最近这半年,各大模型厂商密集发布新版本,从OpenAI、Anthropic到国内的GLM、Qwen,新模型层出不穷。
问题随之而来:这些模型到底处于什么水平?性能、成本、推理速度如何权衡?
如果你也有过这样的困惑,比如GLM 4.7发布后不知道该如何评估?
那么这篇文章会帮你梳理5个主流的模型评测榜单,让你能更系统地了解各模型的实际能力。
LMSys Arena
简介:由加州大学伯克利分校LMSys团队运营的模型对标平台。
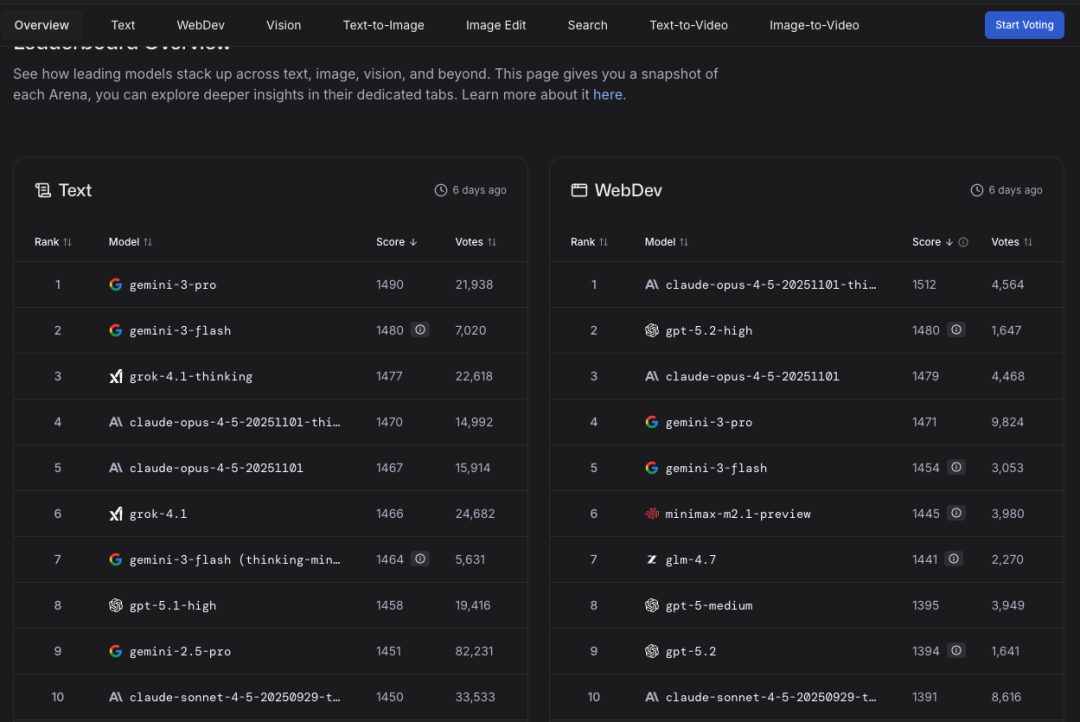
采用"人类对战评测"机制,邀请真实用户对两个模型的回答进行盲评对比。
功能特色:
- 核心机制:基于Elo评分系统排序,更接近真实使用体验而非纯学术指标
- 覆盖范围广:不仅有通用文本榜单,还分设Text、WebDev、Vision、Text-to-Image、Search、Text-to-Video等6个子榜单
- 实时更新:持续收集用户投票数据,排名动态调整
- 适合场景:产品选型、UX对比、开发者工具评估
Artificial Analysis
简介:独立的AI测评与分析公司,专注于模型性能、成本效率的客观评估,为企业和开发者提供选型决策支持。
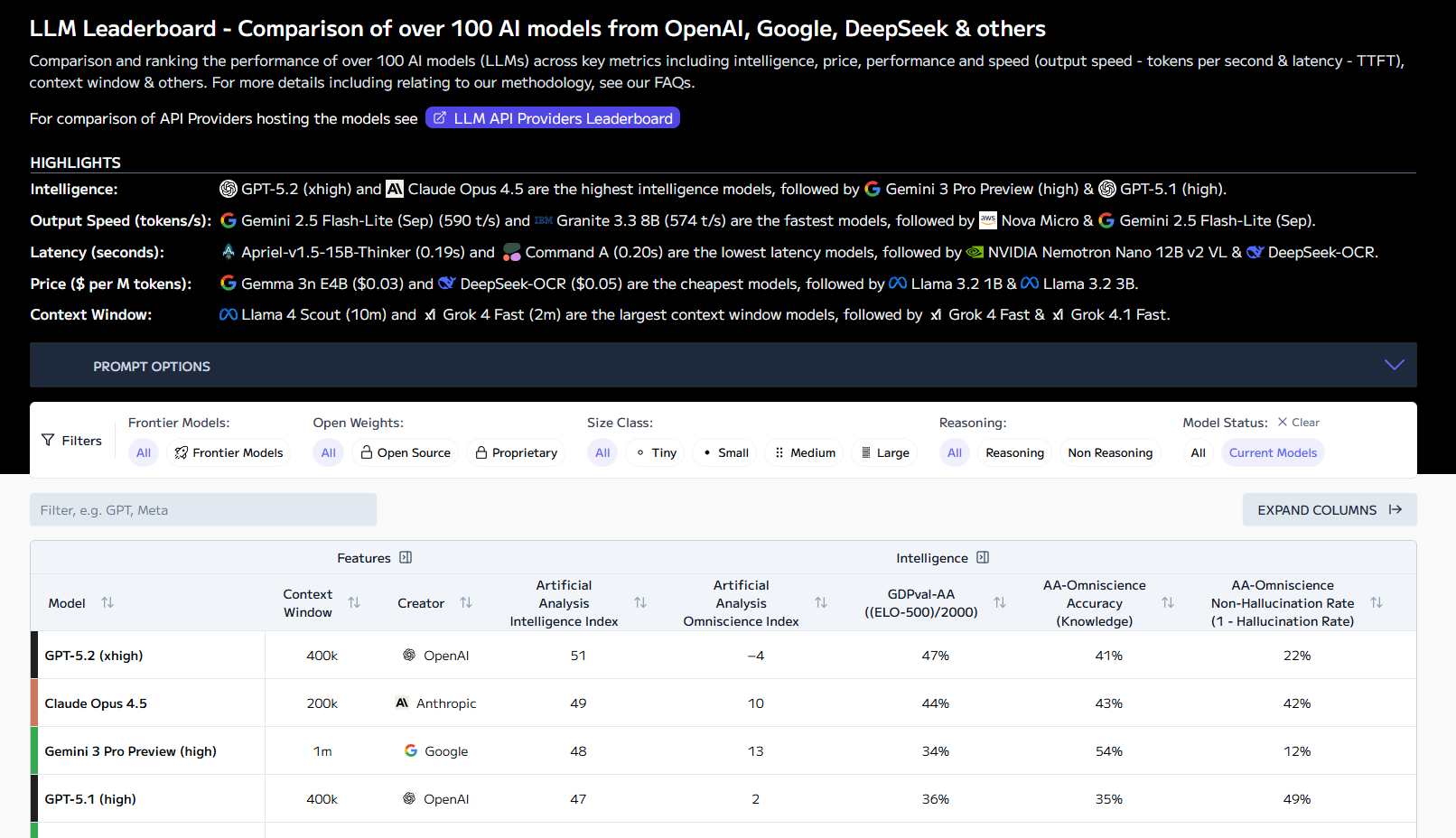
综合排行(Models Leaderboard):按“智能、价格、推理速度、上下文长度”等多维度给上百个模型打分,可以看到每个模型在不同能力和成本上的折中。
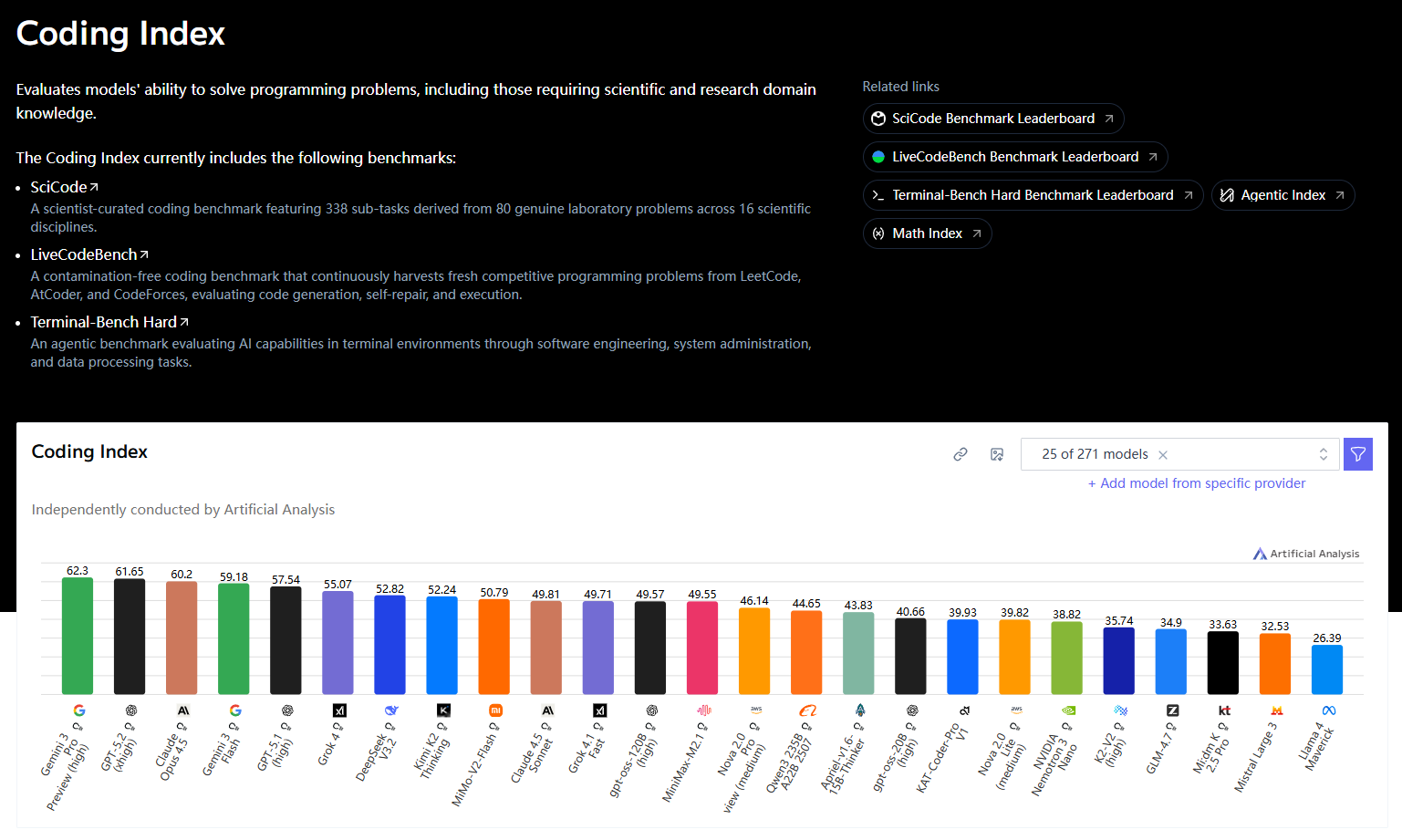
编码领域榜(Coding capabilities):单独抓出“代码能力”相关基准(如代码生成、修复、竞赛题等),比较各模型在编程任务上的表现,更偏工程与生产力导向。
功能特色:
- 综合排行:按"智能程度、价格、推理速度、上下文长度"等多维度对百余个模型评分,展示能力与成本的折中关系
- 编码专项榜:单独抓取代码生成、代码修复、竞赛题等编程能力基准,面向工程与生产力场景
- 量化对标:提供详细的性能-成本矩阵,便于ROI计算
- 适合场景:企业采购决策、API选型、开发工具评估
榜单地址:
综合排行:https://artificialanalysis.ai/leaderboards/models
编码领域榜:https://artificialanalysis.ai/models/capabilities/coding
SuperCLUE
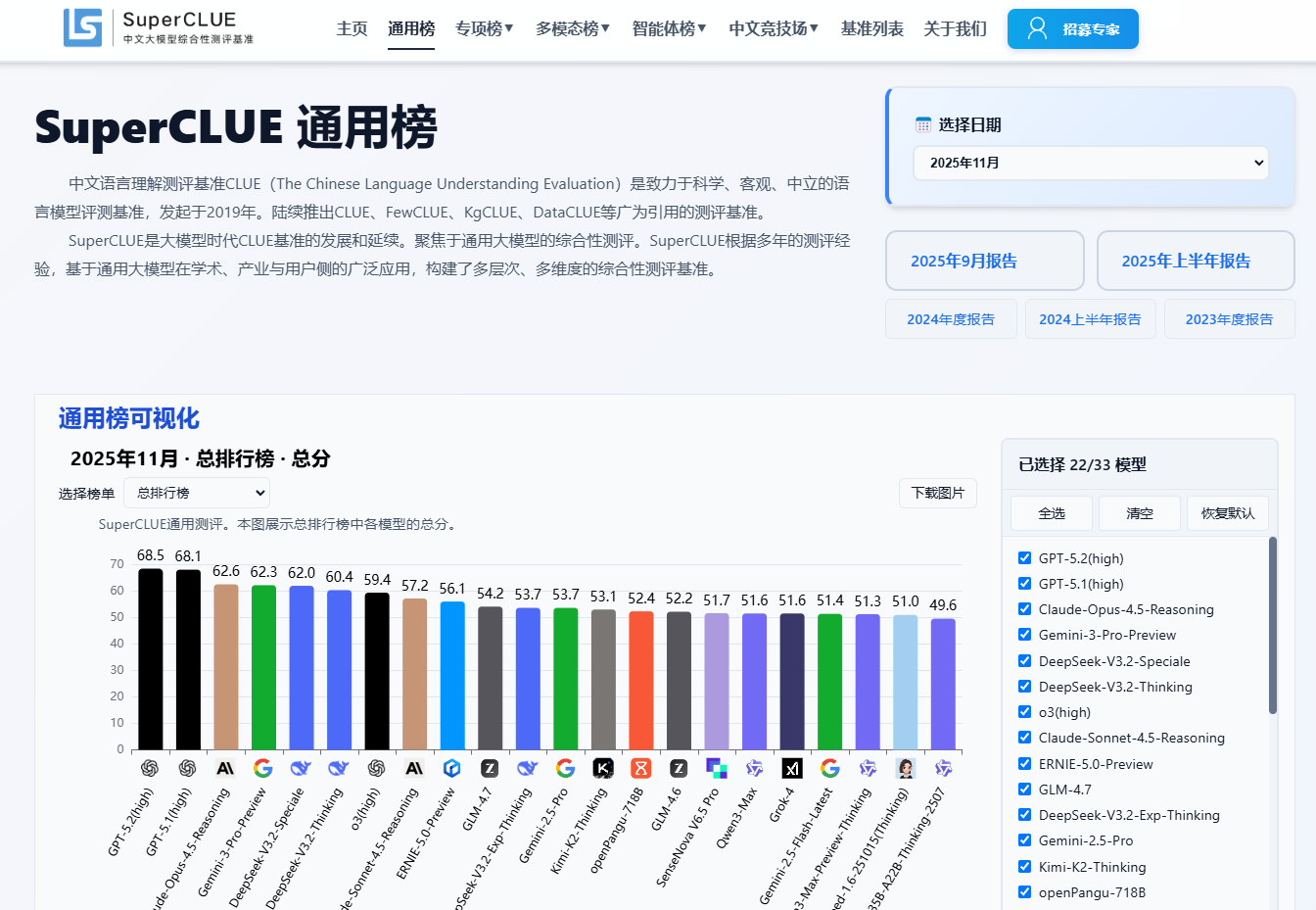
简介:国内首个面向"中文通用大模型"的权威测评体系,重点评估模型在中文任务上的整体表现,以及与国际先进模型、人类水平的差距。
功能特色:
- 中文导向:基准任务全部针对中文场景设计,包含多轮开放问答、客观题、匿名对战等维度
- 通用榜与专项榜:分别评估整体能力和软件工程(SWE)、长文本等特定领域表现
- 月度更新:持续跟踪国内外模型进展
- 适合场景:中文应用产品选型、国内模型进展追踪
榜单地址:
通用榜:https://www.superclueai.com/generalpage
专项榜单:https://www.superclueai.com/benchmarkselection?category=specialized
软件工程榜:https://www.superclueai.com/specificpage?category=specialized&name=SuperCLUE-SWE%E3%80%8C%E8%BD%AF%E4%BB%B6%E5%B7%A5%E7%A8%8B%E3%80%8D&folder=SWE
llm-stats
简介:聚合型榜单平台,将各大模型在多个公开基准上的表现集中展示,支持快速横向对比。
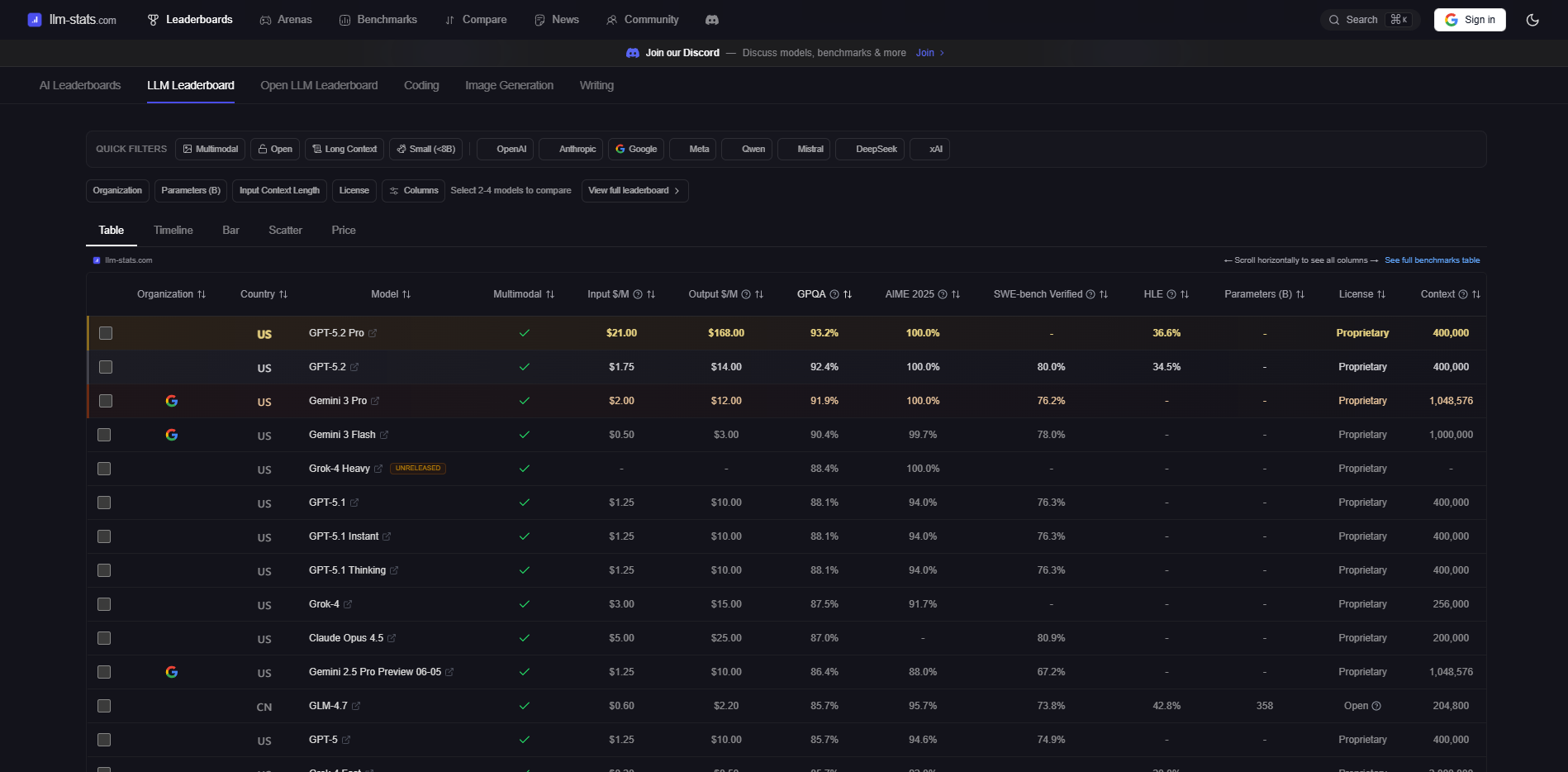
功能特色:
- 信息密度高:一页面展示多个模型在多个基准上的表现(MMLU、HumanEval、MT-Bench等)
- 元信息完整:同步显示价格、上下文长度、发布时间等关键参数
- 多模型对比:支持自选多个模型进行并排查看
- 适合场景:快速筛选、矩阵式对标
使用建议
这4个榜单各有侧重,选择使用需要根据你的具体需求:
| 适用场景 | 推荐榜单 |
| 想看真实用户体验对比 | LMSys Arena |
| 需要评估成本-性能比 | Artificial Analysis |
| 评估中文模型水平 | SuperCLUE |
| 快速浏览多模型全景 | llm-stats |
写在最后
需要强调的是,大模型榜单只能作为参考,不应作为唯一决策依据。
一些模型在榜单排名靠前,但实际应用中的表现可能存在折扣——这源于评测基准与真实业务场景的偏差。
同时,同一模型在不同任务上的表现差异明显,编程能力强不代表创意写作能力强。
最可靠的方式仍然是:基于你的业务场景和数据,进行小规模的自主测评,以实际使用体验为最终判断标准。
榜单可以帮你快速缩小候选范围,但最后一公里还是要自己走。