在浏览和体验众多AI产品的过程中,我发现大多数面试辅助工具要么功能单一,要么部署复杂、学习成本高。
最近接触到的 Interview Guide 项目让我眼前一亮——它用相对现代的技术栈(Spring Boot 4.0、Java 21、Spring AI)实现了从简历分析到AI面试再到知识库问答的完整链路,同时保持了较低的上手门槛。
今天想和大家分享这个项目的实际价值和技术特点。
项目概览
Interview Guide 是一个开源的智能面试平台,核心定位是为求职者、招聘方和培训机构提供结构化的面试辅助工具。

项目基于以下技术栈构建:
- 后端框架:Spring Boot 4.0 + Java 21
- AI能力:Spring AI(接入阿里云 DashScope API)
- 数据存储:PostgreSQL + pgvector(向量数据库能力)
- 文件系统:RustFS
- 缓存&消息队列:Redis
核心功能模块
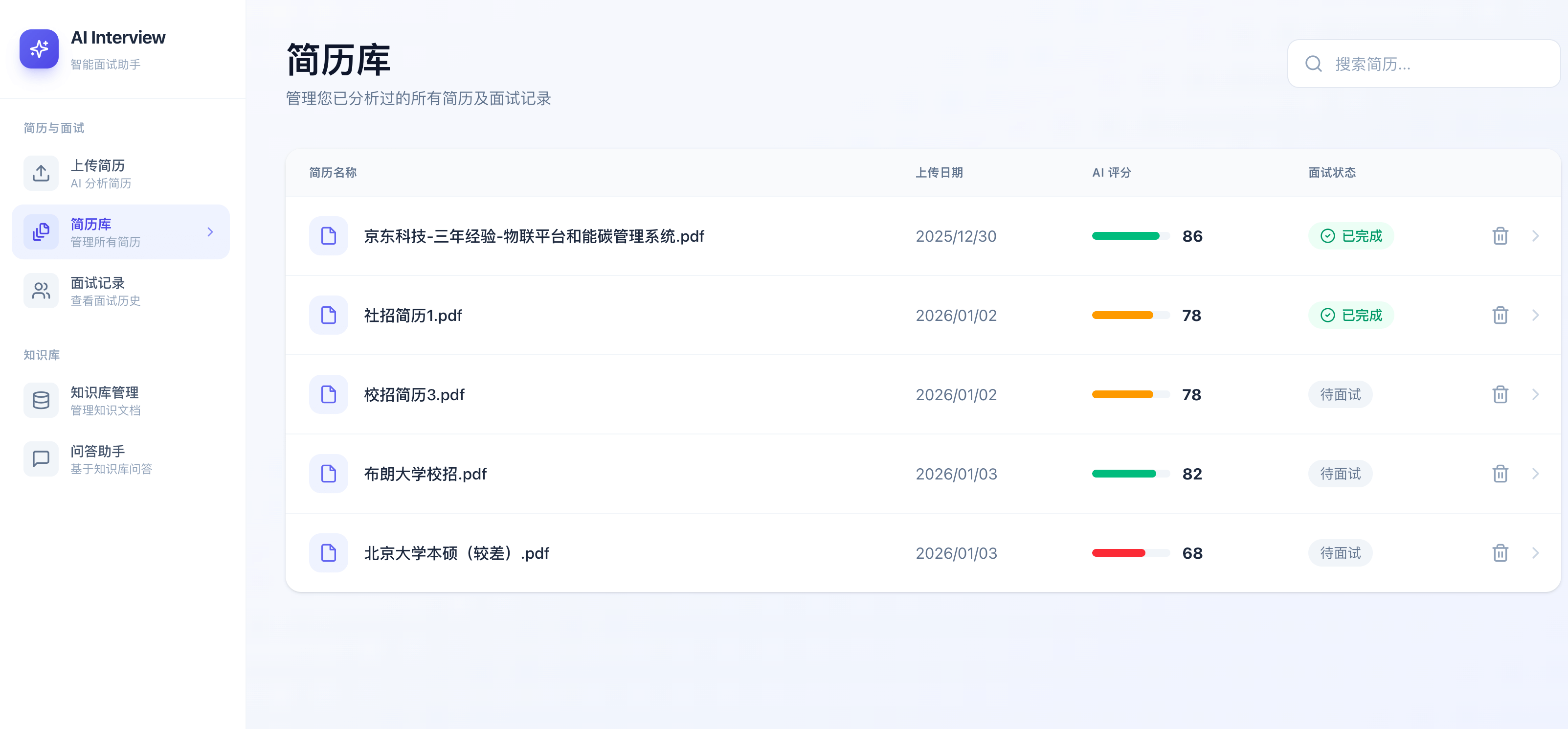
1. 简历智能分析
该模块支持多格式文件上传(PDF、DOCX、DOC、TXT),并提供以下能力:
- 异步处理机制:上传后实时显示分析进度,避免长时间等待
- 自动重试机制:对失败的分析任务自动重试,提升成功率
- 去重逻辑:系统内置简历去重,防止重复分析
- 报告导出:生成结构化 PDF 分析报告,包含职业建议和能力评估
2. AI 模拟面试
基于上传的简历,系统能够:
- 生成个性化面试问题:根据简历内容和岗位特征定制问题集合
- 实时问答交互:支持多轮对话,保持上下文连贯性
- 多维度评分:从技术能力、沟通表达、逻辑思维等多个维度量化评估面试表现
- 可视化呈现:雷达图展示多维评分结果,直观反映优劣势
- 历史追踪:记录面试历史,支持纵向对比和进度统计
- 报告导出:生成完整的面试总结报告
3. 知识库 RAG 检索问答
这是项目的创新点,将 RAG(检索增强生成)技术应用到面试知识积累中:
- 多格式文档支持:PDF、DOCX、DOC、TXT、Markdown 均可上传
- 自动分块与向量化:文档上传后自动进行内容分块,异步调用向量化接口存储到 pgvector
- RAG 检索:用户提问时,系统从知识库检索相关内容,结合 LLM 生成更准确的回答
- 流式响应:采用 SSE(Server-Sent Events)技术,实现流式输出,提升用户体验
- 知识库统计:可视化展示知识库规模、文档数量等信息
应用场景
| 用户群体 | 主要应用场景 |
| 求职者 | 上传简历获取专业分析建议,通过 AI 模拟面试练习,积累答题技巧;利用知识库进行岗位相关知识补充 |
| HR/招聘人员 | 批量导入候选人简历进行快速筛选,通过自动分析和评分降低初筛成本,提高效率 |
| 培训机构 | 为学员提供完整的面试培训服务,管理行业知识库资源,追踪学员进度 |
| 开发学习者 | 作为学习项目理解 Spring AI、向量数据库、RAG 等前沿技术的实际应用 |
安装与部署
环境依赖
- JDK 21+
- PostgreSQL 12+(需安装 pgvector 扩展用于向量存储)
- Redis 6.0+
- 阿里云 DashScope API Key(用于大模型和向量化服务)
部署步骤(简述)
- 克隆仓库:
git clone https://github.com/Snailclimb/interview-guide.git - 配置数据库和 Redis 连接信息到
application.yml - 配置阿里云 DashScope API Key
- 运行数据库初始化脚本
- 启动 Spring Boot 应用
配置管理要点
1. API 配置
- DashScope API Key:用于调用文本生成、向量化等能力,需在环境变量或配置文件中设置
- 速率限制:在配置中设置 API 调用频率,避免超额
2. 数据库配置
- pgvector 扩展:初次部署需手动执行
CREATE EXTENSION IF NOT EXISTS vector;启用向量功能 - 连接池参数:根据并发规模调整 HikariCP 连接池大小
3. Redis 配置
- Stream Consumer:配置异步任务消费者,确保简历分析、向量化等长时间操作不阻塞主线程
- 缓存策略:简历分析结果、知识库元数据等可配置过期时间
常见问题排查
Q: 简历分析失败或无响应
A: 按以下顺序排查:
- 验证 DashScope API Key 是否正确配置,账户余额是否充足
- 检查 Redis 连接状态和 Stream Consumer 是否正常运行
- 查看后端日志中的错误堆栈,确认是 API 调用失败还是本地处理异常
- 确认文件格式是否标准,某些损坏的 PDF 可能无法解析
Q: 知识库问答没有返回结果
A:
- 确认知识库文档向量化状态为 COMPLETED(可在数据库或管理界面查看)
- 验证 pgvector 扩展是否正确安装:连接 PostgreSQL 执行
\dx命令查看扩展列表 - 检查相似度搜索阈值是否设置过高,导致无法匹配到相关文档
- 若向量化卡顿,检查 Redis Queue 是否有堆积任务
Q: PDF 报告导出失败
A:
- 确认 iText 依赖版本正确(pom.xml 中检查版本号)
- 检查服务器字体文件是否存在(默认路径通常为 `/usr/share/fonts` 或项目内的字体目录)
- 查看临时文件目录权限是否允许写入
对标项目参考
市面上有一些相似的解决方案,各有侧重:
| 项目/产品 | 核心特点 | 适配场景 | 学习成本 |
| Interview Guide | 三合一(简历分析+模拟面试+知识库 RAG) | 全链路面试准备 | 低(技术栈现代化) |
| LocalAI/Ollama | 本地大模型部署 | 离线场景、隐私优先 | 中等(需配置本地模型) |
| LangChain 示例项目 | 通用 RAG 框架和示例 | 开发学习、自定义集成 | 高(需深度定制) |
技术亮点分析
- 现代 Java 栈:采用 Java 21 和 Spring Boot 4.0,可以利用虚拟线程、模式匹配等新特性,代码更简洁
- Spring AI 集成:无需直接调用 API,通过 Spring 生态简化 AI 集成,降低开发复杂度
- 向量数据库应用:pgvector 的使用使得本地部署 RAG 系统成为可能,无需依赖云服务
- 异步处理架构:通过 Redis Stream 和异步消费,大文件处理不会阻塞前端请求
- 流式响应设计:SSE 流式输出提供更好的用户体验,适合长文本生成场景
适合学习的原因
- 功能完整度:涵盖文件处理、向量化、LLM 调用、数据库设计等多个技术面,是了解 AI 应用架构的好教材
- 代码质量:由资深开发者维护,代码规范性通常较好
- 实用性强:不是 demo 性质,而是可直接落地的项目,学到的知识易于迁移到其他场景
- 社区活跃:GitHub 项目通常有 Issue 讨论和更新维护
总结
Interview Guide 作为一个开源项目,它解决了面试准备中的真实痛点——求职者需要结构化的自我评估,招聘方需要高效的候选人筛选。从产品层面,它做到了功能完整且聚焦;从技术层面,它展示了如何用现代的 Java 生态和 AI 能力构建实用系统。
无论你是想深入学习 Spring AI、RAG 技术的开发者,还是寻找有实战价值的简历项目的候选人,或者是需要快速部署面试辅助工具的团队,这个项目都值得关注。建议先通过 GitHub 浏览代码和 Issue 了解当前状态,再根据自己的需求决定是否部署或贡献代码。
如果你有体验过这个项目或发现其他类似的开源面试工具,欢迎在评论区分享。