最近在整理AI自动化工具时,发现了一个有意思的现象:当Meta以20亿美金收购Manus后,GitHub上一个名叫Browser Use的开源项目随之走红,Star数一路飙升至75000+。
作为一名产品经理,我对这类项目总是特别关注——不仅因为它技术方案新颖,更因为它代表了一条不同的发展路线。
与其被商业化的Manus相比,Browser Use提供了一个可自主控制、成本相对可控的替代方案。
今天想和大家聊聊这个项目值得关注的地方。
项目定位与核心能力
Browser Use是一个基于视觉大模型的浏览器自动化框架。
其核心逻辑很清晰:不再依赖网页DOM结构进行脚本化操作,而是让AI像真人用户一样"看懂"页面,进而执行点击、滚动、输入等交互动作。
技术实现上,它结合了两类能力:
- 视觉感知层:通过Playwright进行页面截图,配合Vision Model进行视觉理解
- 决策执行层:由大语言模型根据视觉信息做出操作决策,然后通过浏览器API执行
这套方案相比传统Selenium脚本的优势在于:当网站进行改版或动态加载内容时,脚本无需调整——AI会自适应新的页面结构。
核心应用场景分析
项目官方演示了几个具体场景,我认为这些案例能代表其实际应用的适配范围:
场景一:表单填写自动化
典型例子是招聘网站的简历投递。传统方法需要在不同平台手动填写重复信息。Browser Use可以接收指令"用我的简历信息填好这份申请表",自动识别输入框位置、下拉菜单、勾选框,逐一完成填写。这类场景的共同特征是结构化数据+重复性强。
场景二:电商购物清单处理
用户可以提供一份商品清单,系统自动搜索、识别商品、加入购物车。这里的难点不在操作本身,而在于视觉识别——需要从众多相似商品中准确选出用户想要的那个。Browser Use通过Vision Model的理解能力来处理这个问题。值得一提的是,它能处理非预期事件(如弹窗广告),会自动寻找关闭按钮继续任务,这是传统脚本无法做到的。
场景三:参数对比与筛选
如"帮我找到5000元以内、性能均衡的台式电脑配置"这类任务,需要系统跨多个商品页面进行参数对比和决策。这超出了单纯的点击范围,需要真正的推理能力。
使用门槛与部署方式
从代码复杂度看,Browser Use的启动代码相当简洁:
from browser_use import Agent
from langchain_openai import ChatOpenAI
agent = Agent(
task="帮我查一下明天去上海的高铁票",
llm=ChatOpenAI(model="gemini-3-pro")
)
await agent.run()
这说明在API集成层面,项目做了很好的抽象——用户不需要理解Playwright、Vision Model的细节,只需定义任务和选择LLM即可。
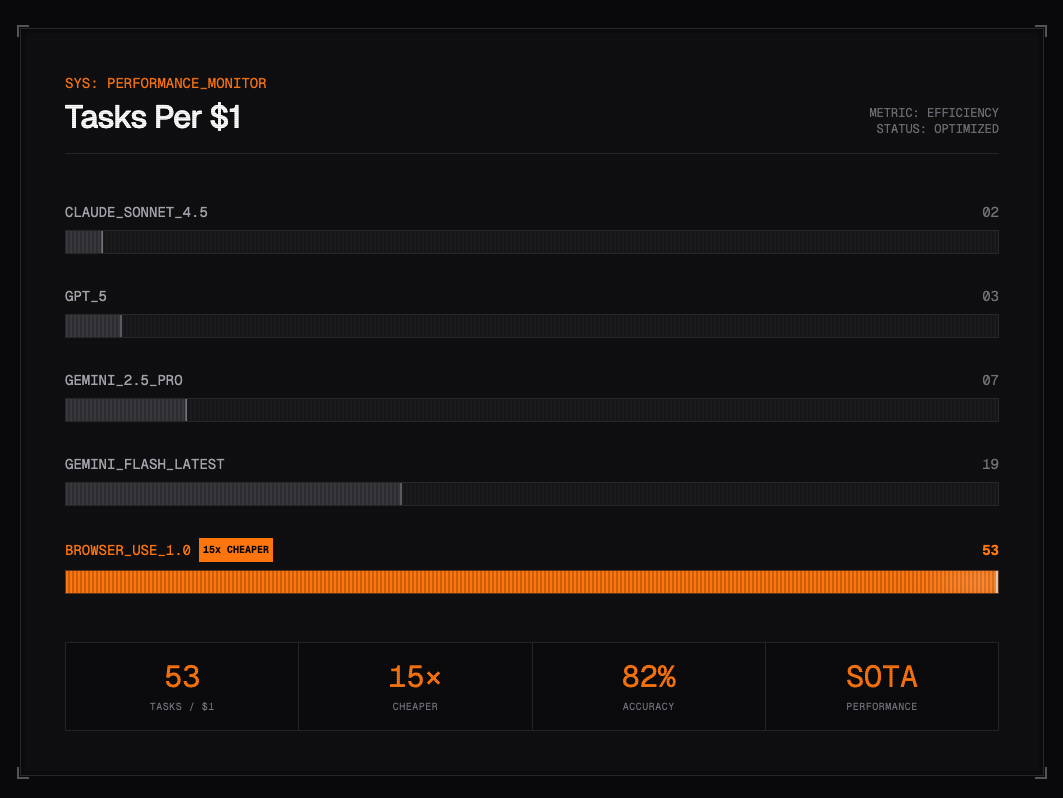
但需要注意的是,使用门槛的另一面体现在成本上。
成本与优化策略
Browser Use的工作流程是:页面截图→发送给Vision Model分析→生成操作→执行→重复。这种工作方式会产生较高的Token消耗。若全程使用高端模型(如GPT-4.5、Claude 4.5),成本确实不菲。
但项目本身开源的特点为成本优化提供了空间:
- 可用成本较低的OCR模型替代Vision Model处理文字识别和坐标定位
- 可本地部署DeepSeek-OCR等开源模型作为"眼睛"层
- 仅在需要复杂推理的决策点调用昂贵的大模型
这种分层策略能显著降低总体成本,使项目更具实用性。
与相似项目的对比
在浏览器自动化领域,还有其他值得关注的项目:
| 项目 | 技术方案 | 适配网站类型 | 使用难度 | 成本特征 |
| Browser Use | Vision Model + LLM | 动态结构网站 | 低(API简洁) | Token密集 |
| Selenium | DOM选择器 | 静态结构网站 | 中(需懂网页结构) | 低 |
| Playwright | 浏览器协议 | 动态网站 | 中 | 低 |
| Manus(商业化) | Vision Model + LLM | 通用 | 低 | 商业定价(高) |
Browser Use的差异化在于:它降低了AI自动化的使用门槛,同时保持了代码的可控性。相比Manus的商业黑盒,这对需要定制化集成的团队更友好。
实际应用的考虑因素
在决定是否使用Browser Use前,建议考虑以下几点:
- 任务类型:结构化、重复性强的操作适配度最高;复杂的多步推理可能需要更多迭代
- 成本预算:需要预估Vision Model和LLM的Token消耗,必要时应计划优化方案
- 稳定性要求:当前项目仍在活跃开发阶段,生产环境使用需评估容错能力
- 数据隐私:若涉及敏感信息,需考虑是否将页面内容发送至第三方API
总结
Browser Use代表了浏览器自动化的一个新方向——用AI的视觉和推理能力替代传统的脚本化方法。对于做爬虫、数据采集、业务流程自动化的团队来说,它打开了一扇新的门:无需再为网站改版而频繁维护脚本,只需更新任务描述。
当然,它不是银弹。高Token消耗、模型精度依赖、适配网站的多样性等问题都需要在实际应用中权衡。但75000个Star的背后,说明了开发者社区对这个方向的认可。
如果你受够了用Selenium追着不断变化的网站结构跑,或者想体验一下拥有"私人数字助手"的感觉,不妨在测试环境里试试。代码掌握在自己手里,这本身就给了我们足够的定制和优化空间。