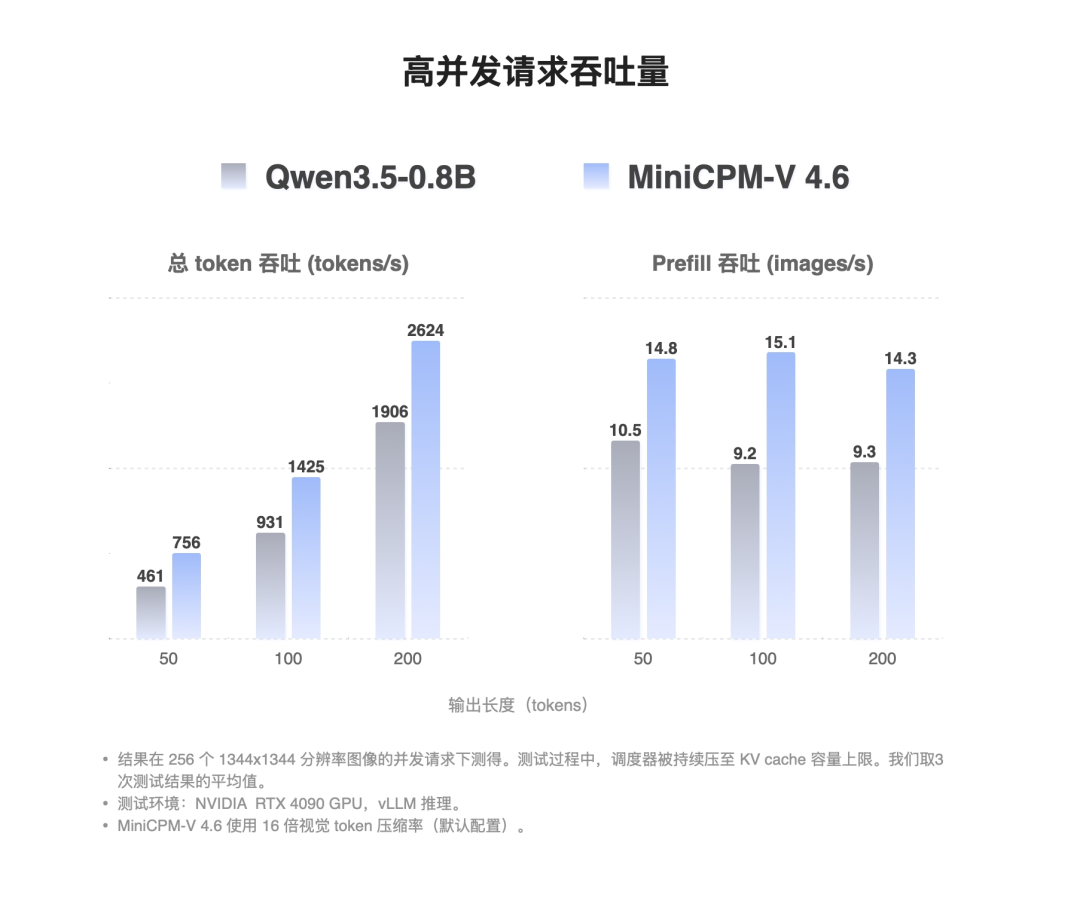
处理一张3136×3136分辨率的高清图片,首响延迟仅75.7毫秒,比Qwen3.5-0.8B快2.2倍。
在高并发吞吐上,单卡可达2624 token/s、14.3张/s的1344²图片处理能力(输出长度为200token时),是Qwen3.5-0.8B的1.5倍。
底层技术创新
ViT架构改造
面壁智能联合清华大学团队研发的LLaVA-UHD v4,将token压缩步骤提前到ViT(视觉编码器)内部。传统做法是在ViT处理完图像后才压缩token,而新架构让视觉编码器在处理图像过程中就降低token数量,计算量直接降低约50%。
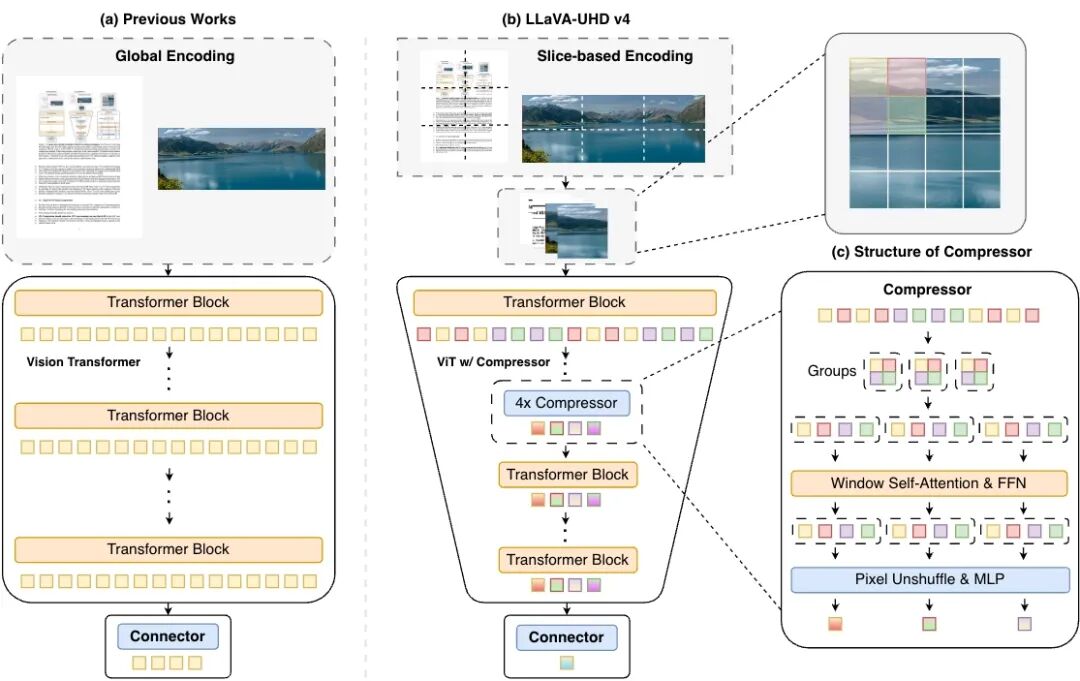
4倍/16倍混合视觉Token压缩
模型处理图像时需要将图像转化为Token交给语言模型理解。视觉token的压缩率直接影响显存占用、首响延迟、推理吞吐等关键效率指标。
MiniCPM-V 4.6实现了4倍和16倍压缩的同时兼得:需要高精度时用4倍,需要极速推理时切16倍,两种模式自由切换。
工业验证
2025年快手推出OneRec推荐大模型,用于短视频主场景的内容推荐。该系统在处理视频封面图、字幕、OCR等多模态信息时,使用了MiniCPM-V-8B模型,承接了快手短视频推荐主场景25%的请求。


快手日活用户达亿级规模,25%的主场景请求意味着极高的并发压力。MiniCPM-V系列在该量级下稳定运行,说明16倍压缩率技术在真实工业场景中不仅测试数据好看。
MiniCPM-V 4.6将这项经过大规模验证的技术进一步搬到了1B量级,云端工业场景和端侧个人设备从此可以共用同一套技术路线。
对开发者的意义
MiniCPM-V 4.6将微调门槛降到了很实际的位置:一张RTX 4090消费级显卡就能跑完整个微调流程。独立开发者、高校研究团队、小型创业公司不需要租用昂贵的算力集群,可以直接在本地验证想法。
工具链已全面打通:微调框架支持ms-swift和LLaMA-Factory,推理框架兼容vLLM、sglang、llama.cpp、Ollama,几乎覆盖目前主流的开发选择。
应用场景
MiniCPM-V系列已在联想、吉利、上汽大众、长安马自达等品牌落地,覆盖汽车、PC、手机、智能家居等多个终端场景。将参数量压到1B,意味着进入更多设备的门槛又低了一截,不只是旗舰手机,很多此前算力有限的硬件都开始具备搭载真正可用视觉AI的条件。
总结
MiniCPM-V从2024年4月发布第一版至今,每一代都在做同一件事:用更小的代价,做不输甚至更好的事。真正决定一个模型能否被广泛使用的,往往不是它有多大,而是它能跑在哪里、跑得多快、用起来有多顺。
相关链接
- HuggingFace: https://huggingface.co/openbmb/MiniCPM-V-4.6
- GitHub: https://github.com/OpenBMB/MiniCPM-V
- Modelscope: https://modelscope.cn/models/OpenBMB/MiniCPM-V-4.6
- Web Demo: https://huggingface.co/spaces/openbmb/MiniCPM-V-4.6-Demo
- App Demo: https://github.com/OpenBMB/MiniCPM-V-Apps