有人说学 LangChain,有人说背 Transformer 原理,还有人说先去考模型工程师证。
听起来都很“酷”,但现实里常常出现同一套悲剧:技术很强,产品上不了线;Prompt 很美,没人愿意用。
作为做产品的人,我观察并参与过 50+ 支 AI 团队的落地实践后越来越肯定一件事:AI 项目的成败,关键不是谁会更多术语,而是谁掌握了系统性的能力框架。把关注点从“学一个新库 / 调一个Prompt”扩到“把模糊问题变成可交付的产品”,你就赢了一半。
下面是我提炼出的三大维度,同时把我在落地里遇到的坑、可操作的检查清单和实战建议都补齐了。
三大维度
维度一:问题定义力 — 把“模糊需求”变成“可解任务”
AI 不是万能药,最大的坑是用 AI 去做本就不该自动化的事。很多团队一开始的需求像雾一样:想让 Agent 更智能、提升体验、做个通用助手——都没法做出具体产品。
实战要点(Checklist):
把需求按 SMART(具体、可测量、可达成、相关、有时限)重写。
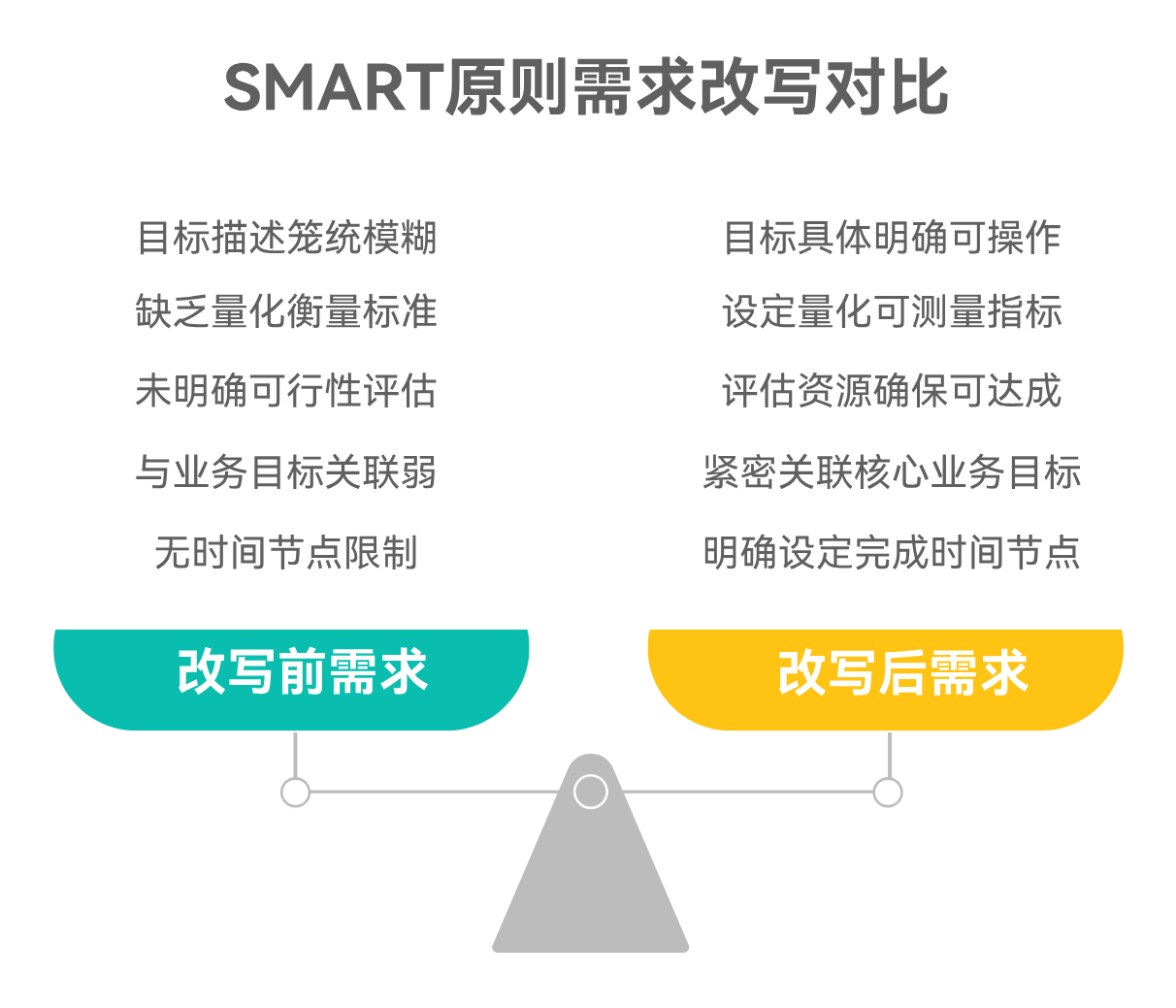
例如:
-
❌ “让 Agent 能自主决策”
-
✅ “在无用户输入时,Agent 根据上下文判断是否调用工具,调用决策准确率 ≥ 80%(测试集)且平均决策延迟 < 300ms。”
任务原子化:Single Agent → Single Task。一个 Agent 一次只解决一个明确子目标,复杂流程拆成多个 Agent/模块。
明确 输入 / 输出 / 成功标准 / 失败回退:谁来负责输入清洗?输出用什么格式(Markdown / JSON)?成功如何量化?
先判断“能否用现有能力实现”:如果现有 LLM + tooling 完不成,先退回到人工半自动方案做 POC。
实战示例(简短):
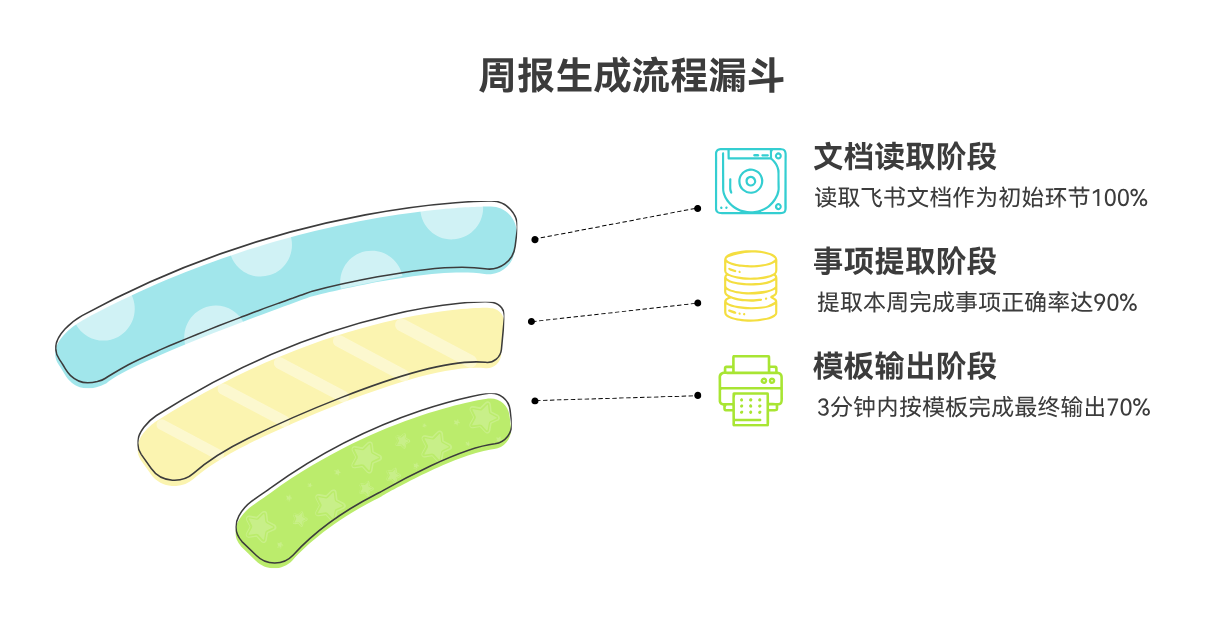
“让它帮我写周报” → 具体化为:读取飞书文档、提取本周完成事项、按 Markdown 模板输出;要在 3 分钟内完成,正确率(条目识别)≥ 90%。
一句话总结:不会定义问题的 PM,不配谈 AI 解决方案。
维度二:流程架构力 — 设计“人+机+系统”的协同流水线
AI 产品经理不是纯程序员,但必须像架构师一样思考流程:你不是在拼一个功能,而是在搭一条“人机协同的自动化流水线”。
你要能画出清晰的流程图/状态机,并回答这些问题:哪些环节由 AI 自动化?哪些需要人工审核?失败如何回滚或补救?怎样监控每一步的耗时、成本与失败率?
实践清单:
画出端到端流程(包含工具调用、状态判断、重试路径),标注成本与 SLAs。
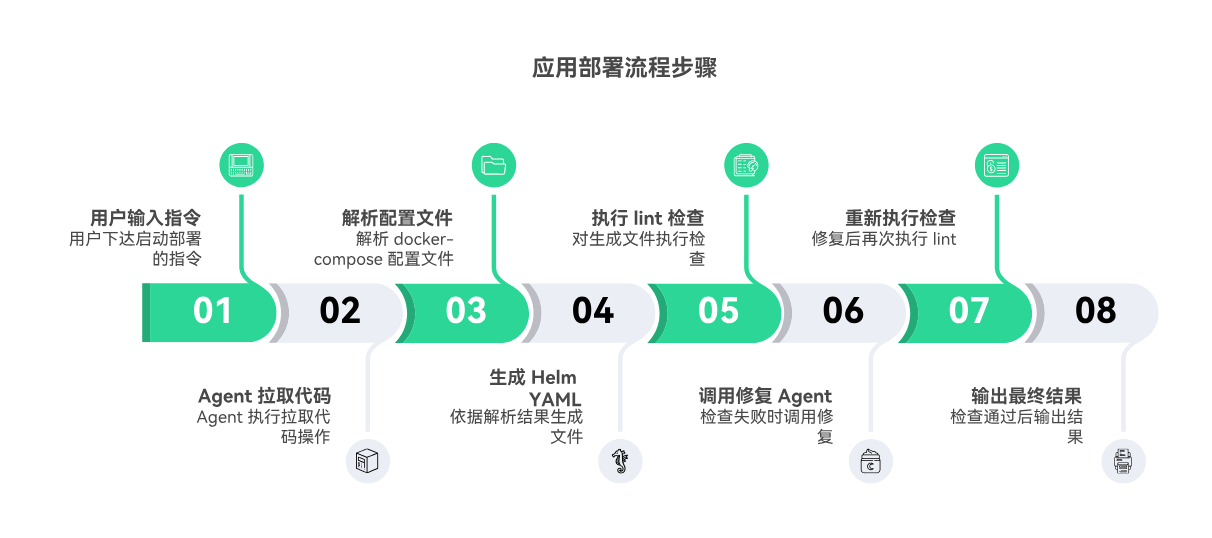
示例步骤:用户输入 → Agent 拉代码 → 解析 docker-compose → 生成 Helm YAML → lint → 若失败调用修复 Agent → 重新 lint → 输出。
定位人机边界:把高风险、法律/合规/高成本的输出保留人工审核,低风险重复性工作优先自动化。
引入状态机思维:为每一步定义状态、超时、重试策略和补偿动作(compensation)。
监控与可观测性:请求数、平均 Token 消耗、延迟、错误率、人工介入率、每次工具调用成本。
熟悉常见编排与交互模式(如 ReAct、Plan-and-Execute)以及主流编排工具(Dify / LangGraph / CrewAI 等)——不必精通源码,但要知道它们能解决哪类问题。
实战提醒:
别把 Agent 当黑盒:把每个工具调用都当成一个可替换的“微服务”,便于迭代和降级(fallback)。
失败不是终点:设计自动恢复(回滚、降级通知、人工接管)比一次性把所有异常都“靠模型做对”更可靠。
一句话总结:你搭建的不是单个 Agent,而是可持续运营的自动化流水线。
维度三:验证迭代力 — 用数据让 AI 持续进化
AI 的输出是概率性的:一次好不等于稳定好。优秀的 AI PM 要建立科学的验证闭环,把模型/Prompt/流程的每次改动都变成可衡量的实验。
三板斧(PoC → 指标化 → 扩大验证):
人工评估(Human Eval)
-
设计 10–20 个代表性用例,团队评分(1–5):准确性 / 可读性 / 安全性。
-
把 Bad Case 分类(歧义、事实错、格式错、越权),优先修复高频类别。
自动化测试(Auto Eval)
-
写脚本批量跑用例,统计成功率、平均 Token 消耗、响应延迟、成本。
-
保持 baseline(例如 v1 成功率 72%,v2 目标 > 80%),A/B 对比要只改动一个变量。
小范围 POC(真实用户验证)
-
给 3–5 个核心用户/团队试用,收集定性反馈并问“你愿意为这个功能付费吗?”
-
观察真实使用频率、流失/中断点、人工介入比例。
迭代原则(要硬核):
-
先跑通再优化:先把最简单可用版本放到真实场景里,再做体验与成本优化。
-
数据说话,不凭感觉:所有重大改动都有显式指标(成功率、NPS、人工成本下降等)。
-
每次只改一个变量:Prompt / 工具 / 流程 三者分离,便于定位效果来源。
实战教训(我见过的):
团队把时间全花在抛光 Prompt,却没有 baseline 与自动化测试,上线后很快暴露出稳定性问题,最后不得不回滚到人工流程。教训是:质量来自验证,不是微调。
一句话总结:AI 产品没有“上线即结束”,只有持续验证与进化。
结语
如果你也想成为优秀的 AI PM,把精力从“学更多模型细节 / 抄更漂亮的 Prompt”转移到 问题定义 → 流程设计 → 验证迭代 这三条能力线上,会比单纯刷技术更快看到产品成效。
小建议(实操):
-
下次听到“让它更聪明”的需求,先把它改写成“输入 / 输出 / 成功指标 / 时间约束”。
-
做流程图时,把人工触点和成本并列展示,决策更清晰。
-
每次改动做 A/B,并记录 baseline,哪怕是 Prompt 的一句话改动也别例外。
最后一句话:Prompt 很重要,但 不会定义问题、不会搭流程、不会验证