前几天 OpenAI 官方发布了 GPT-5.6 模型,但由于美国政府限制,我们暂时还用不了。不过,Hermes Agent 同时上线了一个很有意思的功能——MoA(Mixture of Agents,多模型混合):既然单个最强模型有访问门槛,那就让多个模型一起干,然后由一个最强的来做最终决策。

官方基准测试跑下来,这个组合比单独跑 Opus 4.8 还高 8%,比 GPT 5.5 高 11%。
MoA 到底是什么
简单说,MoA 是 Hermes Agent 里的一个"虚拟模型提供商"。你配置好一个预设之后,它会在 Hermes 的模型选择器里以一个普通模型的身份出现——选它就行,跟选 Claude、GPT 一样。
但它背后干的事不一样。每次你发消息的时候,Hermes 会:
- 先把你的话丢给配置里的"参考模型",让它们各自分析一遍
- 把参考模型的分析结果汇总,附在你的消息后面
- 再交给"聚合模型"做最终回复——这个聚合模型才是真正写回复、调工具的那个
如果你有多个模型(比如 GPT 写代码强,MiMo 和 DeepSeek 写文章好),以前需要频繁切换模型或用不同 profile 执行任务,比较麻烦。现在 MoA 就是一个总调度,自动分配不同模型执行不同任务。
为什么要用 MoA
有两个场景特别适合:
第一,复杂任务需要多视角的时候。有些问题你问一个模型,它可能从某个角度切入就停了。MoA 让两三个模型先各自思考一遍,聚合模型拿到的上下文更丰富,输出质量明显提升。
第二,想"蹭"顶级模型能力但又不确定单用哪个最好的时候。MoA 默认预设用的是 gpt-5.5 和 deepseek-v4-pro 做参考,claude-opus-4.8 做聚合。三个顶级模型叠在一起,效果比单独挑一个要稳。
官方 HermesBench 测试数据
| 模型 | 得分 |
|---|---|
| MoA(opus-4.8 + gpt-5.5 参考) | 0.8202 |
| claude-opus-4.8 单独跑 | 0.7607 |
| gpt-5.5 单独跑 | 0.7412 |
比最强的单模型高了 6 个百分点,不是简单"两个模型平均一下",是真有加成。
配置方法
方式一:命令行
运行 hermes moa configure 命令,会交互式地引导你配置默认预设:
第一次跳出的是 reference_models(参考模型) 选择列表:
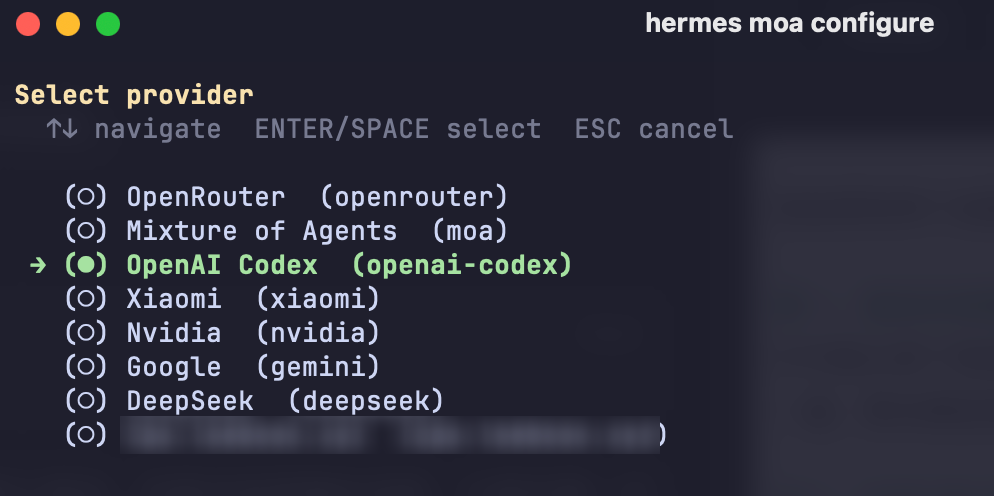
选择模型后回车,询问是否添加其他参考模型,点击 Add another 继续选择:
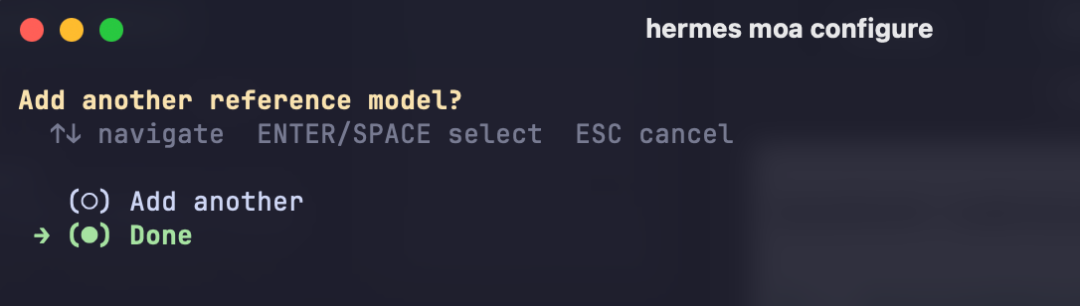
所有参考模型添加完成后选择 Done,然后选择 aggregator(聚合模型):
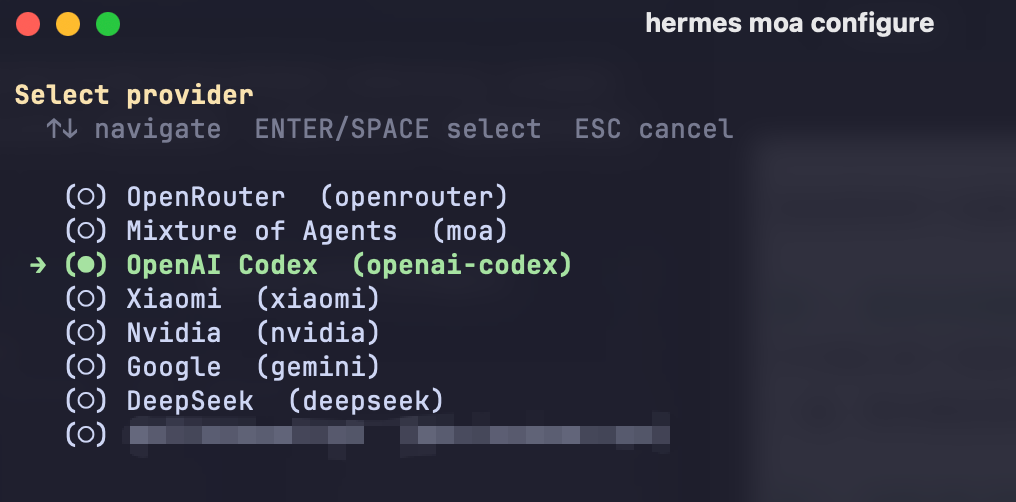
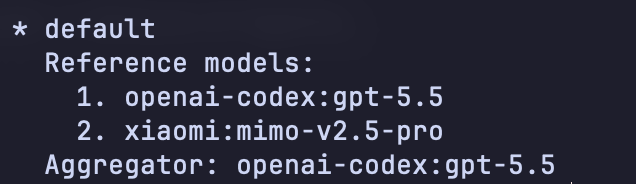
设置完成后运行 hermes moa list 查看已有预设,如果显示"多个 Reference Models + 一个 Aggregator"表示配置正确:
方式二:直接编辑 config.yaml
在 ~/.hermes/config.yaml(或对应 profile 的配置文件)里加上:
moa:
default_preset: default
presets:
default:
reference_models:
- provider: openai-codex
model: gpt-5.5
- provider: openrouter
model: deepseek/deepseek-v4-pro
aggregator:
provider: openai-codex
model: openai-codex/gpt-5.5
reference_temperature: 0.6
aggregator_temperature: 0.4
max_tokens: 4096
enabled: true参数说明:
- reference_models:参考模型列表,可放多个,会并行调用。支持不同 provider 混搭。
- aggregator:聚合模型,最终写回复的那个。它才是真正带工具调用能力的"主模型"。
- reference_temperature:参考模型温度,稍高让它们给更多样视角。
- aggregator_temperature:聚合模型温度,低一点让输出更确定。
- enabled:设为 false 可临时关闭某个预设的参考模型扇出。
你可以创建多个预设,比如一个日常用的 default,一个专门做代码审查的 review,各自配不同的模型组合。
使用方式
配置好后,使用很简单。
切到 MoA 模型:
运行 /model default --provider moa,或者在 TUI / Desktop 的模型选择器里直接选,MoA 预设会出现在"Mixture of Agents"分类下:
切完之后正常使用就行,发的每条消息都会走 MoA 流程:
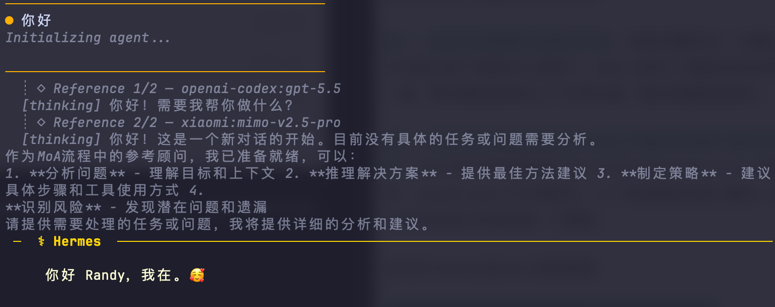
一次性使用 /moa 命令:
如果不想切模型,只想偶尔用一次,直接运行 /moa 帮我分析一下这个项目的架构该怎么重构。这条命令会临时切到默认 MoA 预设跑一次,跑完自动切回之前的模型,不会影响日常模型选择。
几个值得注意的点
Prompt 缓存不会被破坏。MoA 设计上保证了主对话的缓存前缀是稳定的。参考模型接收的是精简版对话(去掉了系统提示词和工具调用记录),聚合模型拿到的参考结果追加在最新一条消息末尾——跟普通对话每轮新增一条消息的缓存行为完全一样。不用担心 MoA 会让 token 费用暴涨。
某个参考模型挂了不影响整体。如果其中一个参考模型的 API key 失效或网络超时,Hermes 会把失败信息附在上下文里,继续用其他返回了结果的参考模型跑。不会因为一个模型挂掉就整个崩溃。
不支持递归嵌套。聚合模型不能是另一个 MoA 预设,这个限制是故意的,防止递归调用。
会多花一些 token。每轮消息会多出几次参考模型的调用。如果 API 预算比较紧,可以在不重要的对话里关掉 MoA,关键任务再开。
总结
MoA 的本质是用"多花一点 token"换"输出质量的实质性提升"。对大多数日常对话来说,单模型就够了。但如果你经常处理复杂任务——写长文、做架构设计、处理多步骤自动化流程——MoA 带来的多视角分析确实能帮你少踩坑。
缺点也很明确:token 消耗会多很多,时间也会慢不少。就看你怎么做取舍了。