今年以来,OpenClaw、Hermes 这些 Agent 工具接连爆火,但 Token 消耗快得吓人,只是对话几次、简单设置个任务,一天就烧掉几十块。于是越来越多人把目光转向了本地模型部署,既省钱又能离线使用。
苏米注:但真动手的时候,在 Hugging Face 上面对成千上万个开源模型,根本不知道如何选择。即便选好了模型下载到本地,却发现电脑配置根本跑不起来,纯属浪费时间。
最近在 GitHub 上发现一款超实用的开源小工具:llmfit,专门为本地大模型运行提供硬件匹配方案。
核心功能
只需运行一条命令,就能帮我们找到哪些大模型适合自己的电脑本地部署。

1. 硬件自动检测
整个界面全键盘操作,用方向键上下浏览,轻量又直观。顶部自动显示检测到的 CPU、内存、显卡型号和显存。
2. 四维评分系统
中间是一张可滚动的模型表格,按综合评分从高到低排序。每一行都标注了模型的预估速度、推荐量化、内存占用与适配等级。
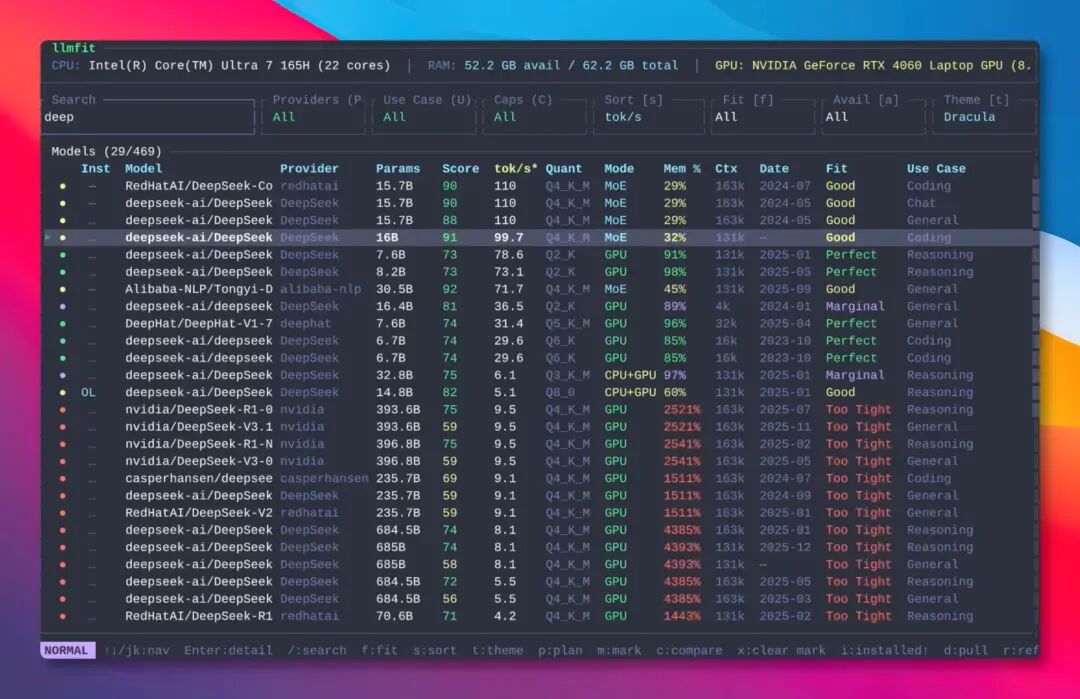
它不是简单根据电脑配置粗暴地判断"能不能装下",而是内置了一个四维打分系统:
- 质量:模型的输出质量
- 速度:生成 token 的速度
- 适配度:与当前硬件的匹配程度
- 上下文:支持的上下文长度
比如同样是 7B 模型,用在编程场景和对话场景的评分权重差异是有所不同。编程场景更看重质量与上下文,对话场景更注重响应速度。
3. 精准速度预估
作者给约 80 款主流显卡做了真实性能映射,覆盖 NVIDIA、AMD 和 Apple Silicon。所以每个模型显示的每秒生成速度,不是随手写的,而是有实打实的数据支撑。
4. 硬件模拟功能
按一下 S 键,弹出模拟配置窗口。可以在这里自由修改内存、显存和 CPU 核心数等硬件配置。点击应用之后,整张模型表格会按照模拟硬件重新计算评分。
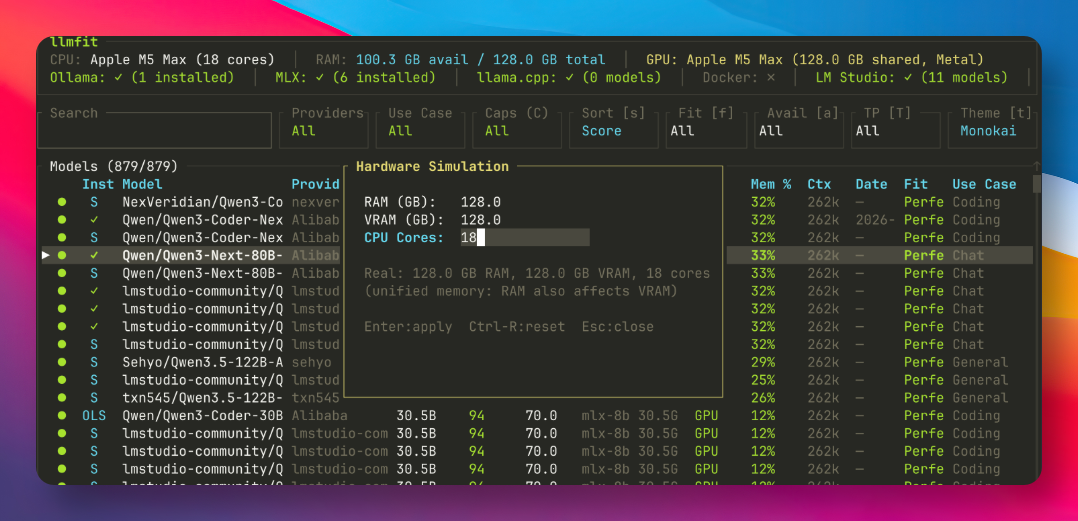
苏米注:这个功能对于准备升级电脑的朋友来说非常实用,可提前了解想部署的模型,什么样的配置电脑才能满足。
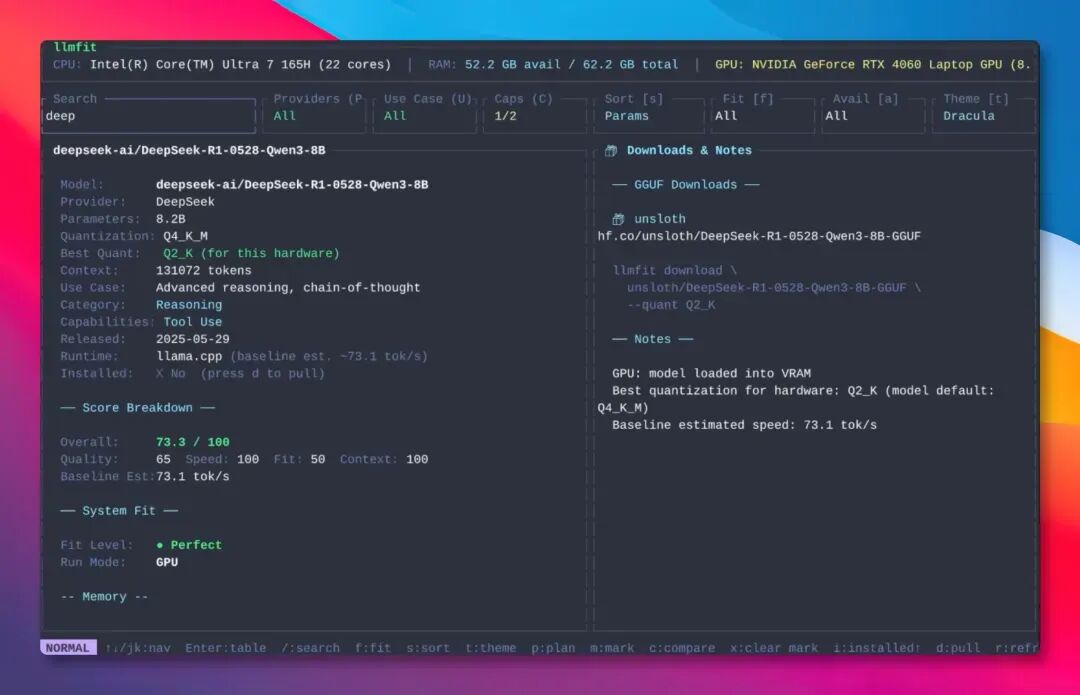
5. 一键下载模型
当我们知道能部署哪些模型后,只选中模型按 d 键,就能直接下载到对应的工具里。
目前 llmfit 已经支持对接 Ollama、llama.cpp、LM Studio 等五大主流本地模型运行工具。
安装方法
llmfit 支持 macOS、Windows 和 Linux 系统,还提供一键安装脚本。
macOS / Linux:
brew install llmfitWindows:
scoop install llmfit一键脚本:
curl -fsSL https://llmfit.axjns.dev/install.sh | shOpenClaw Skill 集成
值得一提的是,llmfit 还提供了 OpenClaw Skill 的形式。只需在项目仓库里执行一条脚本,就能把它装成 Agent 的技能。
./scripts/install-openclaw-skill.sh装好之后,我们可以直接在 OpenClaw 里提问"我电脑能跑哪些本地模型?"。Agent 会在后台调用 llmfit,解读结果,并主动帮我们配置好环境。
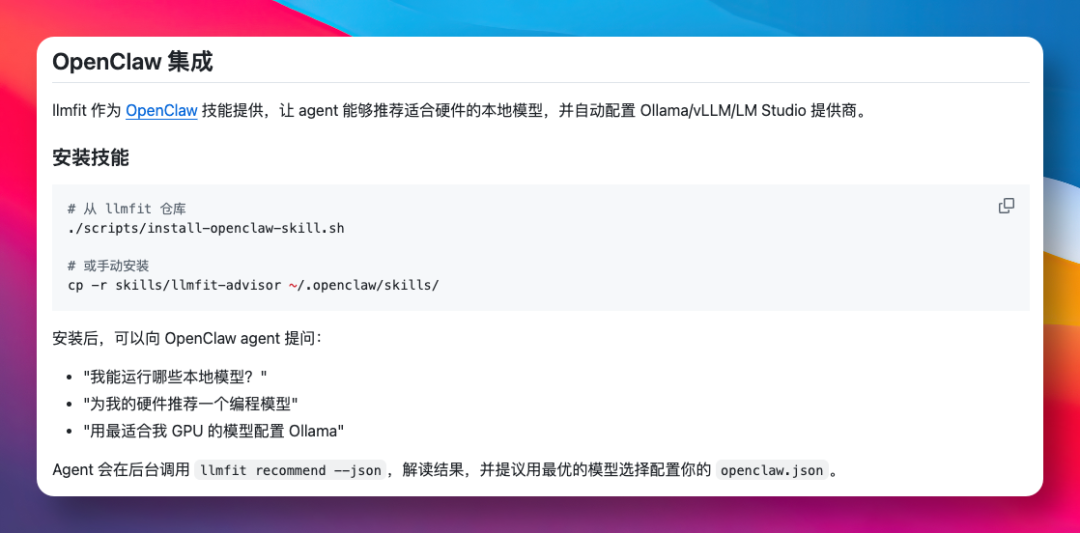
苏米注:从硬件检测到模型选型再到后端配置,整个链路都不用我们操心。
总结
随着 OpenClaw、Hermes 这些 Agent 工具的爆火,本地部署模型的需求也在持续上涨。Ollama、llama.cpp 这些工具,已经解决了怎么在本地部署模型的问题。
但对于大部分人来说,门槛从一开始就摆在那里——该选哪个模型,自己的电脑能不能跑得动。llmfit 的出现正好填上这个关键缺口,它让本地部署从少数人的专属玩法,变成了小白也能上手的日常操作。
GitHub 项目地址:https://github.com/AlexsJones/llmfit