收藏夹、笔记软件、网盘里堆满了各种"可能以后会用到"的资料,但真正需要的时候,要么搜不到,要么找到了也是一堆零散的碎片,无法串起来形成有用的知识。花时间手动整理笔记的时间往往比阅读时间还长,最后索性放弃。
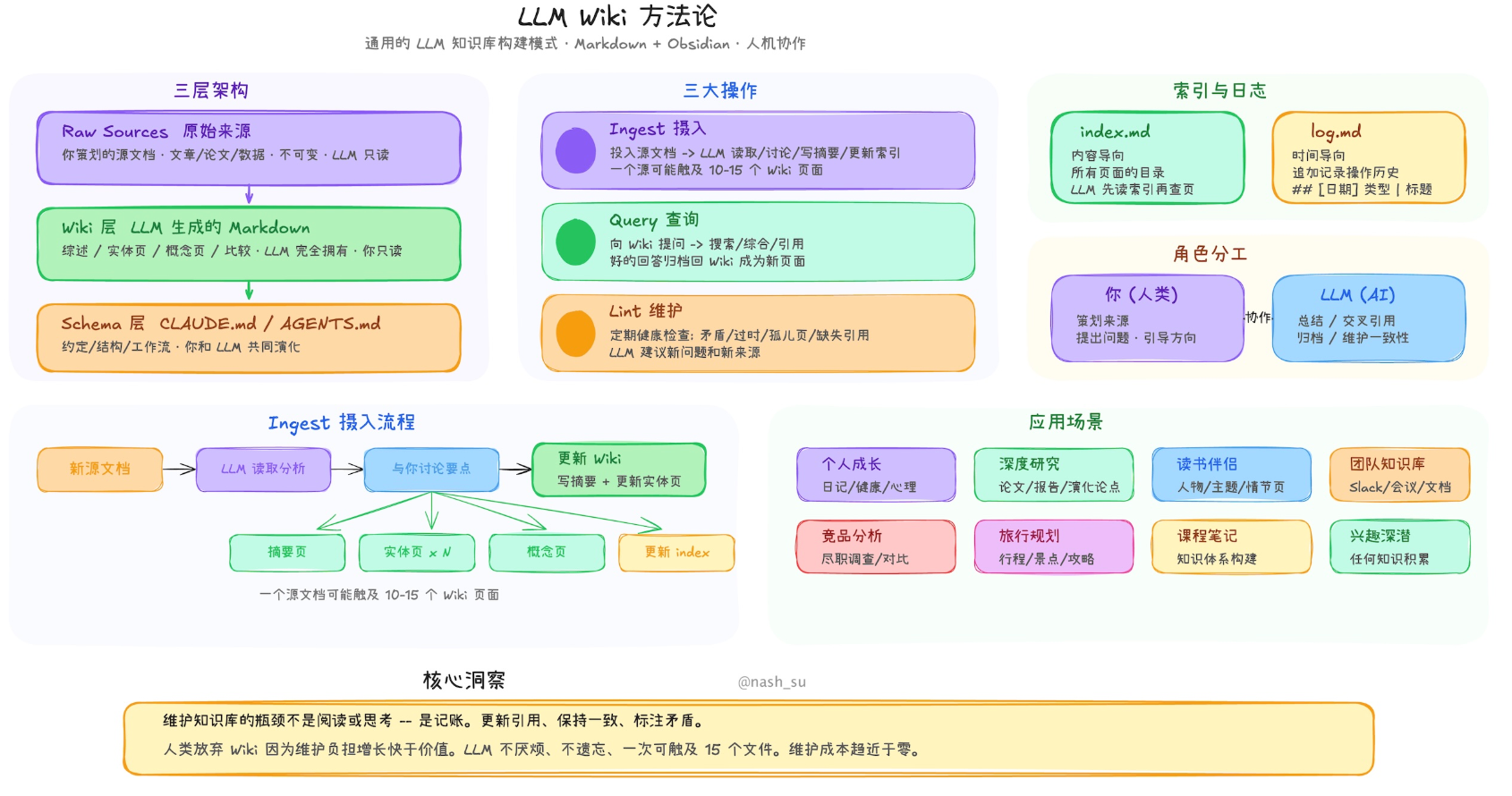
LLM Wiki 是一个跨平台桌面应用,基于 Andrej Karpathy 提出的 LLM Wiki 方法论,把传统的 RAG 思路完全颠覆。它不是另一个笔记软件,而是让大模型自动帮你构建、维护、更新的个人知识库。
核心理念:编译一次,持续更新
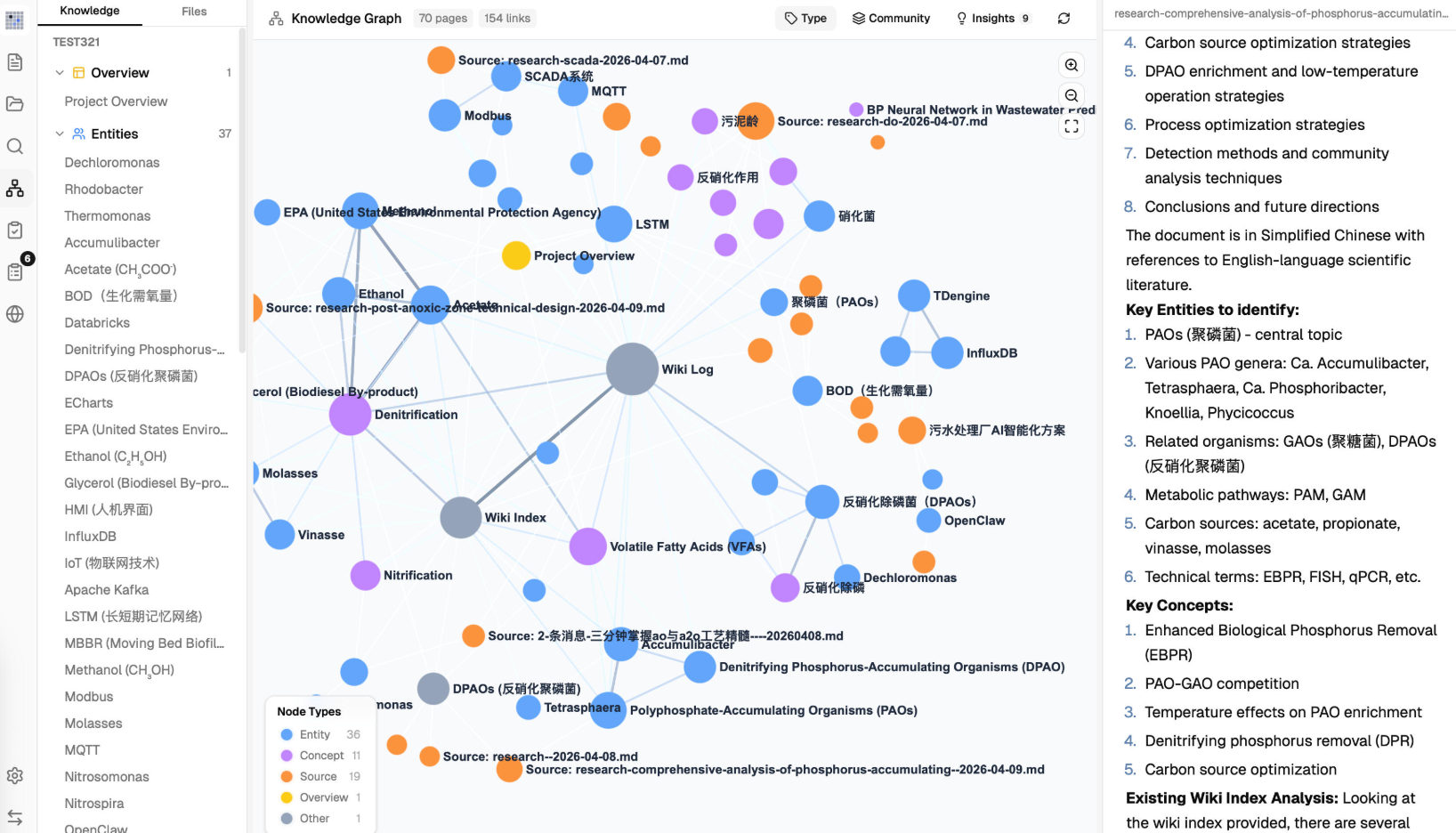
LLM Wiki 的核心理念非常简单:把你的文档"编译"成一套结构化的 Wiki,知识只整理一次,之后持续更新维护。
和传统的 RAG 不同,传统 RAG 每次提问都要去翻原始文档,检索碎片文本,用完就忘。LLM Wiki 是先让 LLM 把文档内容彻底消化,提取实体、概念、关系,生成互相关联的 Wiki 页面,之后所有的问答都基于这个已经"编译好"的 Wiki 来做。
核心亮点
两步思维链 Ingest
LLM Wiki 没有让 LLM 一边读一边写,而是把过程拆成两个步骤:
- 第一步:分析 — LLM 先读取源文档,提取关键实体、概念、论点,分析和现有 Wiki 内容的联系,标记出可能的矛盾和知识空白,给出 Wiki 结构的建议。
- 第二步:生成 — 基于第一步的分析结果,LLM 生成 Wiki 页面,包括源摘要、实体页面、概念页面,自动建立交叉引用,更新 index.md、log.md、overview.md 等核心文件。
这种两步走的方式比单步生成的质量高很多。还加了 SHA256 增量缓存——源文件内容没变就直接跳过,既省 Token 又省时间。
四信号知识图谱
LLM Wiki 不只是简单的 Wiki 页面互链,还构建了一个完整的知识图谱,用四个维度来计算页面之间的相关性权重:
- 直接链接(权重×3.0):通过 [[wikilinks]] 直接关联的页面
- 来源重叠(权重×4.0):共享同一个原始来源的页面
- Adamic-Adar(权重×1.5):通过共同邻居关联的页面
- 类型亲和(权重×1.0):同类型页面之间的加分(实体↔实体,概念↔概念)
基于这个图谱,项目用 Louvain 算法自动发现知识聚类——能告诉你"你收集的这些资料里,哪几个主题天然形成了一个知识域"。每个聚类还会有一个内聚度评分,低于 0.15 的会被标记为警告。
深度研究,自动填补知识空白
当知识图谱发现"知识空缺"时(比如某个概念只有一两篇引用),可以直接触发 Deep Research 功能。
LLM 会先读取 overview.md 和 purpose.md 来理解研究方向,然后生成优化的搜索主题和查询语句,通过 Tavily API 进行网络搜索。搜到的结果会自动回灌到 Wiki 里,LLM 会把这些新内容合成一个研究页面,建立和现有 Wiki 的交叉引用。
隐私安全
所有的 raw 资料和生成的 wiki 都保存在本地,完全隐私安全。Wiki 目录本身就是一个完整的 Obsidian vault,可以用 Obsidian 打开进行二次创作和沉浸式阅读。
苏米注:LLM Wiki 负责"生产知识",Obsidian 负责"消费知识",两者完美互补。这种设计思路值得学习——让专业工具做专业的事。
功能特性
- 完整的 Wiki 系统:严格遵循 Karpathy 的三层架构——原始素材、知识库、规则配置
- 多格式文档支持:PDF、DOCX、PPTX、XLSX/XLS/ODS、图片
- Chrome 扩展一键剪藏:自带 Chrome 扩展(Manifest V3),可以一键把网页剪藏到 Wiki 里
- 多会话聊天:支持创建多个独立的聊天会话,每个会话都可以保存、重命名、删除
- 思维过程可视化:实时显示 LLM 的思考过程
- KaTeX 数学公式支持:完整支持 LaTeX 数学公式
快速上手
安装方式
方式一:下载预编译二进制(推荐)
直接去 GitHub Releases 页面下载对应平台的安装包:
- macOS:.dmg 文件(支持 Apple Silicon 和 Intel)
- Windows:.msi 安装程序
- Linux:.deb 或 .AppImage
方式二:从源码构建
需要先安装 Node.js 20+ 和 Rust 1.70+,然后执行:
git clone https://github.com/nashsu/llm_wiki.git
cd llm_wiki
npm install
npm run tauri dev # 开发模式运行
npm run tauri build # 生产环境构建Chrome 扩展安装
- 打开 chrome://extensions
- 开启「开发者模式」
- 点击「加载已解压的扩展程序」
- 选择项目中的 extension/ 目录
编写 schema.md
schema.md 是 LLM Wiki 的核心配置文件,告诉 LLM 如何提取知识:
# Knowledge Schema
## Categories
- **Finance**: 涵盖期权交易、对冲策略、CPA 财管考点。
- **Technology**: 涵盖前端技术 (WebGPU/Vite)、Python 实现、AI 编程。
- **Concepts**: 跨学科的核心理论与术语定义。
## Extraction Rules
1. 提取文档中的核心实体。
2. 识别并建立实体间的逻辑联系,使用 [[双括号]] 建立链接。
3. 如果发现文档内容与现有 Wiki 存在冲突或补充,请在笔记中注明。
## Output Template
- **Summary**: 核心观点。
- **Context**: 应用场景。
- **Technical/Formula**: 公式或代码片段。
- **Audit**: 需要进一步深度研究的空白点。
总结
LLM Wiki 解决了传统 RAG 的几个核心痛点:
- 知识不累积:每次都重新开卷考试 → 编译一次,持续更新
- 效率低下:每次都要检索、拼接原始文档 → 基于已编译的 Wiki 问答
- 成本高:需要额外搭建向量数据库 → 本地 Markdown 文件
- 关联性差:无法建立知识之间的深层联系 → 四信号知识图谱
LLM Wiki 的思路是:人负责"看什么",LLM 负责"怎么记"——这才是正儿八经的人机分工。
GitHub:github.com/nashsu/llm_wiki