最近在刷GitHub开源项目时,发现了一个有意思的现象:当整个AI产业还在疯狂堆砌参数规模的时候,有团队却走了完全不同的路线。
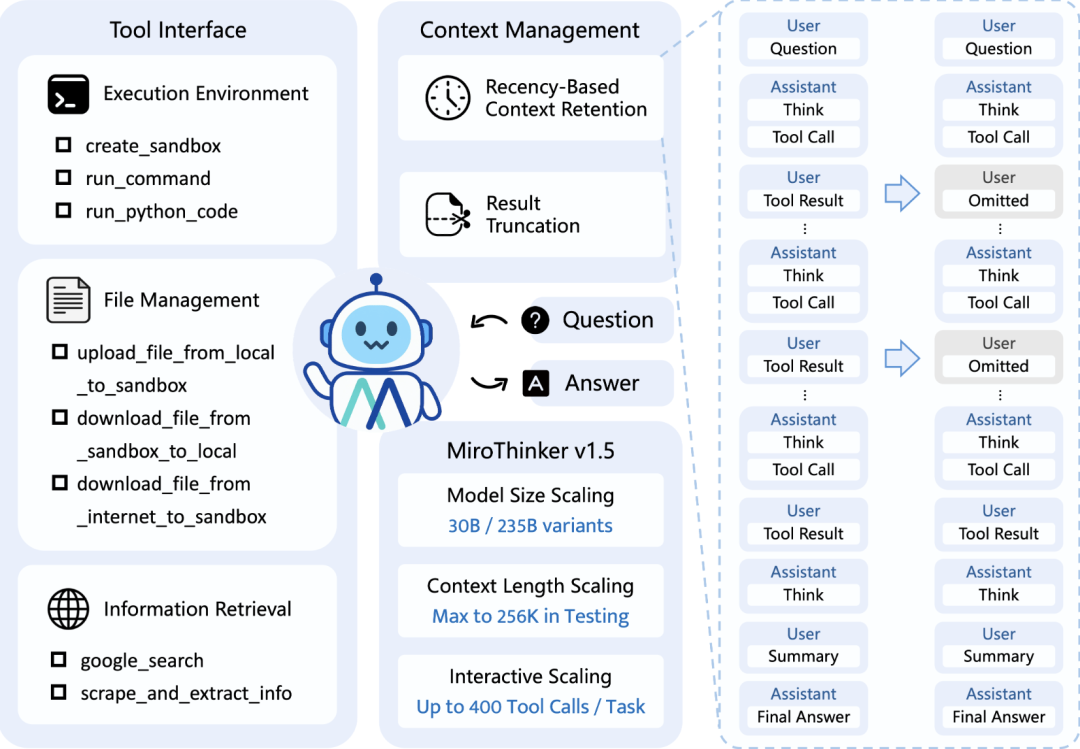
MiroMind AI开源的MiroThinker v1.5引起了我的关注,2300+点赞的搜索Agent,核心逻辑很简洁:与其让模型死记硬背,不如教它像研究员一样"向外求助"。这个思路值得深入了解。
项目概览
MiroThinker是一个基于交互式扩展技术(Interactive Scaling)的开源搜索Agent框架。

与传统大模型在封闭参数空间内进行线性推理不同,它的核心设计理念是构建一个能够主动利用外部工具和网络信息的推理系统。
GitHub地址:https://github.com/MiroMindAI/MiroThinker
核心功能特性
MiroThinker在BrowseComp等标准测试基准上的表现值得关注:
在BrowseComp测试中超过ChatGPT-Agent的表现
在BrowseComp-ZH(中文测试集)上超越Kimi-K2-Thinking
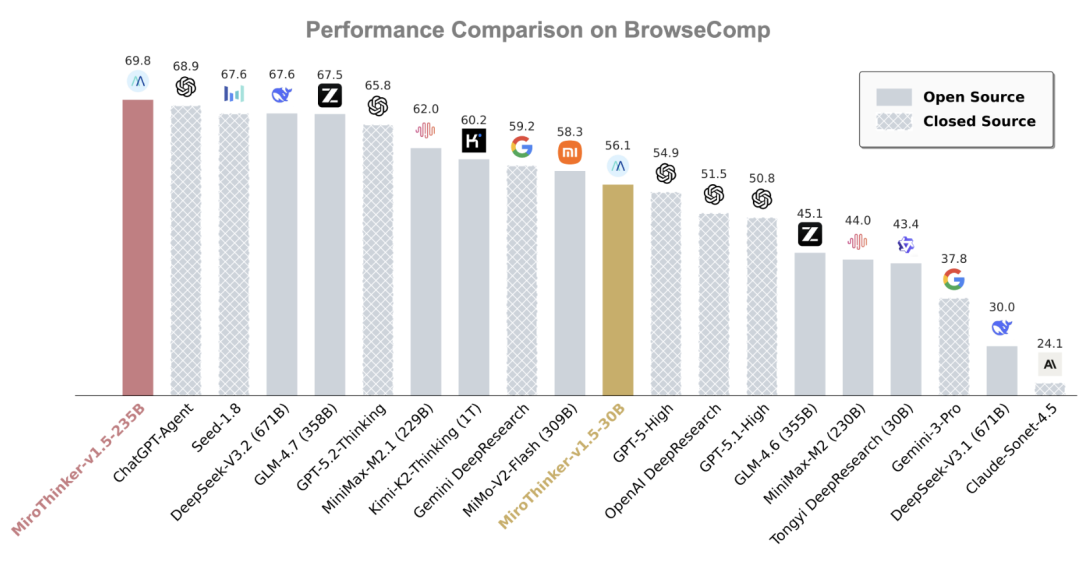
成本优势显著:仅使用对标产品1/30的参数量
这组对比数据反映了一个重要的技术转向:模型性能提升不一定依赖于参数规模线性增长。
工作机制分析
MiroThinker的运作逻辑可以归纳为三个关键环节:
| 工作环节 | 具体表现 |
| 主动求证 | 遇到不确定问题时,系统会拆解问题结构,通过搜索和网页浏览主动检索证据,而非依赖内部参数的概率估计 |
| 多轮修正 | 建立"推理-验证-修正"的闭环。当外部证据与初始假设产生冲突时,系统自动调整推理路径,直到证据收敛 |
| 证据驱动 | 在训练阶段系统性惩罚缺乏信源的高置信度回答,强制模型养成"无证据不开口"的推理习惯 |
应用场景示例
场景1:市场调研 - 2026年全球AI大模型竞争格局
用户输入单一提示词,MiroThinker执行了30多次搜索和10多次网页浏览,最终输出的分析报告呈现了类似资深研究员的工作质量。值得注意的是,它正确识别并纳入了Google Gemini 3和Nano Banana等2025年新发布的模型信息,这类时间敏感的内容恰好是传统模型的薄弱环节。
场景2:信息整合 - 深度行业研究
以Manus(机械臂初创公司)的核心成员访谈调研为例,系统能够聚合多份访谈记录,梳理公司立项和发展历程,核心信息覆盖完整。这类需要多源信息整合和内容理解的任务,对Agent的信息检索和归纳能力有较高要求。
场景3:结构化数据采集
输入"北京明星AI初创公司"后,系统能够输出包含公司名称、业务范围、融资信息、产品线和赛道分类的结构化结果,适用于竞争分析和产业研究。
场景4:概率推理而非精准预测
面对"A股春节前走势"这类不确定性高的问题,MiroThinker采取了务实的方法:放弃精准点位预测,而是通过叠加历史"春节效应"数据、当前政策环境和市场趋势,构建一个合理的波动区间作为参考。这反映了系统对自身能力边界的理性认识。
部署与使用门槛
从开源生态角度,MiroThinker提供了多种接入方式:
- 云端体验:无需本地部署,直接在https://dr.miromind.ai/访问,适合快速试用
- 本地部署:支持从Hugging Face下载235B参数模型,进行自建部署
- 开源可获得性:GitHub上提供完整代码,支持二次开发
235B的模型规模属于中等水平,相比千亿参数模型的部署成本更低,对算力需求较为友好。
相关对标项目
在开源搜索Agent领域,还有几个值得关注的类似项目:
- OpenAI o1系列:官方的思维链推理模型,但非开源且成本较高
- Perplexity及其开源版本:面向信息检索的Agent,侧重搜索结果聚合
- LangChain/LlamaIndex:Agent开发框架,需要自行组织工具链,学习曲线较陡
MiroThinker的差异化在于:它不仅提供框架,更提供了一个经过专门训练的、开箱即用的推理模型。
技术特征小结
| 维度 | MiroThinker | 传统大模型 |
| 推理方式 | 交互式外部求证 | 参数内推理 |
| 信息更新 | 实时搜索获取 | 训练数据截止 |
| 参数规模 | 235B | 通常700B+ |
| 成本-性能比 | 较优 | 线性消耗 |
| 适用任务 | 需要实时信息和深度研究的任务 | 通用推理和生成 |
结语
在体验过MiroThinker之后,我的感受是:这个项目代表了一条不同的技术思路。
当业界还在问"下一代模型要多大参数"时,MiroThinker在问"模型应该如何更聪明地利用外部世界"。
从产品经理的角度看,它的价值不仅在于基准测试的超越,更在于它提供了一个可供复用和迭代的、开源的Agent框架。
对于需要处理时间敏感信息、进行深度研究或复杂决策的场景,这个项目提供了一个明确的技术选项。
参数堆砌遵循的是Scaling Law,但真正的AGI可能需要遵循另一套法则——它应该是一个懂得提问、善于求证、能够自我修正的系统,而不仅仅是一个更大的做题家。
MiroThinker目前在这个方向上的探索值得关注。