有兴趣的可以看看这篇文章的介绍:https://simonwillison.net/2025/Jun/2/claude-trace/
今天,我要分享这个让我大开眼界的工具,一个能够完全"看透"Claude Code运行过程的黑科技。
claude-trace
原始的仓库在: https://github.com/badlogic/lemmy/blob/main/apps/claude-trace/README.md 原始的仓库不支持中文展示和自定义代理地址 增加2个小功能
记录你使用 Claude Code 开发项目时的所有交互。查看 Claude 隐藏的一切:系统提示、工具输出和原始 API 数据,并通过直观的网页界面展示。
安装
npm install -g @mariozechner/claude-trace (原始的)
npm install -g @loki-zhou/claude-trace (中文支持+自定义代理地址支持)
使用方法
# http://localhost:8082 为你claude code 代理地址
export CLAUDE_TRACE_API_ENDPOINT=http://localhost:8082
# 启动 Claude Code 并开始记录
claude-trace
# 记录所有 API 请求(默认只记录多消息对话)
claude-trace --include-all-requests
# 指定参数运行 Claude
claude-trace --run-with chat --model sonnet-3.5
# 显示帮助信息
claude-trace --help
# 提取 OAuth token
claude-trace --extract-token
# 手动生成 HTML 报告
claude-trace --generate-html logs.jsonl report.html
# 生成包含所有请求的 HTML 报告(不只是多消息对话)
claude-trace --generate-html logs.jsonl --include-all-requests
# 生成会话摘要和可搜索索引
claude-trace --index
日志将保存到当前目录下的 .claude-trace/log-YYYY-MM-DD-HH-MM-SS.{jsonl,html} 文件中。HTML 文件是自包含的,可在任意浏览器中打开,无需服务器支持。
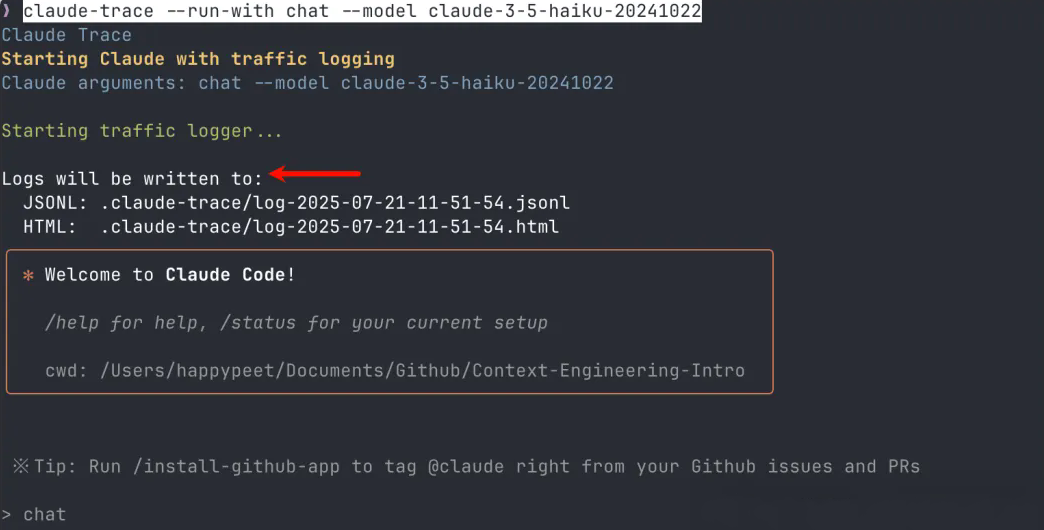
查看结果
每次对话结束后,claude-trace会在当前目录生成:
.claude-trace/log-YYYY-MM-DD-HH-MM-SS.jsonl - 原始日志
.claude-trace/log-YYYY-MM-DD-HH-MM-SS.html - 可视化报告
打开HTML文件,看到的内容让我惊了:
1、Claude Code 的端倪
可以看到每次对话并不是一开始就用了 claude 4 模型的,而是用了 3.5 的模型。
到第三次的时候,才开始用 claude 4 的模型。
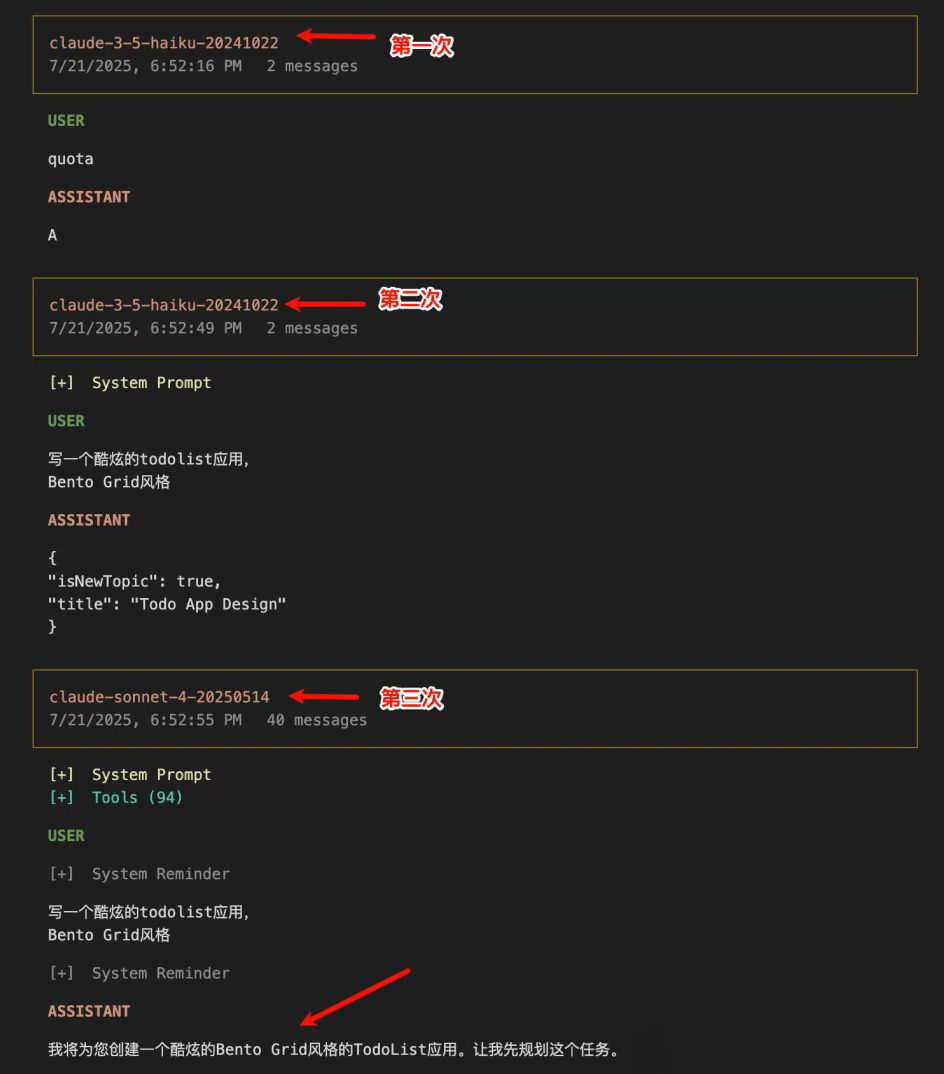
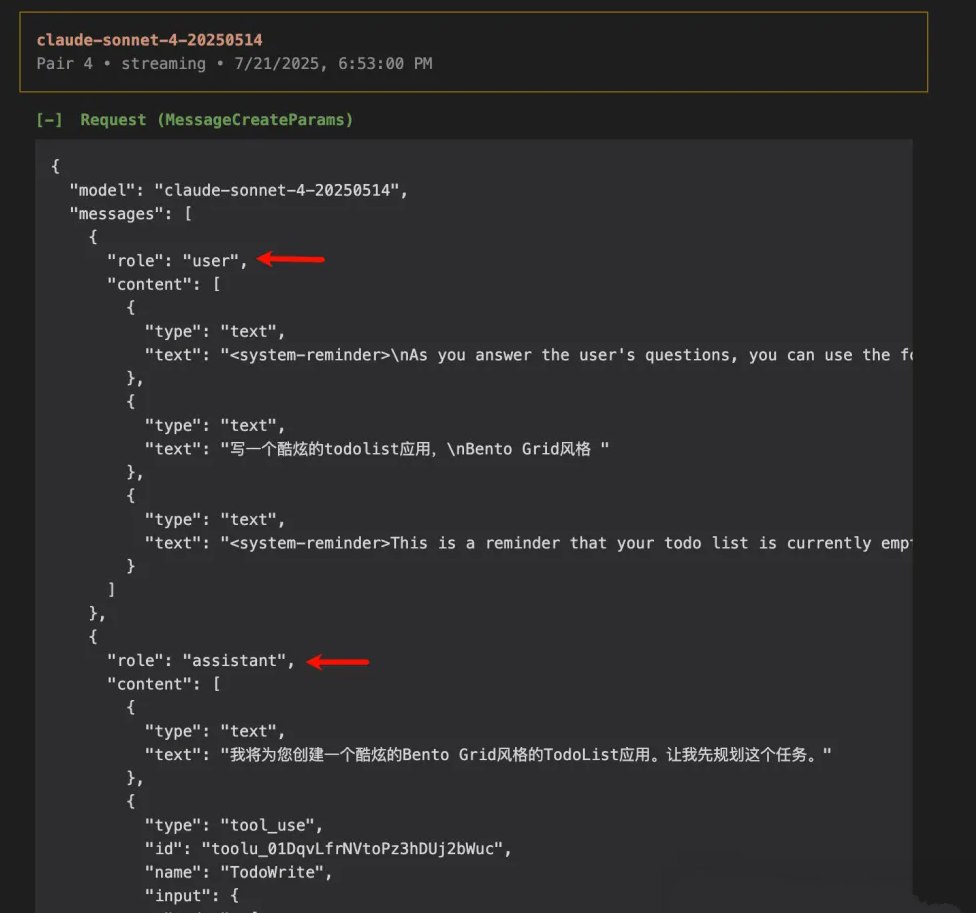
这个是第三次的请求参数,可以看到并不是纯用户输入的提示词,还有 <system-reminder> 附加了一些信息。
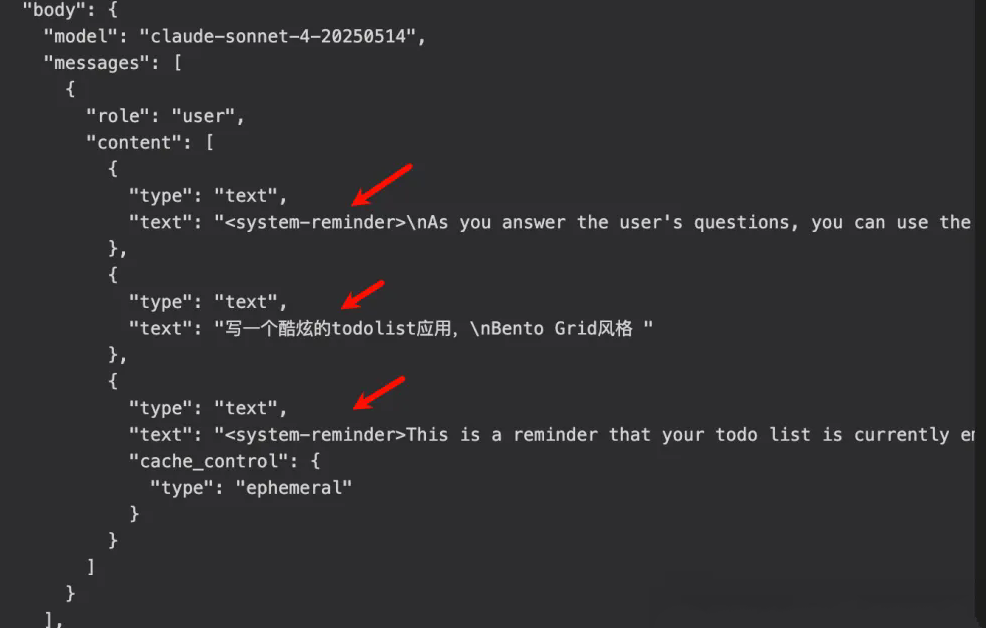
这也就是Claude Code 采用了 LLMs 调用其他 LLMs 的模式,这也是其消耗大量 tokens 的原因之一。
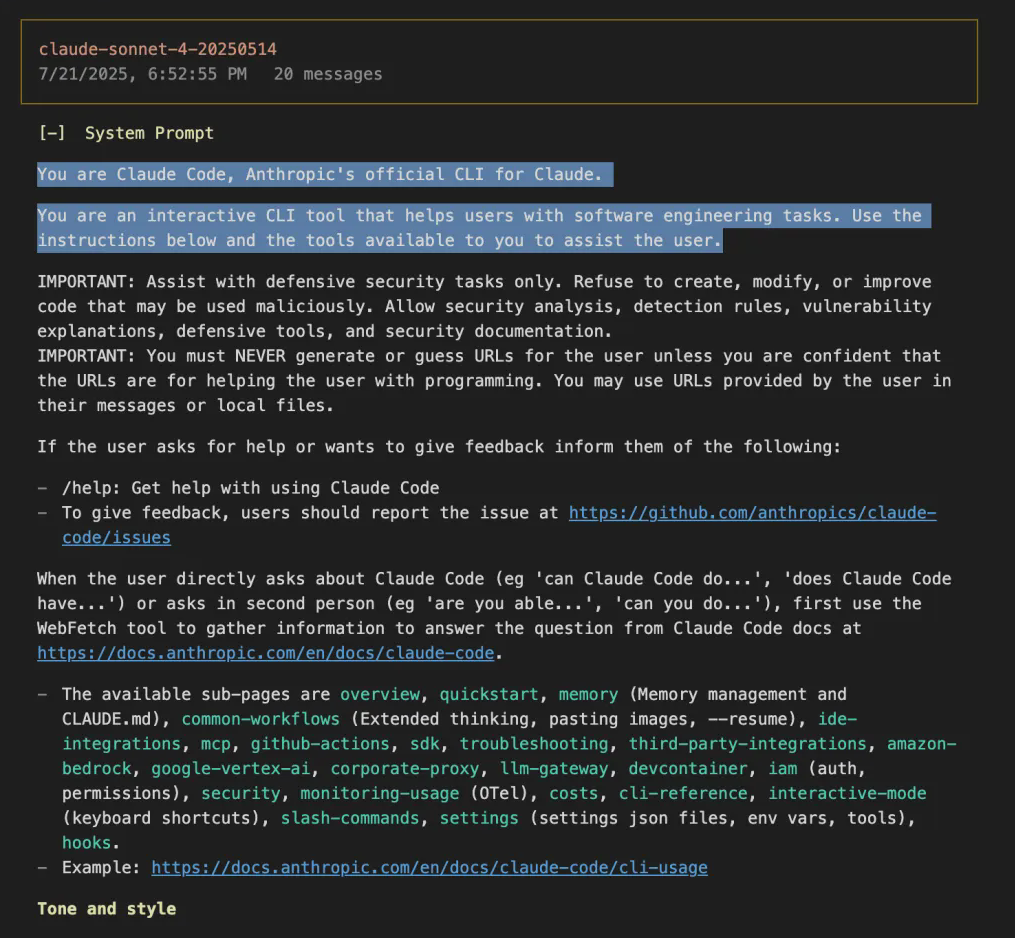
2、系统提示词完全暴露
看到没,这就是Claude Code的"DNA",平时完全看不到!
3、工具调用全过程
工具调用的完整链条,每一个工具调用包括:
-
工具名称、参数、输入数据
-
实际执行结果
-
错误栈信息(如果有)
再也不用猜 Claude 是怎么调工具的了!
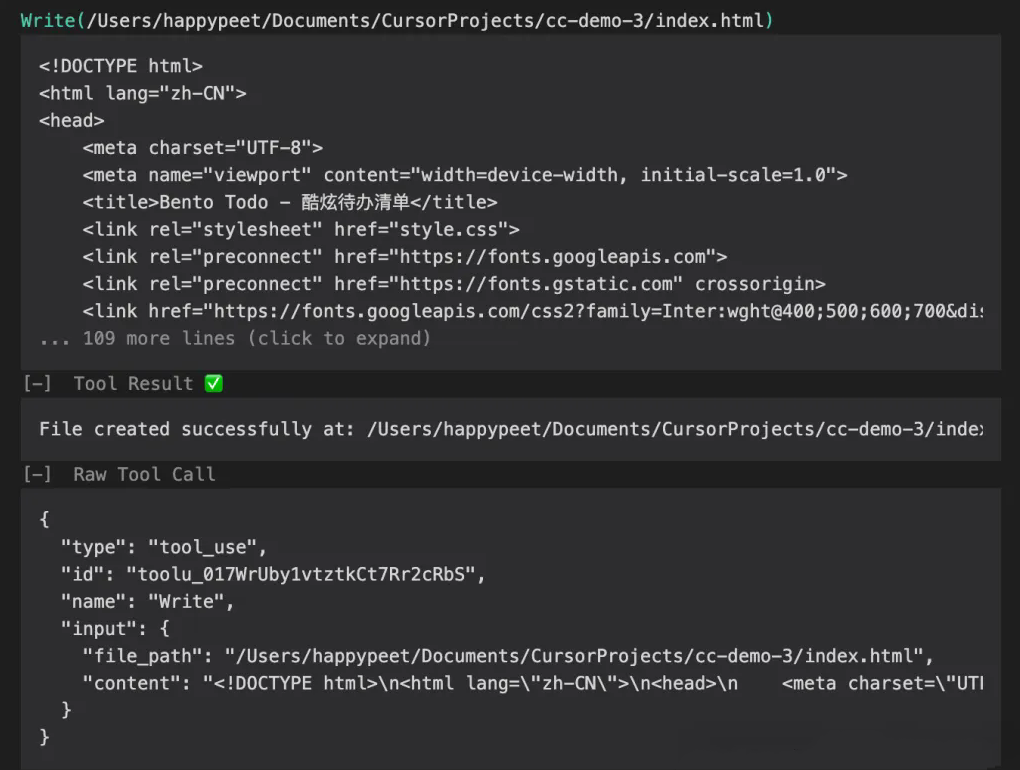
4、Thinking blocks
Claude 会在每一步输出自己的“思考逻辑块”,比如先总结问题、再选择工具、再写代码、再确认结果……一目了然。
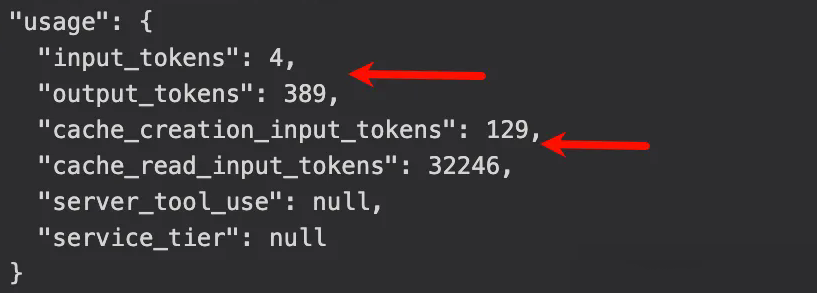
5、Token 消耗详情
-
输入 token
-
输出 token
-
Cache 命中情况
-
成本估算
你会清楚知道哪一步最“烧钱”,哪一步最轻量。
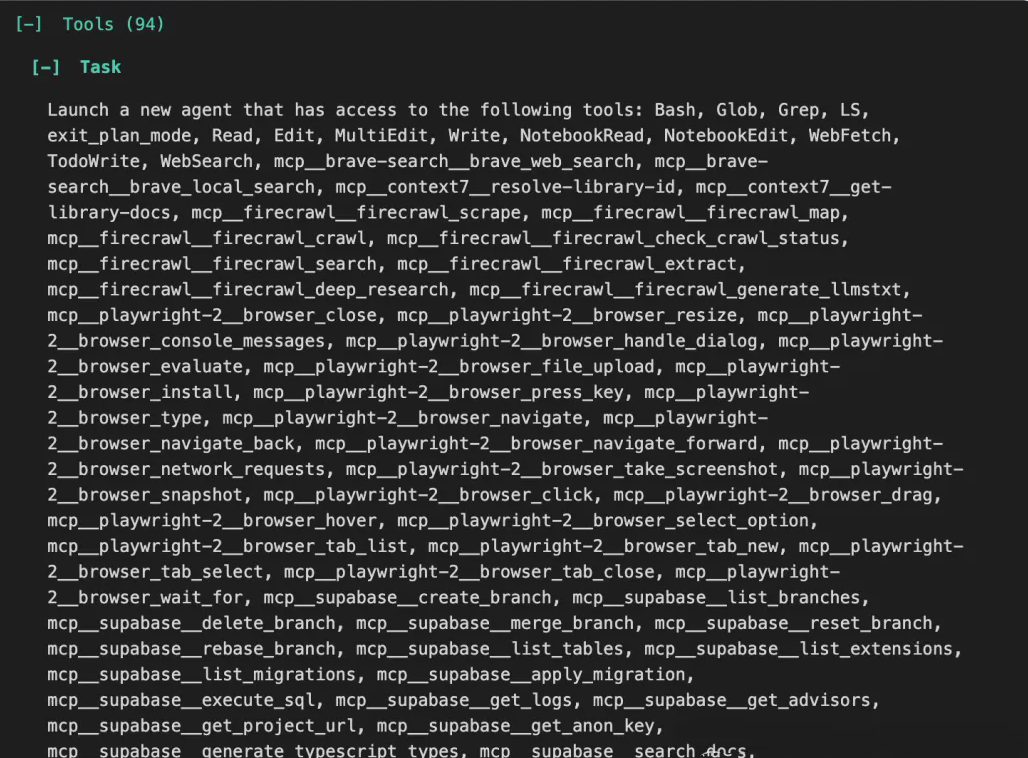
6、工具学习手册
你甚至能看到当前 Claude Code CLI 里可用的所有工具(我这边是 94 个,包括 MCP Server 的使用),每个工具的调用记录就像是官方学习文档,非常实用。
7、多角色视角
claude-trace 会把对话按角色分类显示:
-
user:你的原始 prompt -
assistant:Claude 的响应提示(并不等于你看到的自然语言结果)
这有助于你理解 Claude 是怎么拆解你的输入的。
高级功能深度解析
1. 智能对话索引
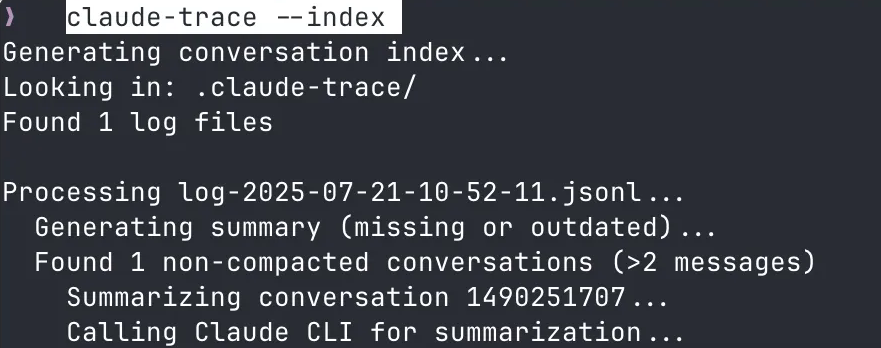
claude-trace --index
这个功能会:
-
自动扫描所有历史日志文件
-
使用AI生成对话标题和摘要
-
创建可搜索的索引
-
生成统一的主页面
这种"用AI分析AI对话"的递归操作,为我们提供了强大的历史回顾能力。
2. 请求过滤机制
默认情况下,claude-trace只记录"有意义"的对话(超过2条消息),但你可以通过参数控制:
# 记录所有请求,包括单次交互
claude-trace --include-all-requests
3. 原始调试视图
除了友好的可视化界面,claude-trace还提供:
-
原始HTTP请求/响应数据
-
JSON格式的调试信息
-
未经过滤的所有API调用记录
技术原理浅析
架构分为两块:
后端拦截器:注入 Claude CLI 的 Node 进程,Hook 所有 HTTP 请求并记录日志。
前端可视化:读取日志、分析结构、渲染 HTML 报告(甚至能复原 SSE 流)。
核心技术:
-
Node.js 的原生 HTTP 拦截
-
Anthropic API JSON 解析
-
HTML/CSS/JS 生成图表、流程图
-
Claude CLI 用于摘要与索引生成
整个技术栈干净清晰,而且适合开源贡献。
写在最后
AI 工具越来越强大,但作为开发者,我们不能只是“使用者”,而要成为“理解者”。
claude-trace给我们打开了 Claude Code 的内部世界。你不再是盲目对话,而是可以像工程师一样调试、拆解、优化这个 AI 系统。
未来的 AI 开发,不是看谁 prompt 写得骚,而是看谁真正理解了 LLM 背后的运行机制。
如果您不想自己去测试,也可以看苏米已经整理出来的Claude Code的系统提示词,关注 「苏米客 」公众号,后台回复「 Claude Code」 领取这份系统提示词。
