OpenDataLoader PDF:开源 PDF 解析新方案,综合精度 0.90 领先同类工具
在构建 RAG(检索增强生成)应用时,PDF 文件解析是一个关键挑战。多栏论文读取顺序混乱、表格变成乱码、数学公式丢失、扫描版 PDF 无法识别——这些问题几乎每个开发者都遇到过。
最近 GitHub 上出现了一个开源项目 OpenDataLoader PDF(目前已获 11K+ Star),它专为 AI 数据管道设计,是少数能全流程处理 PDF 无障碍合规的开源方案。
性能表现
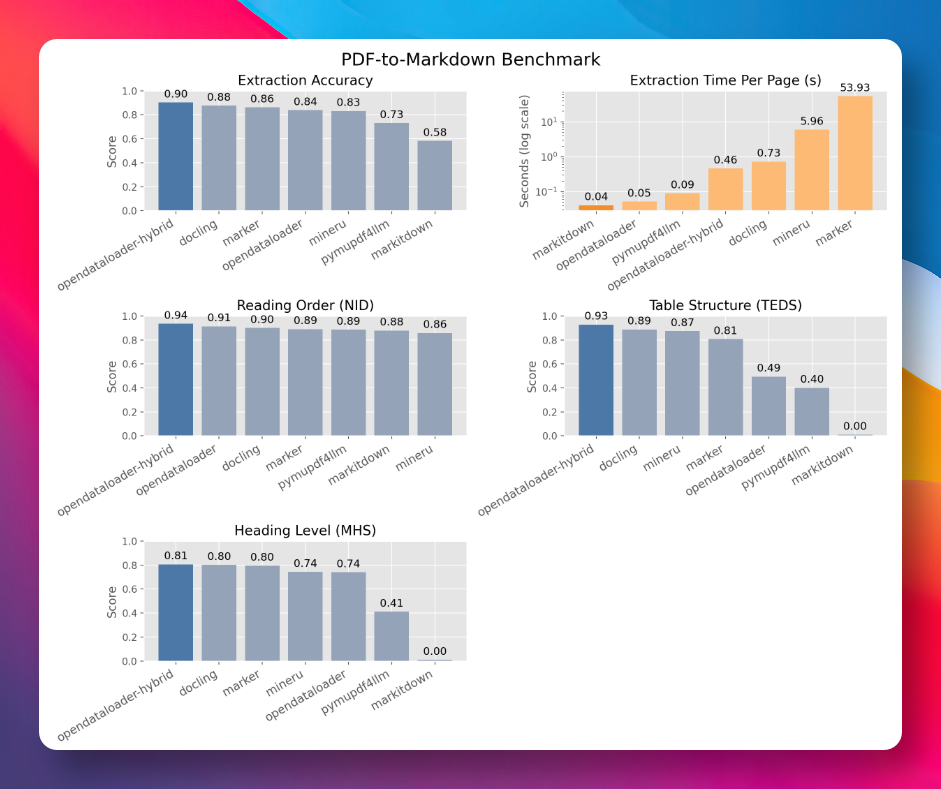
在包含 200 份真实 PDF(含多栏文档、学术论文)的第三方 benchmark 中,OpenDataLoader PDF 综合精度得分 0.90,表格提取精度 0.93,位居第一。
与主流工具对比:
| 工具 | 综合精度 |
|---|---|
| OpenDataLoader PDF | 0.90 |
| Docling | 0.88 |
| Marker | 0.86 |
| PyMuPDF4LLM | 0.73 |
核心特性
1. 本地运行,数据不出境
无需 GPU,不联网,数据完全本地处理。本地模式速度为 0.05 秒/页,在 8 核机器上批量处理吞吐量可超过 100 页/秒。
苏米注:对于法律、医疗、金融等对数据隐私要求高的场景,"数据不出境"这一特性非常关键。
2. Hybrid 模式:智能路由复杂内容
遇到复杂表格、无边框表格、扫描 PDF、数学公式、图表等复杂内容时,本地模式容易出错。Hybrid 模式的策略是:
- 简单页面继续本地运行(0.05 秒/页)
- 检测到复杂内容自动路由给 AI 后端处理
- 后端同样运行在本机,不上云
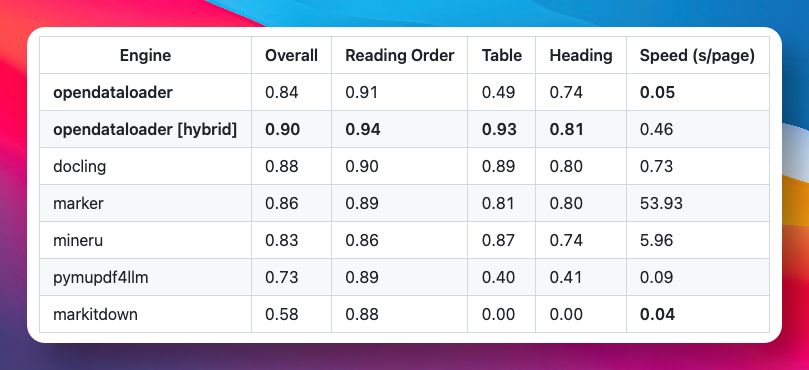
开启 Hybrid 模式后,表格精度从 0.49 提升至 0.93。
3. 多语言 OCR 支持
扫描件使用 --force-ocr 参数,支持中文、韩文、日文、阿拉伯文等 80 多种语言。
4. 公式与图表处理
公式提取输出标准 LaTeX 格式,图表自动生成 AI 描述文本,解决 RAG 中图表内容无法被检索的问题。

5. 多种输出格式
支持 Markdown、JSON、HTML 输出。JSON 输出中每个元素都带边界框坐标和页码,支持"点击溯源"交互体验——不仅能拿到文本,还能精确定位到原始 PDF 的具体段落、表格、图片。
6. 安全特性
内置 prompt injection 防护,自动过滤 PDF 中隐藏的透明文字、离页内容、可疑图层,在喂给 LLM 之前先清洗一遍。
安装与使用
基础安装
pip install opendataloader-pdfHybrid 模式安装
# 安装 Hybrid 包
pip install "opendataloader-pdf[hybrid]"
# 终端 1:启动后端
opendataloader-pdf-hybrid --port 5002
# 终端 2:处理文档
opendataloader-pdf --hybrid docling-fast file1.pdf file2.pdf基本用法
import opendataloader_pdf
opendataloader_pdf.convert(
input_path=["file1.pdf", "folder/"],
output_dir="output/",
format="markdown,json"
)LangChain 集成
pip install langchain-opendataloader-pdf前置条件
需要 Java 11+,运行前用 java -version 确认。
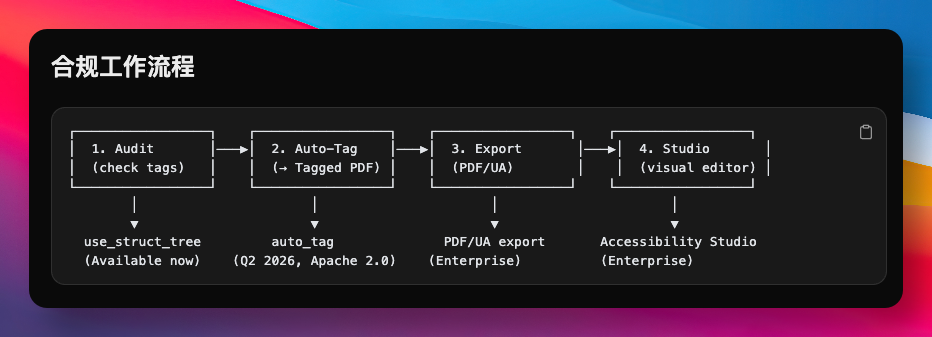
PDF 可访问性合规
OpenDataLoader 使用同一套版面分析引擎,自动给无标签 PDF 生成结构标签,输出 Tagged PDF。
这是开源方案中少有的路径——不依赖任何商业 SDK,采用 Apache 2.0 协议。项目与 PDF Association 和 veraPDF 开发团队 Dual Lab 合作,按照 Well-Tagged PDF 规范构建,输出结果通过 veraPDF 自动验证。
总结
RAG 应用的上限很大程度上取决于数据管道的质量。模型可以更换,提示词可以调整,但文档解析层如果质量不佳,后续优化效果有限。
OpenDataLoader PDF 的优势在于:
- 综合精度领先同类开源工具
- 本地运行,数据隐私有保障
- Hybrid 模式智能处理复杂内容
- 支持 PDF 可访问性合规
- Apache 2.0 协议,免费开源