什么是 Harness Engineering
截至 2026 年初,Claude Code 在上线六个月内年化收入突破 10 亿美元。这并不是因为"更好的提示词",而是因为 Anthropic 在"对的模型"外,构建了"对的 harness(执行支架/运行外壳)"。
苏米注:这个观点很关键——Claude Code 的成功不在于模型本身,而在于围绕模型构建的工程架构。
Harness Engineering(Harness 工程)是一门构建"围绕 AI 模型的环境"的工程学,而非去改造模型本身。模型负责"推理与决策",Harness 负责"执行、约束与连接"。
一个设计良好的 harness,只为模型提供"恰到好处的工具",并精确治理模型"允许如何使用"它们。
Harness Engineering 四条核心原则
- 模型是唯一的决策源:harness 绝不根据模型输出"分支逻辑",只执行模型明确请求的动作
- 工具是模型与外部世界的唯一接口:任何动作,从读文件到孵化子智能体,均通过"类型化、经 schema 验证"的工具调用来进行
- 上下文是被管理的资源:模型每一轮能看到的内容是"被精心筛选、压缩并按需注入"的,而不是盲目累积
- 权限是声明式,不是过程式:允许什么、阻止什么、哪些需要手动批准,应在配置中声明,而不是分散在条件分支里
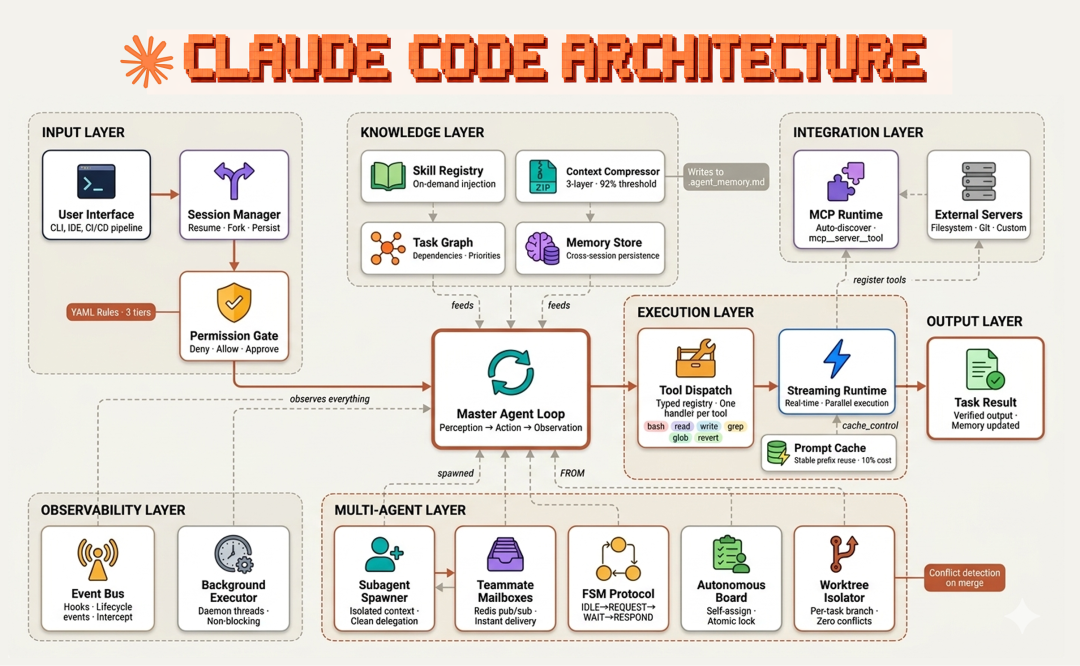
Claude Code 的五个核心部件
Claude Code 由五个核心部件协同构成:
| 部件 | 功能说明 |
|---|---|
| 单线程主循环 | 驱动模型在"感知 - 推理 - 工具执行"的周期中运行,将结果不断回灌到上下文,直到任务达到终止态 |
| 类型化工具调度注册表 | 将工具名映射到处理器(bash、read、write、grep、glob……),并以严格的输入 schema 限定模型可表达的调用与 harness 必须执行的内容 |
| 上下文管理层 | 按需注入技能(skill)、三层对话压缩、基于磁盘的持久化记忆,确保当会话超过模型上下文窗口时,依然能保持一致、连贯的推理 |
| 规则驱动的权限治理系统 | 三层评估(始终拒绝、始终允许、用户确认),并由生命周期事件总线(event bus)支撑,使外部钩子可观察并拦截每一次工具调用 |
| 多智能体协调层 | 支持子智能体的上下文隔离、异步团队协作、由 FSM(有限状态机)治理的智能体间协议、以及通过 git worktree 实现的任务级目录隔离 |
Phase 1: 核心智能体循环
最小 While 循环
任何 agentic 系统的最基本原则,是"感知 - 行动 - 观察"的闭环:
- 智能体接收任务,并尝试使用工具给出解法
- 观察结果,并由模型决定是继续还是停止——"由模型驱动,而非代码分支"
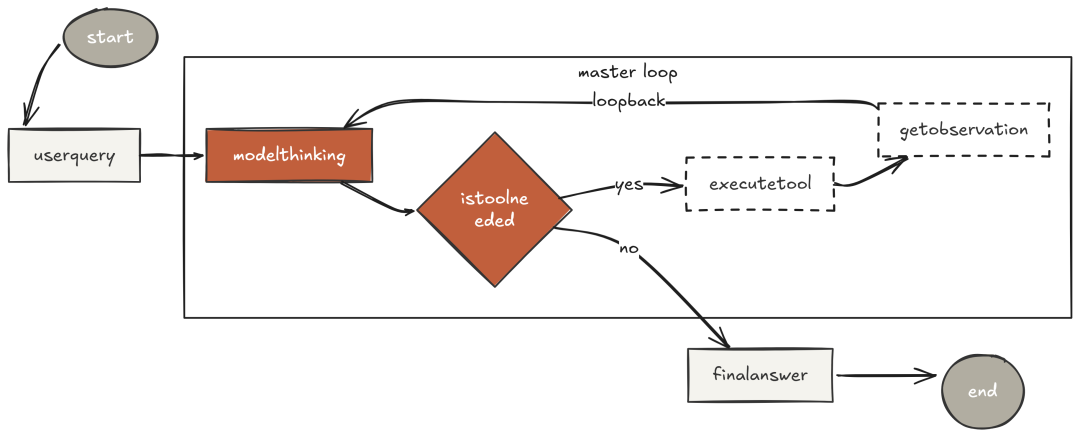
这不是"重试循环"或"回退机制",而是"核心推理引擎"。在 Claude Code 中,这是一个统一的主循环:不论你让 Claude 修一行小 bug,还是重构整个代码库,这个循环始终没变化。变的只是模型在循环内部做出的决定。
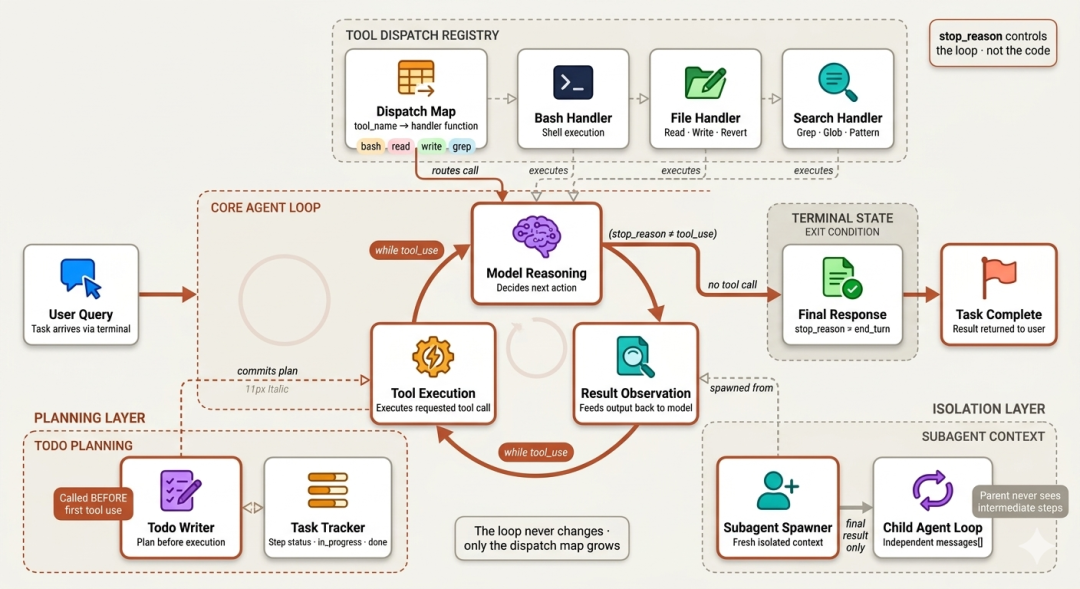
工具分发表模式(Tool Dispatch Map Pattern)
在 Claude Code 的内部架构里,工具注册表(tool registry)是被工程师反复研究的关键部件之一。
Claude Code 自带 18 个注册工具:bash、read、write、edit、glob、grep、WebFetch、AskUserQuestion、TodoWrite 等。

优雅之处不在工具的多少,而在于"新增工具无需改主循环一行代码"。这一切由"dispatch map(分发表)"这个架构模式促成。
Dispatch map 将"模型想做的事"对接到"真正执行的代码"。循环对工具一无所知——它只会做一件事:dispatch[tool_name](input)。
苏米注:这个设计模式值得学习——通过分发表将工具定义与主循环解耦,扩展性极强。
TodoWrite:先规划后执行
对 Claude Code 执行轨迹的逆向分析显示:遇到复杂任务,Claude 在写任何一行代码或读任何一个文件之前,总会先调用 TodoWrite——每一次都是如此。
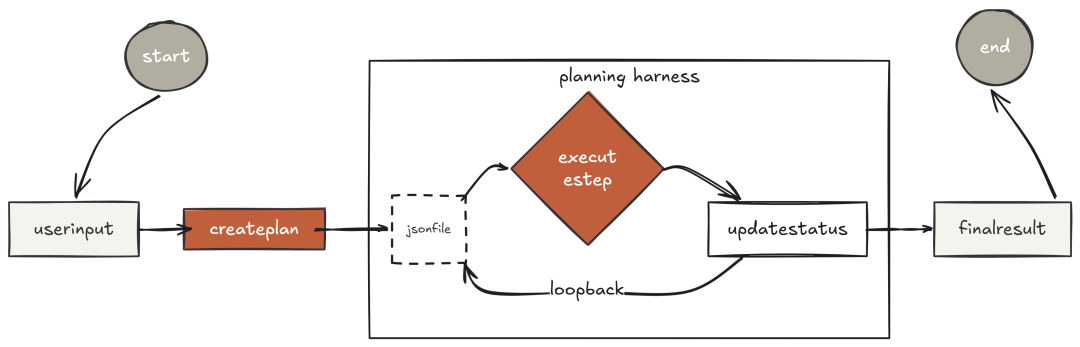
这并非偶然。Anthropic 观察到,如果没有"显式的规划机制",模型在多步骤任务中容易"漂移"。它可能边执行、边被中间结果吸引,最后跑偏到"与原任务相关、但并不相同"的方向。
TodoWrite 从"架构层面"解决了这个问题:不是让模型"变得更聪明",而是给了它一个"承诺机制(commitment mechanism)",让它在执行全程都对自己"负责"。
子智能体上下文隔离
Claude Code 的执行轨迹还显示:在探索大型代码库时,它不会在主会话里直接读一堆文件。它会并行孵化三个"explore 子智能体",各自聚焦不同角度,在"完全独立"的上下文中运行;主会话只收到"三份干净的总结"。
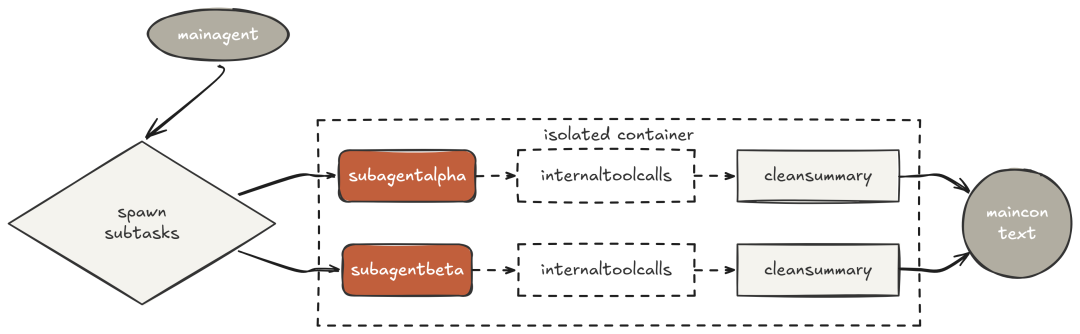
这就是子智能体上下文隔离,支撑 Claude Code 能在"任意大"的代码库上工作,而不让主对话窗口被噪声填满。所有"与最终答案无关"的中间产物,都留在子智能体上下文中,任务结束即丢弃;父会话只为"最终有用"的摘要付费。
Phase 2: 知识与上下文管理
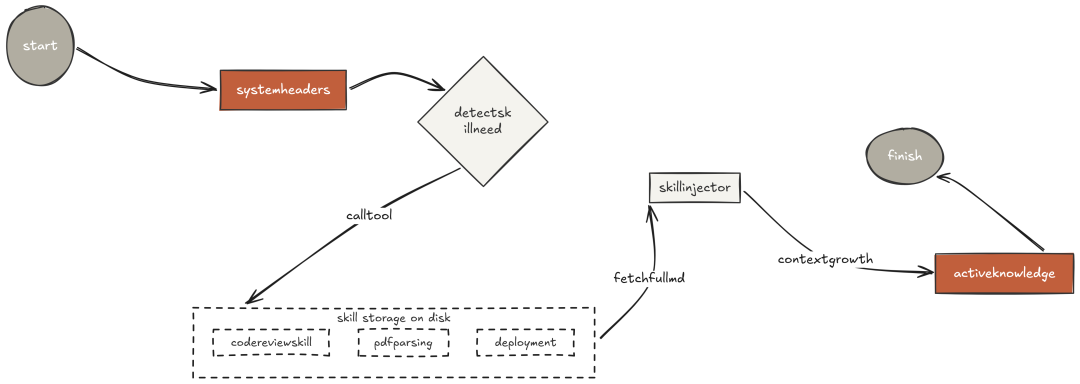
按需加载技能(On-Demand Skill Loading)
harness 工程里最耗费成本的错误之一,是"把模型可能要用的一切"都塞进 system prompt。
Claude Code 用"渐进披露(progressive disclosure)"解决了这个问题——这也是它的 skill system 如此干净优雅的原因。
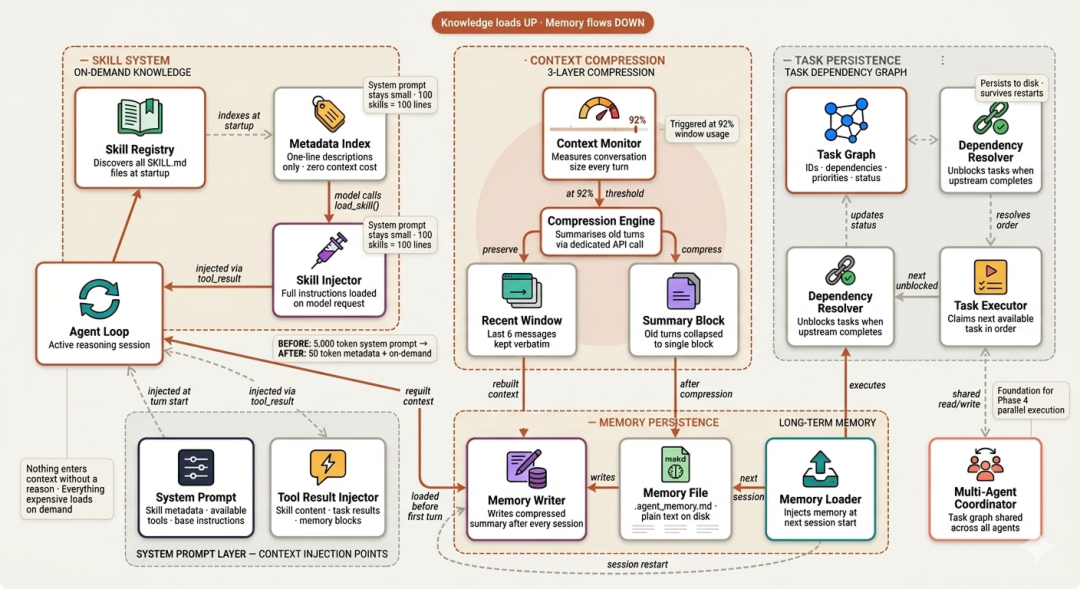
system prompt 只包含"技能的一行描述"。当模型"识别到当前任务需要该领域知识"时,它调用 load_skill(),完整指令随工具结果"即时注入到对话"中。只有"真正相关"时才为这部分上下文付费。
三层上下文压缩
所有长会话最终都会撞墙:上下文窗口被工具输出、中间结果、过时对话轮次塞满。Claude Code 的压缩器 wU2 会在上下文使用约 92% 时自动触发。
它不是"丢弃历史",而是"摘要",以显著减小 token 体积同时保留信息。摘要会被写入磁盘 .agent_memory.md,使记忆在会话重启后依然可用。
基于文件的任务依赖图
上下文压缩关心的是"模型记得什么"。任务图(task graph)关心的是"跨会话的承诺状态"。

Claude Code 的 TodoWrite 是"会话级"的:关掉终端,计划就没了。任务图扩展为"持久化、带依赖"的结构:每个任务有 ID、描述、状态、优先级、以及上游依赖(需先完成其前置任务)。
此图保存在 .agent_tasks.json 中,能跨"进程崩溃、会话重启、机器重启"而存活。
Phase 3-6: 高级特性
完整的 Harness Engineering 还包含以下高级特性:
Phase 3: 异步执行与多智能体团队
- 后台任务执行与通知
- 常驻队友与 JSONL 信箱
- FSM 团队通信协议(IDLE→REQUEST→WAIT→RESPOND)
- 自主任务自分配
- Git worktree 任务隔离
Phase 4: 生产环境加固
- 实时 token 流式输出
- 扩展工具与文件快照
- 基于 YAML 的权限治理
- 事件总线与生命周期 Hooks
- 会话持久化、恢复与分叉
Phase 5: 高性能异步运行时
- 用 asyncio.gather 并行执行工具
- 实时中断注入
- Prompt 缓存与 KV 缓存优化
- 官方 MCP Runtime 集成
Phase 6: 企业级升级
- Redis Pub/Sub 生产邮箱
- 进阶的 Worktree 生命周期管理
总结
Harness Engineering 的核心思想是:模型是唯一的决策源,harness 负责提供工具、管理上下文、执行权限治理。
苏米注:这个架构思路非常值得借鉴——不是试图让模型"更聪明",而是通过工程手段为模型创造"更容易做对"的环境。
所有代码均开源在 GitHub:
项目地址:https://github.com/FareedKhan-dev/claude-code-from-scratch