2026 年 4 月 28 日凌晨,小米 MiMo 团队正式发布新一代旗舰模型 MiMo-V2.5-Pro 和 MiMo-V2.5,两个模型全部开源,采用 MIT 协议,可商用、可继续训练、可微调,无需额外授权。
同时发布的还有 Xiaomi MiMo Orbit 百万亿 Token 创造者激励计划,总池子 100T tokens,面向开发者和创作者开放申请。发布后几小时内已被领走 3T 多,剩余约 96.78T。
模型定位与参数
两个模型各有侧重:
- MiMo-V2.5-Pro:主力模型,1.02T 总参数,激活 42B 的 MoE 架构,主打复杂 Agent 和 Coding 任务
- MiMo-V2.5:310B 总参数,原生全模态,强调 Agent 能力,是一个 Multimodal Agent
两个模型都支持 1M 上下文窗口。
苏米注:1T 参数 + 1M 上下文 + MIT 协议,这个组合在开源阵营里属于顶级配置。关键是 MIT 协议意味着商用完全没有限制。
Benchmark 表现
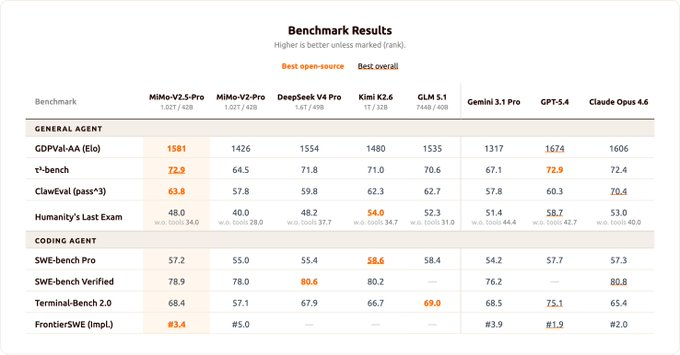
按官方 Benchmark 数据,MiMo-V2.5-Pro 对比的对象包括 DeepSeek V4 Pro、Kimi K2.6、GLM 5.1,以及闭源阵营的 Gemini 3.1 Pro、GPT-5.4 和 Claude Opus 4.6。
通用 Agent 能力
MiMo-V2.5-Pro 在三项核心指标上拿到开源第一:
- GDPVal-AA:Elo 1581(DeepSeek V4 Pro 1554、Kimi K2.6 1480、GLM 5.1 1535;GPT-5.4 1674、Claude Opus 4.6 1606)
- τ³-bench:72.9(与 GPT-5.4 持平,略高于 Claude Opus 4.6 的 72.4)
- ClawEval:pass^3 63.8(开源第一,Claude Opus 4.6 为 70.4)

开源天花板在快速上移,但顶级闭源模型仍有明确的护城河。
Coding 能力
Coding 维度上 MiMo-V2.5-Pro 表现稳健,但未形成碾压:
- SWE-bench Pro:57.2(Kimi K2.6 58.6、GLM 5.1 58.4)
- SWE-bench Verified:78.9(DeepSeek V4 Pro 80.6、Kimi K2.6 80.2、Claude Opus 4.6 80.8)
- Terminal-Bench 2.0:68.4(GLM 5.1 69.0、GPT-5.4 75.1)
- FrontierSWE:#3.4(GPT-5.4 #1.9、Claude Opus 4.6 #2.0)
在同体量、同价位段的开源模型中,MiMo-V2.5-Pro 处于第一梯队。
Token 效率:核心差异化
此次发布最值得关注的指标是Token 效率。
官方数据显示,MiMo-V2.5-Pro 在 ClawEval 上做到 64% Pass^3,平均每条轨迹只花约 70K tokens。同样的任务,Claude Opus 4.6、Gemini 3.1 Pro、GPT-5.4 大概要多花 40% 到 60% 的 token。
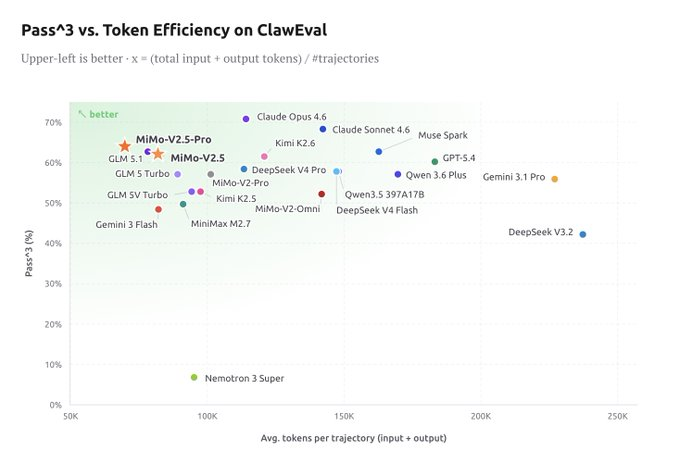
苏米注:对企业用户来说,这是一笔很实在的账。Agent 任务跑长程,token 消耗几乎和钱包一比一挂钩。同样的预算下能多跑 50% 的任务,比榜单上多 1 分实用得多。
技术架构
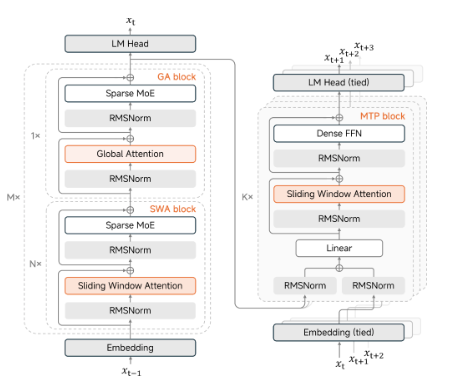
MiMo-V2.5-Pro 的技术架构亮点:
- 70 层 MoE:1 层 dense + 69 层 MoE,每层 384 个路由专家、每个 token 激活 8 个专家
- 混合注意力:滑动窗口注意力(SWA)和全局注意力(GA)按 6:1 交错,SWA 窗口 128,KV 缓存存储减少约 7 倍
- 3 层 MTP:Multi-Token Prediction 模块,推理速度提升 3 倍
- 预训练:27T tokens,全程 FP8(E4M3)混合精度
- 后训练:三段式——SFT 建立指令跟随 → 大规模 Agent RL 和领域专家训练 → MOPD 多教师蒸馏
实战案例
官方展示了几个令人印象深刻的长程任务案例:
- 4.3 小时 写完 SysY 语言的 Rust 编译器,调用 672 次工具,233 个测试用例全过
- 11.5 小时 生成 8192 行代码的视频编辑器,工具调用 1868 次
- 1 小时 完成 FVF-LDO 模拟电路设计优化
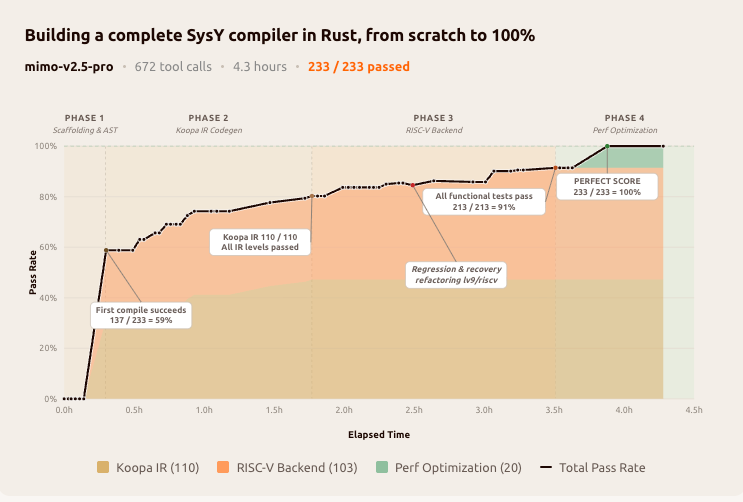
千次级别工具调用的长程任务,过去一年是开源模型的明显短板。MiMo-V2.5-Pro 把工程指标推到这个量级,证明开源阵营在 long-horizon agent 赛道上已经追了上来。
生态与部署
发布当天,SGLang 和 vLLM 就完成了适配,开发者直接拉镜像即可运行。
芯片侧 Day-0 适配清单包括:AWS、AMD、平头哥、昆仑芯、燧原、沐曦、天数智芯,从云端 GPU 到自研加速器全覆盖。
权重和代码已上传 Hugging Face(XiaomiMiMo 账号)。官方提供 API 平台(platform.xiaomimimo.com)和 AI Studio(aistudio.xiaomimimo.com),不想自己部署的用户可直接调用。
客观评价
亮点
- MIT 协议彻底放开商用
- 1M 上下文窗口
- 千次工具调用级别的长程能力
- Token 效率比闭源旗舰省 40% 到 60%
- 百万亿 Token 创造者激励池
需要注意的地方
- 与顶尖闭源仍有差距:GPT-5.4 在 GDPVal-AA、Humanity's Last Exam、Terminal-Bench 2.0 上明显领先,Claude Opus 4.6 在 GDPVal-AA、ClawEval 上分别领先 25 分和 7 分
- Coding 维度未形成碾压:SWE-bench Pro 上不如 Kimi K2.6 和 GLM 5.1,核心场景是写代码的团队需对比测试
- 部署门槛高:1.02T 参数的 MoE 至少需要 16 张 H100 级别显卡,个人开发者本地运行不现实
总结
从 2026 年 1 月至今,DeepSeek V4、Kimi K2.6、GLM 5.1,再到 MiMo-V2.5-Pro,开源大模型的迭代密度在加速。每一家都在堆参数、拉上下文、推 Agent 能力,并且都把 token 效率作为新的差异化卖点。
对于 Agent 团队来说,MiMo-V2.5-Pro 是一个真正能打的开源旗舰选择。对预算有限的团队,建议先用 API 或 AI Studio 体验,看到真实业务收益后再考虑申请 Orbit 激励池或自建集群。