最近在整理开源AI项目时,发现了一个有意思的现象:很多开发者在寻找TTS(文本转语音)方案时,往往陷入一个困境——要么模型动辄几百MB,要么必须依赖GPU和云服务。
而实际上,许多应用场景(比如嵌入式设备、离线场景、隐私敏感的应用)对模型大小和运行环境的要求并不高,反而对稳定性和成本更敏感。
今天要介绍的KittenTTS,正是在这样的背景下诞生的一个有趣的开源项目。
项目概览
KittenTTS是由KittenML团队开发的轻量级文本转语音模型,采用Apache 2.0开源协议,在GitHub和ModelScope上均有部署。
项目的核心定位很直接——提供一个参数量精简、部署门槛低的开源TTS解决方案。
项目提供三个版本梯度,适配不同的应用需求:
| 版本 | 参数量 | 模型大小 | 定位 |
|---|---|---|---|
| Nano | 1500万 | ~25MB | 极致轻量,优先考虑部署约束 |
| Micro | 4000万 | ~41MB | 平衡效率与质量 |
| Mini | 8000万 | ~80MB | 较高的合成质量 |
核心特性
1. CPU原生支持,无GPU依赖
与市面上多数TTS模型不同,KittenTTS针对CPU推理进行了优化。
实测推理性能约为1秒生成10个单词,在树莓派4/5等边缘设备上均可流畅运行。这种设计对于资源受限的嵌入式环境具有实际价值。
2. 完全离线推理
首次下载模型后,后续推理完全离线执行。这意味着:
- 在无网络覆盖场景下可用(车载系统、野外设备等)
- 用户文本数据不上传至云端,满足隐私合规需求
- 无网络延迟,推理延时完全由本地硬件决定
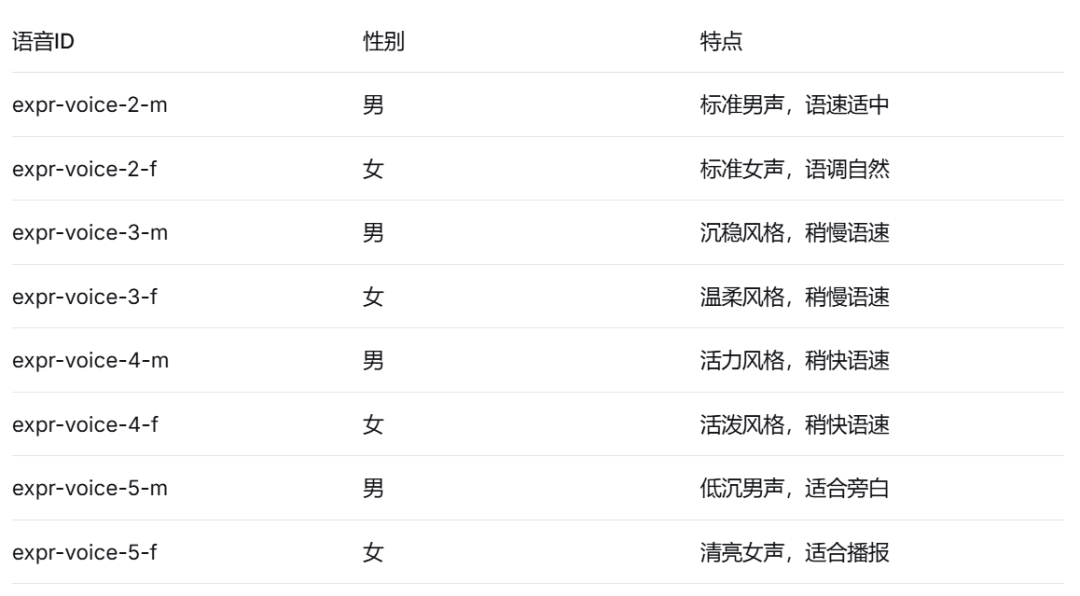
3. 内置多种预训练音色
模型提供8种真人音色库,开箱即用,无需用户自行训练或微调。
应用场景分析
基于上述特性,KittenTTS的适配场景包括但不限于:
- 嵌入式/IoT应用:为树莓派、单片机等低功耗设备集成语音播报功能
- 移动端离线应用:App内置语音功能,降低安装包体积增量
- 成本敏感项目:避免按调用字符数付费的云服务API成本
- 隐私敏感业务:本地闭环处理,满足数据保留要求
部署与使用
快速体验
可在Hugging Face Spaces上直接在浏览器中测试KittenTTS的合成效果,无需本地部署。
本地部署步骤
典型的部署流程如下:

# 步骤1:环境安装
pip install kittenTTS
# 步骤2:Python代码调用
from kittenTTS import KittenTTS
model = KittenTTS()
audio = model.synthesize(text="你好世界", speaker=0)
# 步骤3:音频输出
# 使用任意音频播放器打开生成的output.wav文件
整个流程的技术门槛较低,主要依赖即为Python环境。

对标项目参考
为更清晰地理解KittenTTS的定位,可参考几个同类项目的对比维度:
- glow-TTS / FastPitch:学术导向,参数量更大,质量更高但部署要求更高
- VITS:广泛使用但模型文件通常在50MB以上,对硬件要求更高
- 云服务API(Google Cloud TTS、Azure等):质量最高但需付费、依赖网络、数据离线要求难以满足
KittenTTS的差异化优势在于:以轻量级和离线能力作为核心权衡,适配那些对模型大小和网络依赖有硬约束的场景。
总结
从产品经理的角度来看,KittenTTS解决的是一个典型的约束优化问题——在确定使用场景的硬件和网络约束前提下,找到功能与质量的可接受平衡点。相比宣传"最强""全能"的产品,这类务实的开源项目反而更有参考价值。
特别是对于那些正在做嵌入式产品、离线应用或成本敏感项目的开发者,KittenTTS提供了一个低试错成本的尝试方向。模型本身也在持续迭代,未来的版本可能会在音质或语言支持上有进一步优化。
如果你的项目对TTS有需求,不妨先在Spaces上体验一下效果,再决定是否引入。这样的小项目,往往能在特定场景下带来超出预期的价值。