最近体验了不少 AI 产品,但大多数要么是纯文本对话,要么就是语音助手读一段机械的合成语音。
直到在 GitHub 上发现了 Fay 这个项目,我才意识到多模态交互的数字人助理原来可以做得这么完整——它不仅能听、能说、能看,还能根据对话内容做出相应的面部表情和情感反应。
作为一个持续关注 AI 交互产品的从业者,我觉得有必要把这个项目梳理一遍,和大家分享它的设计思路和实际体验。
项目概览
Fay 是一个开源的数字人交互框架,核心定位是将语音识别、自然语言处理、语音合成和表情驱动整合为一个完整系统。
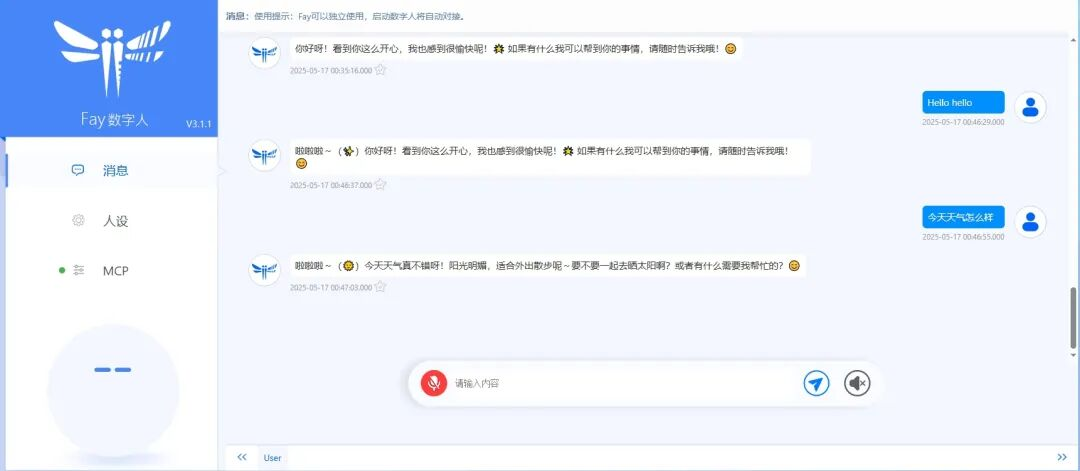
与市面上大多数 AI 聊天机器人只做文本或语音单一模态不同,Fay 的差异化在于——它提供了一个具备视觉反馈的数字人形象,能够通过面部表情、口型同步等动画效果,让 AI 回复更具生动感和拟人化特征。
开源成就:
- GitHub Star 数:12.0K+(持续增长中)
- 技术栈:Python + WebSocket 架构,支持多种 AI 模型接入
- 维护状态:持续更新,社区反馈积极
核心功能模块拆解
1. 多模态交互能力
- 语音唤醒:无需手动启动,支持自定义唤醒词
- 语音识别(ASR):将用户语音转换为文本指令
- 自然对话:接入大语言模型处理用户意图,告别固定脚本式回复
- 语音合成(TTS):生成自然流畅的语音输出,支持多种音色选择
2. 数字人形象驱动
内置表情动画系统,支持:
- 面部表情同步:AI 生成回复时,数字人能做出相应的喜悦、思考、安慰等表情
- 口型同步:语音播放时嘴型自动匹配,增强视觉真实感
- 肢体动画:支持头部转动、手势等基础肢体反应
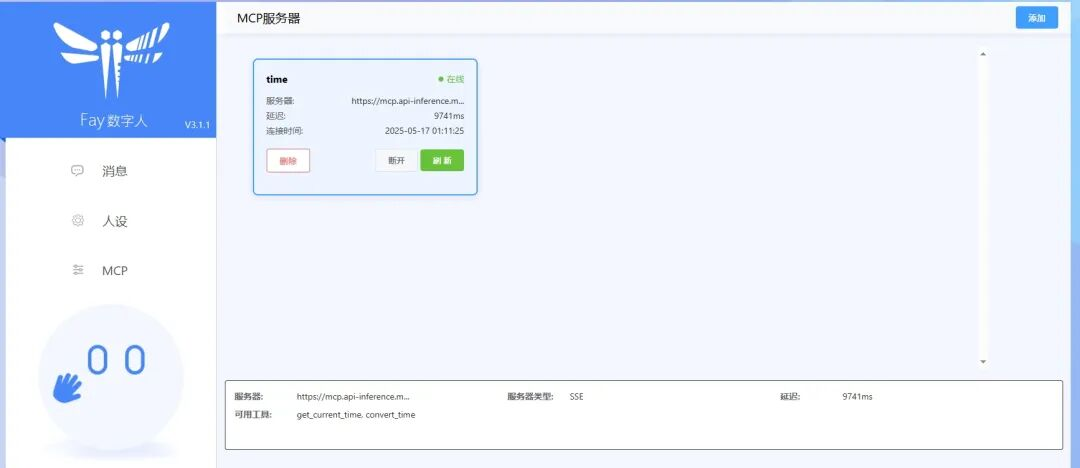
3. 灵活的 AI 大脑接入
不依赖单一模型,支持插拔式接入:
- 通用大模型:GPT、文心一言、讯飞星火等
- 本地知识库:可对接企业或个人的私有知识库,打造行业专属智能助手
- 模型切换:通过配置文件即可在不同 AI 模型间切换,无需修改核心代码
4. 情感计算模块
不仅做信息处理,还关注用户状态:
- 情绪识别:分析用户语音和表述中的情感倾向(积极/消极/中立)
- 情感回应:AI 会调整回复语气和表情,比如在用户沮丧时给予安慰,在开心时陪伴分享
5. 远程音箱模式
- 支持 iOS 和 Android 配套应用
- 将闲置的旧手机改造为智能音箱
- 服务端可部署在家庭服务器或云端,通过 App 远程唤醒和交互
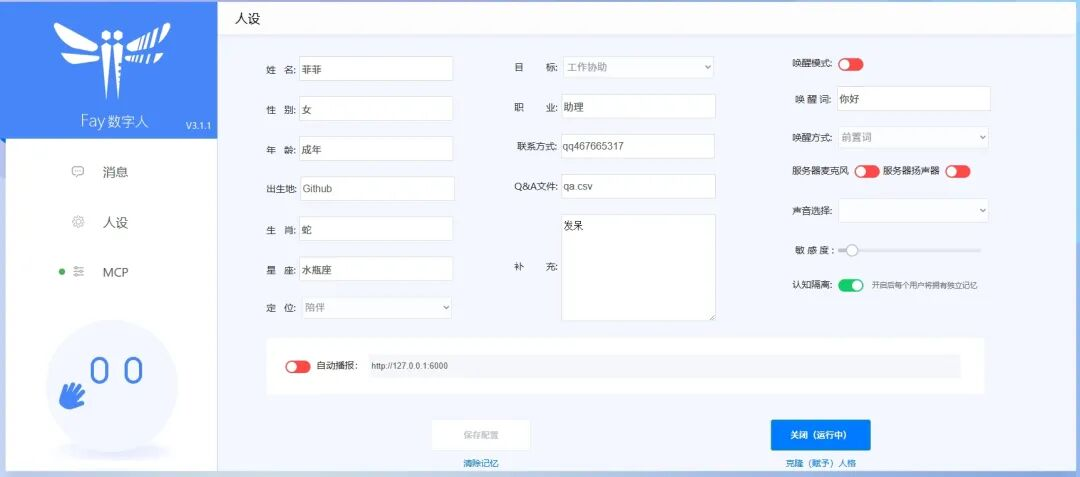
6. 可视化管理控制台
- Web 界面实时查看对话记录和交互日志
- 参数调优:语音识别灵敏度、回复速度、表情强度等均可可视化调整
- 模型切换和 API 配置管理,小白用户也能上手

技术架构特点
Fay 采用模块化解耦设计,各功能模块相对独立:
class DigitalHuman:
def __init__(self):
self.asr = ASR() # 语音识别模块
self.nlp = NLP() # 自然语言处理
self.tts = TTS() # 语音合成
self.avatar = Avatar() # 数字人驱动
def interact(self, audio_input):
text = self.asr.recognize(audio_input)
response = self.nlp.process(text)
emotion = self.nlp.analyze_emotion(response)
self.avatar.express(emotion)
return self.tts.synthesize(response)这种设计的优势在于:
- 可独立替换语音识别引擎(如从讯飞换为百度)
- 可自定义数字人形象素材
- 支持自训练专属 AI 模型的接入
- 易于扩展新的交互能力(如视觉识别、手势控制等)
安装与部署
基础安装流程:
git clone https://github.com/xszyou/Fay.git
cd Fay
pip install -r requirements.txt
python main.py部署选项:
| 部署方式 | 适用场景 | 门槛 |
| 本地直接运行 | 开发测试、单机使用 | 低 |
| Docker 容器部署 | 服务器部署、多环境管理 | 中 |
| 移动端 App 连接 | 远程家庭场景、多设备同步 | 中 |
硬件需求:
- 最低配置:普通 PC 或树莓派即可运行基础功能
- 推荐配置:8GB+ 内存、独立显卡(用于加速语音合成和表情渲染)
- 网络:若接入云端 AI 模型 API,需稳定网络连接
实际体验与应用场景
我体验 Fay 已有一段时间,以下是几个典型使用场景:
家庭助手场景:早晨问天气,数字人用温柔的声音提醒你带伞;工作累了和它聊天,数字人的表情会随对话动态变化,相比冷冰冰的文字框要有温度得多。
陪伴与教育场景:可为老人和孩子打造具备情感反应的智能陪伴助手,相较传统音箱设备更具人文关怀。
企业应用场景:接入特定行业知识库后,可用作客服虚拟形象、产品展厅讲解员等,提升用户交互体验。
初期配置复杂度:申请语音合成、识别、AI 模型等各类 API 密钥需要一定的前置工作,但配置完成后的成就感是值得的——你拥有了一个真正的 AI 助理。
与同类项目的对比参考
市面上也有其他类似的项目,简要对比一下:
| 项目 | 多模态 | 表情驱动 | 模型灵活性 | 部署复杂度 |
| Fay | ✓ 完整 | ✓ 强 | ✓ 高 | 中 |
| 开源语音助手 | ✓ 部分 | ✗ | ✓ 中等 | 低 |
| 3D 数字人平台 | ✓ 完整 | ✓ 强 | ✗ 固定 | 高 |
Fay 的定位较为均衡——既有完整的多模态交互能力,又保持了开源项目的可定制性和相对简洁的部署流程。
项目发展方向
从最新更新来看,项目团队在持续优化:
- 丰富数字人形象库,支持更多风格的虚拟角色
- 提升语音合成的自然度和情感表达
- 社区贡献了不少定制方案,如特定行业的知识库集成、独特的数字人皮肤等
总结与建议
作为一个长期体验 AI 产品的产品经理,我认为 Fay 在开源数字人交互领域填补了一个实用的空白——它不追求绝对的逼真度或高端特效,而是提供了一个功能完整、可扩展、门槛适中的多模态交互框架。
适合尝试 Fay 的人群:
- 想体验真正多模态 AI 交互的用户
- 有定制化需求的企业(客服、讲解员等应用)
- AI 爱好者和开发者(有很强的学习和二次开发价值)
- 想为家里老人孩子打造智能陪伴的家庭用户
需要注意的点:
- 前期配置 API 密钥需要一定技术门槛和成本投入
- 依赖云端 API 时,网络稳定性和隐私保护需要自行评估
- 表情驱动效果在低配设备上可能有卡顿,建议配备独立显卡
如果你对 AI 交互的未来方向感兴趣,或者正在思考如何让 AI 更有"温度",Fay 是一个值得深入体验和学习的开源项目。