小红书、公众号、B 站这些平台的数据,只需要安装一个开源 CLI 工具就可以获取?最近发现的 OpenCLI 工具,让这件事变成了现实。
苏米注:这是我用过最好使的免费 CLI 工具。很多同类工具都要收费,OpenCLI 完全免费,这点非常良心。
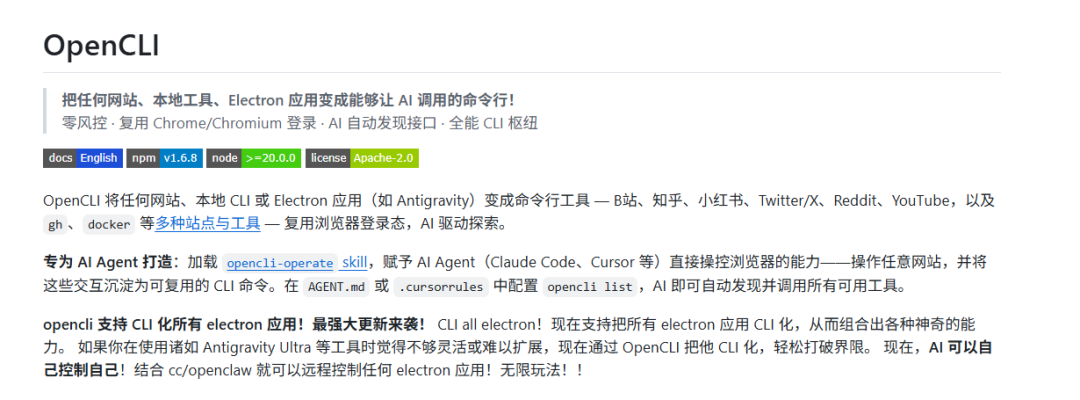
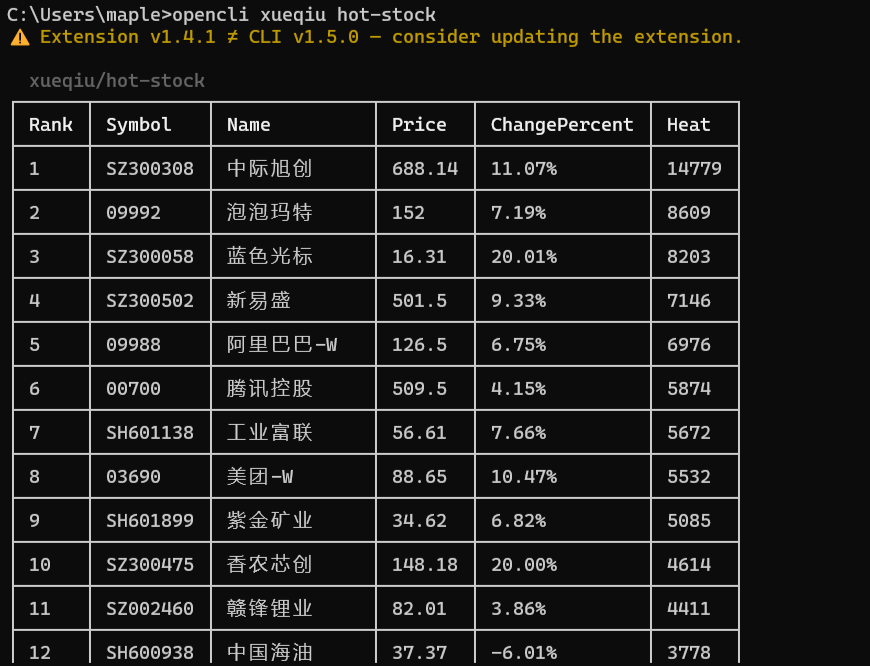
OpenCLI 支持将任意网站转化成命令行工具调用,主流社交平台如小红书、公众号、B 站等都支持下载图片、视频和内容。

目前支持的平台超过 79 个,简直就是为 AI Agent 量身打造的数据获取工具。
为什么选择 OpenCLI?
传统获取网站数据的方法一般是安装 Playwright,模拟人工操作打开浏览器、点击、获取。但这种方法有两个致命问题:
- 效率低:每次都要模拟完整操作流程
- 登录麻烦:每次都需要重新登录账号
OpenCLI 的解决方案很巧妙:每次打开网页时读取浏览器中的 Cookie 值,直接登录,无需重复认证。
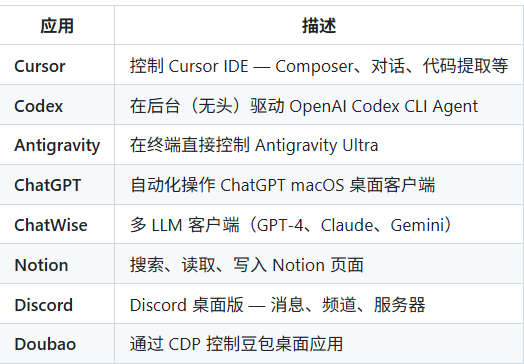
不但可以在 OpenClaw 中使用,在编程 IDE(如 Cursor)中也可以部署。
配置安装步骤
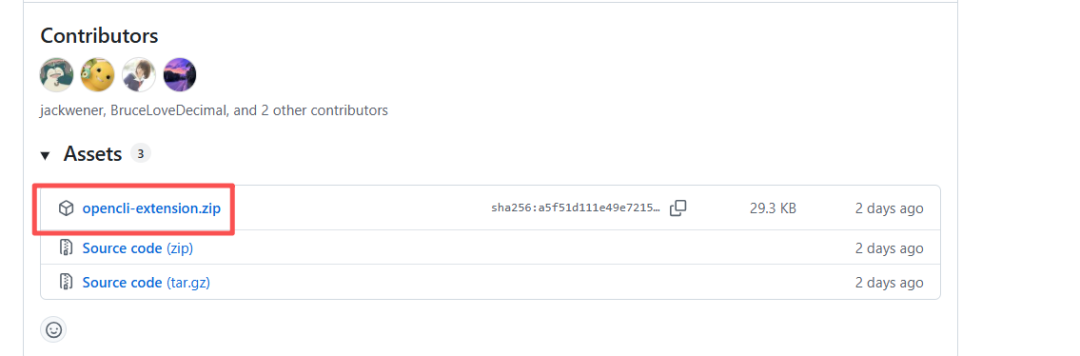
步骤一:下载浏览器插件
从 GitHub Releases 页面下载插件:
github.com/jackwener/opencli/releases
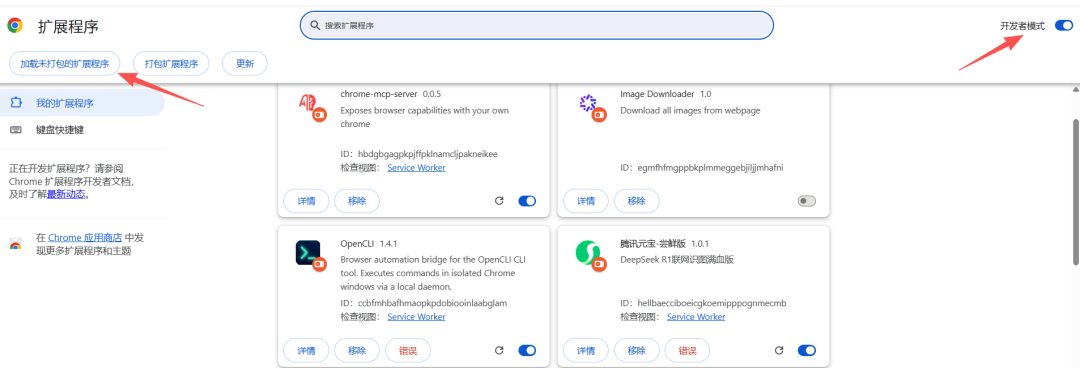
步骤二:安装插件
谷歌浏览器输入 chrome://extensions/,进入后打开开发者模式,加载已解压的扩展程序,导入刚才下载的插件。
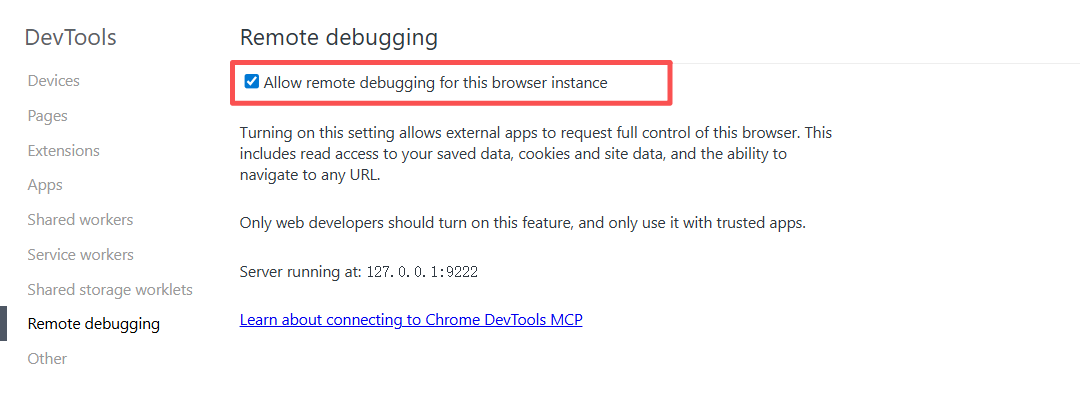
步骤三:开启远程调试
浏览器中输入:
chrome://inspect/#remote-debugging将 Remote Debugging 打开。
步骤四:安装 CLI 和 Skills
在命令窗口中运行以下两个命令:
# 1. 安装 CLI 命令
npm install -g @jackwener/opencli
# 2. 安装 Skills
npx skills add jackwener/opencli安装完成后执行 opencli list 能看到所有支持的平台。
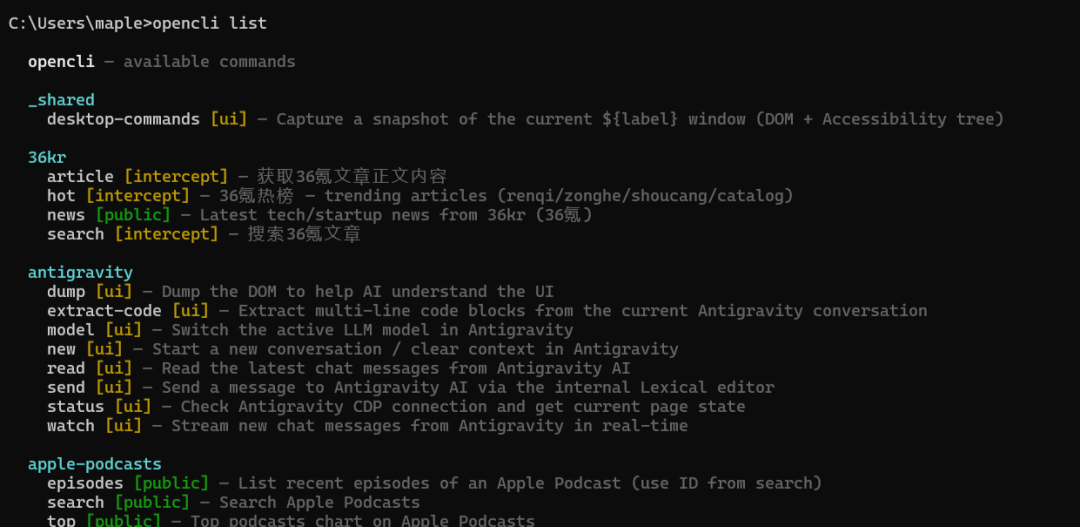
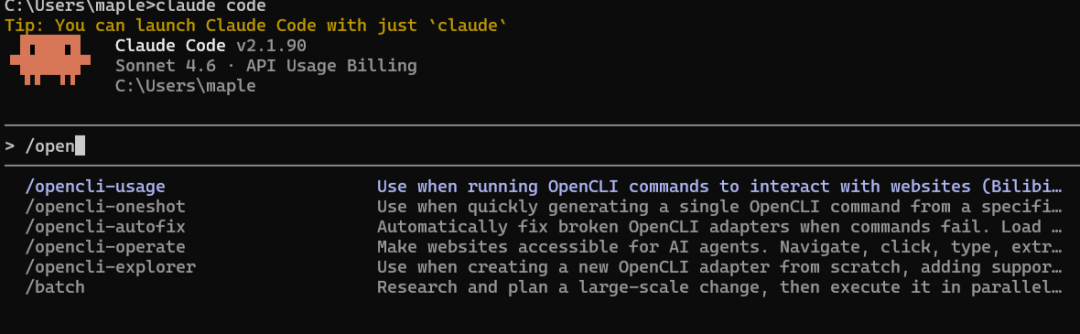
在 Claude Code 中打开,能看到以下几个 Skills:
opencli-usage:命令参考opencli-operate:浏览器自动化(AI Agent 专用)opencli-explorer:适配器开发指南opencli-oneshot:快速命令参考
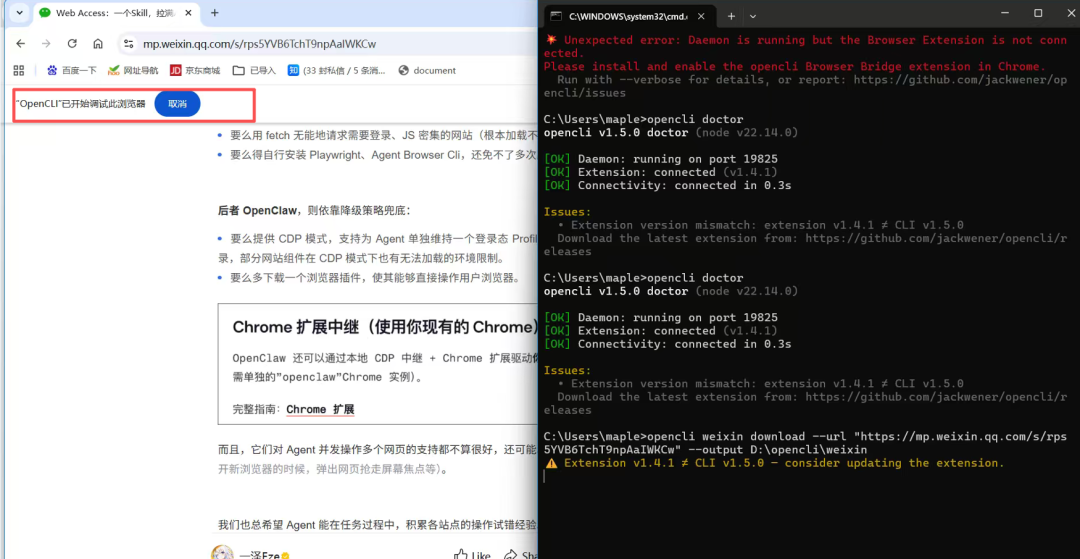
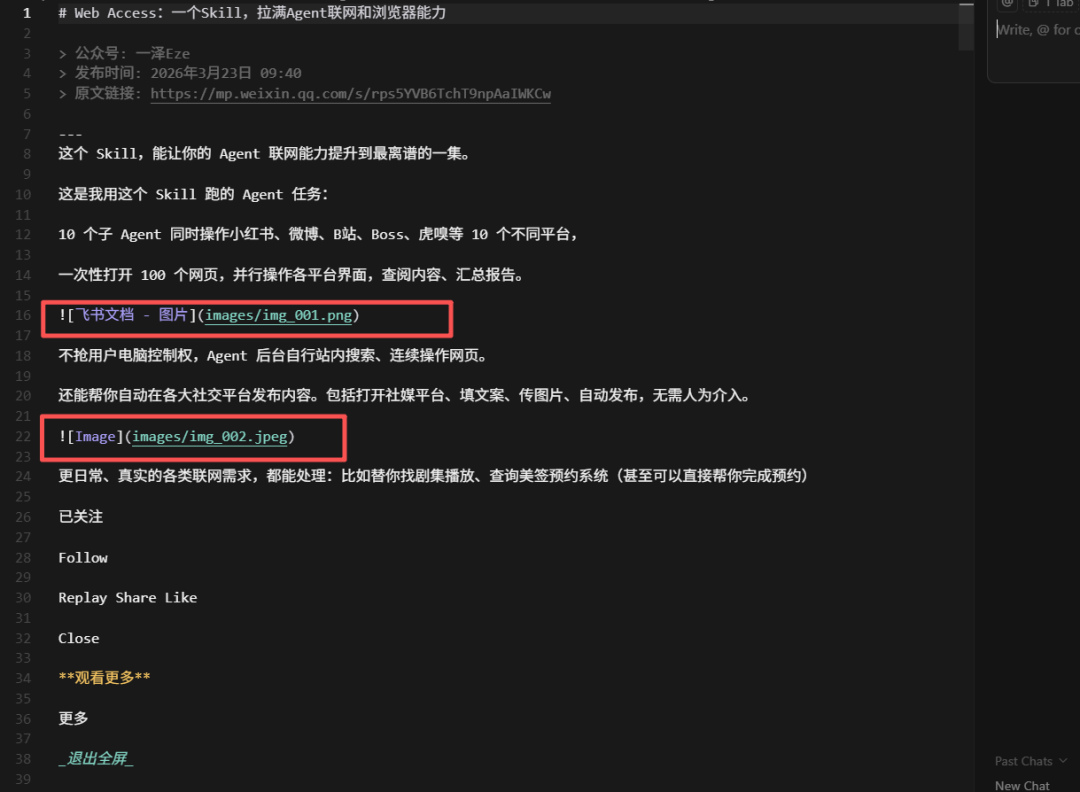
实测:下载公众号文章
公众号文章下载一直是个老大难问题。使用 OpenCLI 只需要一条命令:
opencli weixin download \
-url "https://mp.weixin.qq.com/s/xxx" \
--output D:\opencli\weixin运行后会自动打开浏览器,左上角能看到 OpenCLI 已开始调试的提示。
过一会儿就能看到下载成功的提示。

文章内容被保存成 Markdown 格式,图片则保存到 images 文件夹下。

在 Markdown 文档中,图片的位置和需要插入图片的名称也都标记好了。
实测:下载知乎内容
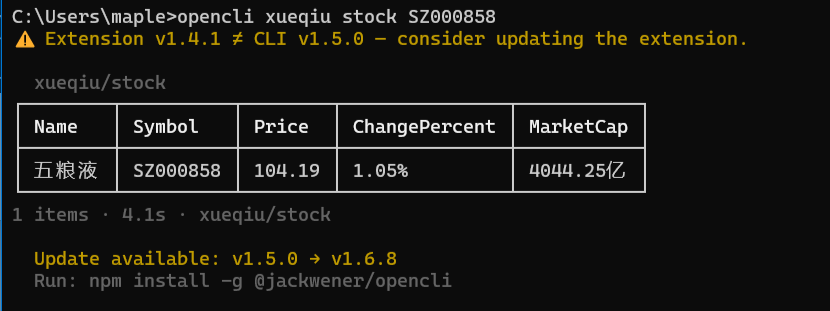
下载知乎内容同样简单,只要浏览器上登录过知乎就行,不需要重复登录:
opencli zhihu download \
--url "https://zhuanlan.zhihu.com/p/xxx" \
--output D:/zhihu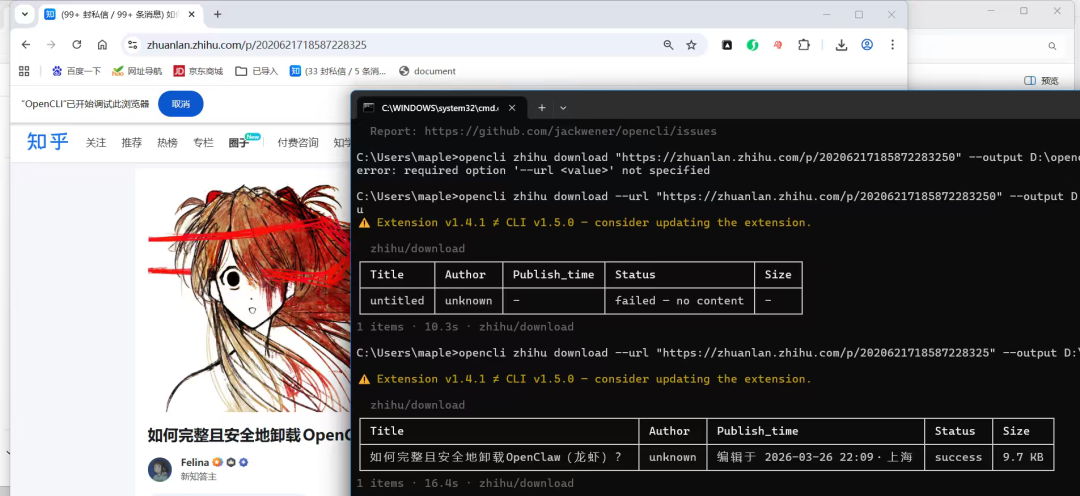
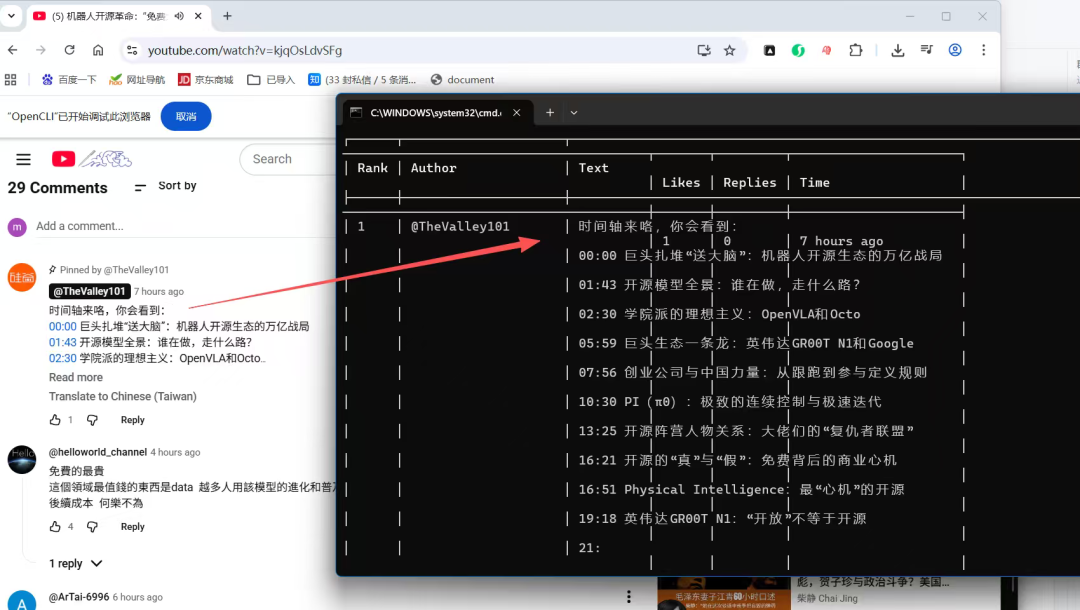
支持的平台
OpenCLI 支持的平台非常丰富,包括但不限于:
- 社交媒体:微信公众号、小红书、B 站、知乎、微博
- 视频平台:YouTube、抖音、快手
- 新闻网站:各大新闻门户
- 电商平台:淘宝、京东、拼多多
- 其他:GitHub、Stack Overflow 等
苏米注:79+ 个平台的覆盖面非常广,基本涵盖了主流的内容平台。对于需要做数据采集、内容分析的场景,这个工具非常实用。
典型使用场景
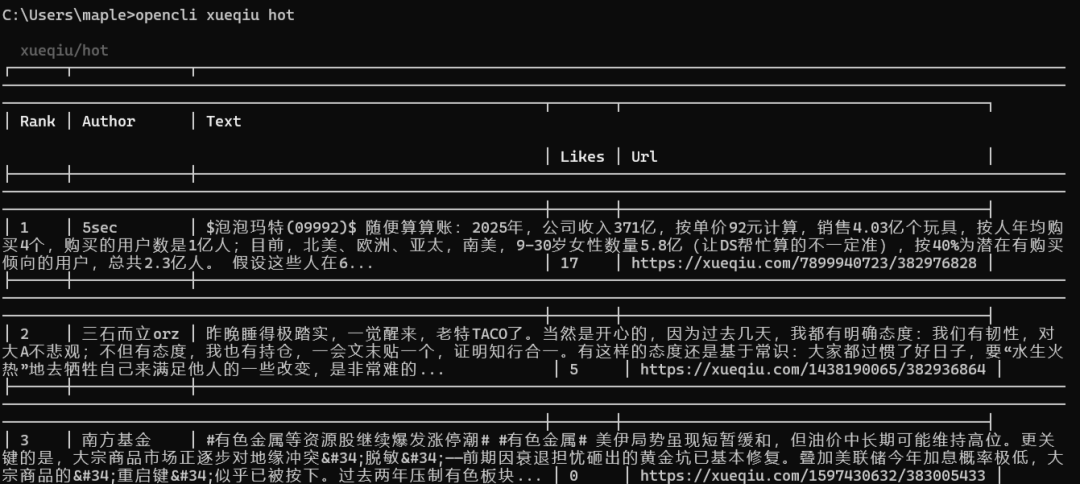
场景一:AI Agent 数据获取
在 OpenClaw 或其他 AI Agent 中集成 OpenCLI,让 AI 能够自主获取最新的网络数据。
场景二:内容归档备份
定期下载公众号文章、知乎回答等内容,建立个人知识库。
场景三:竞品分析
批量下载竞品内容,进行数据分析和内容研究。
场景四:自动化工作流
结合定时任务,自动下载指定内容并处理。
注意事项
- Cookie 安全:OpenCLI 会读取浏览器 Cookie,确保在可信环境中使用
- 平台规则:遵守各平台的使用条款,不要用于违规用途
- 频率限制:避免短时间内大量请求,可能被平台封禁
- 数据隐私:下载的内容注意版权和隐私问题
总结
OpenCLI 是一款强大且免费的 CLI 工具,让数据获取变得异常简单。无论是个人使用还是集成到 AI Agent 中,都能显著提升效率。
苏米注:免费、开源、持续维护,这样的工具值得推荐。如果你有数据采集、内容下载的需求,OpenCLI 值得一试。