最近在浏览开源OCR项目时,被LightOnOCR-2-1B的性能数据震撼到了。
作为一名长期关注AI工具链的产品经理,我见过不少为了追求识别准确度而"堆砌参数"的方案——规模越大、效果越好,似乎成了OCR领域的"常识"。
但LightOnAI最新发布的这款端到端OCR模型,用实际成绩打破了这个认知。它用1B的参数量实现了SOTA(State-of-the-Art)效果,在多个标准测试中超越了参数量大9倍的竞争对手。更关键的是,它在速度、成本和工程化落地上做得极其务实。
项目概览
LightOnOCR-2-1B是LightOnOCR系列的旗舰模型,定位于生产环境可用的高效OCR解决方案。

核心设计理念是:输入PDF或图片,直接输出结构化Markdown文本。
这不仅仅是文字识别,而是对文档逻辑结构的完整理解和重组。
核心性能指标
1. 识别精度:越级挑战
在权威的OlmOCR-Bench测试中,LightOnOCR-2-1B拿下83.2 ± 0.9的评分。
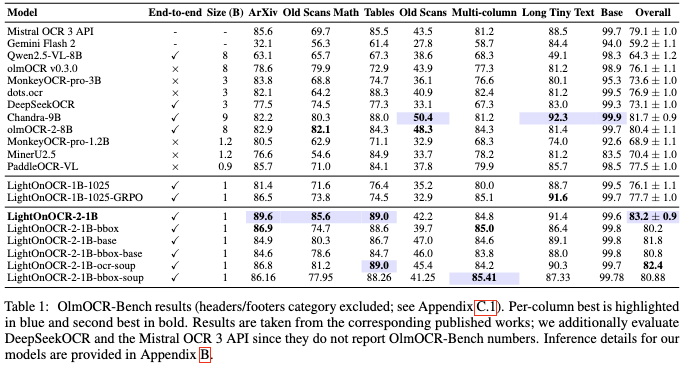
这个成绩的意义在于:
- 超越参数量9倍的模型
- 在复杂文档处理上表现突出:ArXiv学术论文(双栏排版)、数学公式识别、结构化表格还原
- 特别是对LaTeX/KaTeX公式的识别精度处于业界先进水平
2. 推理速度与成本
在单张H100 80GB显卡上(配合vLLM推理框架)的实测数据:
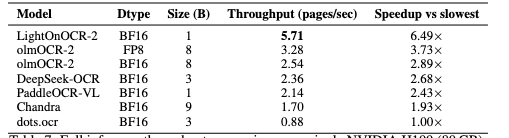
- 吞吐量:5.71页/秒
- 单位成本:处理1000页文档,电费+算力成本不足0.01美元(约7分钱)
这个成本优势对企业级应用至关重要。以月度百万级页面处理量计算,相比调用第三方API或使用大模型的方案,可节省90%以上的成本。
技术亮点:为什么1B参数能做到这些?
RLVR强化学习框架是关键。LightOnOCR团队在模型训练中引入了验证反馈循环,核心机制包括:
- KaTeX公式奖励:专门优化数学公式的渲染规范性,确保输出的LaTeX代码可直接编译
- 压缩奖励机制:惩罚模型的重复生成行为(通常是小模型的通病),将重复率降低50%以上
这种有针对性的优化方案,比盲目增加参数量更能提升模型在特定任务上的表现。
功能特性
主要能力:
- 结构化Markdown输出:不是提取文本,而是保留标题层级、列表、代码块等逻辑结构
- 表格识别与还原:自动解析表格行列关系,输出Markdown表格格式
- 数学公式识别:识别并转换为规范的LaTeX代码
- 多栏布局处理:自动识别文档的分栏结构,按正确阅读顺序输出
- 边界框检测(bbox变体):除文字识别外,还能定位文档中的图片位置,支持图文对应的精细切片
支持的输入格式:PDF、图片(PNG、JPEG等)
快速开始
1. 在线体验(零部署成本)
官方在Hugging Face提供了可交互的Demo:
https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo
直接上传PDF或图片即可快速预览效果,适合快速评估是否满足业务需求。
2. 本地部署
环境要求:
- GPU显存:16GB+(推荐24GB以上)
- 支持CUDA/MPS设备
安装依赖:
uv pip install git+https://github.com/huggingface/transformers uv pip install pillow pypdfium2
最小化使用示例:
import torch
from transformers import LightOnOcrForConditionalGeneration, LightOnOcrProcessor
# 设备选择
device = "mps" if torch.backends.mps.is_available() else "cuda" if torch.cuda.is_available() else "cpu"
dtype = torch.float32 if device == "mps" else torch.bfloat16
# 加载模型和处理器
model = LightOnOcrForConditionalGeneration.from_pretrained(
"lightonai/LightOnOCR-2-1B",
torch_dtype=dtype
).to(device)
processor = LightOnOcrProcessor.from_pretrained("lightonai/LightOnOCR-2-1B")
# 构建输入(支持URL图片或本地路径)
url = "https://huggingface.co/datasets/hf-internal-testing/fixtures_ocr/resolve/main/SROIE-receipt.jpeg"
conversation = [{
"role": "user",
"content": [{"type": "image", "url": url}]
}]
# 处理输入
inputs = processor.apply_chat_template(
conversation,
add_generation_prompt=True,
tokenize=True,
return_dict=True,
return_tensors="pt"
)
inputs = {k: v.to(device=device, dtype=dtype) if v.is_floating_point() else v.to(device)
for k, v in inputs.items()}
# 推理
output_ids = model.generate(**inputs, max_new_tokens=1024)
generated_ids = output_ids[0, inputs["input_ids"].shape[1]:]
output_text = processor.decode(generated_ids, skip_special_tokens=True)
print(output_text)
3. 生产级部署(vLLM)
对于需要高吞吐量的场景,推荐使用vLLM推理框架。这样能充分利用H100等高端显卡的并行能力,达到5页/秒的吞吐量。
启动服务:
vllm serve lightonai/LightOnOCR-2-1B \
--limit-mm-per-prompt '{"image": 1}' \
--mm-processor-cache-gb 0 \
--no-enable-prefix-caching
调用示例(处理arXiv论文):
import base64
import requests
import pypdfium2 as pdfium
import io
ENDPOINT = "http://localhost:8000/v1/chat/completions"
MODEL = "lightonai/LightOnOCR-2-1B"
# 下载PDF
pdf_url = "https://arxiv.org/pdf/2412.13663"
pdf_data = requests.get(pdf_url).content
# 转换为图片
pdf = pdfium.PdfDocument(pdf_data)
page = pdf[0]
pil_image = page.render(scale=2.77).to_pil()
# Base64编码
buffer = io.BytesIO()
pil_image.save(buffer, format="PNG")
image_base64 = base64.b64encode(buffer.getvalue()).decode('utf-8')
# 发送请求
payload = {
"model": MODEL,
"messages": [{
"role": "user",
"content": [{
"type": "image_url",
"image_url": {"url": f"data:image/png;base64,{image_base64}"}
}]
}],
"max_tokens": 4096,
"temperature": 0.2,
"top_p": 0.9
}
response = requests.post(ENDPOINT, json=payload)
text = response.json()['choices'][0]['message']['content']
print(text)
使用建议:
- 将PDF页面渲染为PNG/JPEG,最长边保持在1540像素左右
- 保持图片宽高比以保留文本几何特征
- 单个HTTP请求处理单页(vLLM可在服务端自动批处理)
相似项目对比
OCR领域还有其他值得关注的开源项目:
| 项目 | 参数量 | 核心特性 | 适用场景 |
| LightOnOCR-2-1B | 1B | 公式识别、Markdown输出、高效推理 | 学术论文、文档数字化、成本敏感场景 |
| PaddleOCR | 小于100MB | 超轻量级、多语言支持 | 移动端、边缘设备、快速部署 |
| Surya | 7B+ | 多语言、布局理解 | 复杂多语言文档 |
| LayoutLM系列 | 110M-340M | 文档理解、表单识别 | 企业表单处理、结构化提取 |
选型建议:
- 如果需要公式识别+高效推理,优先LightOnOCR-2-1B
- 如果需要极致轻量级(边缘设备),选PaddleOCR
- 如果需要多语言理解,考虑Surya或LayoutLM
应用场景
- 学术知识库构建:批量处理arXiv论文,自动提取正文、公式、表格,支撑论文检索系统
- 企业文档数字化:处理历史扫描档案、合同、财务报表,成本远低于人工转录
- RAG数据预处理:作为知识库入库前的结构化清洗阶段,提高后续检索质量
- AI辅助工具:与LLM结合,构建科研论文助手、财务报表分析工具
- 数字出版:将扫描版古籍、绝版书籍转换为可搜索的电子版本
总体评价
从产品角度看,LightOnOCR-2-1B做了正确的取舍:
- 工程化优先:不追求学术paper上的极限精度,而是围绕实际部署成本做优化
- 针对性设计:不是通用的多模态大模型,而是为OCR特定任务设计的专用模型,因此能在小参数量下达到竞争力
- 开源友好:提供在线Demo、完整代码示例、vLLM集成方案,降低了技术使用门槛
这个项目的意义在于:它证明了在特定垂直领域,通过高质量的数据、科学的强化学习方法论,小模型完全可以战胜大模型。对于成本受限的团队,或需要私有化部署的企业,LightOnOCR-2-1B是一个值得认真评估的方案。
相关资源:
模型地址:https://huggingface.co/lightonai/LightOnOCR-2-1B
GitHub:https://github.com/lightonai/LightOnOCR
在线Demo:https://huggingface.co/spaces/lightonai/LightOnOCR-2-1B-Demo