在使用 Agent 操控浏览器执行任务时,经常遇到一些问题:Agent 打开的浏览器没有 Cookie 记录,每次都需要重新登录;被网页反爬机制拦截;被识别为 Bot;拿不到动态页面数据等。这些问题导致很多自动化工作流无法顺利完成。
BrowserAct 是一个面向 Agent 工具的浏览器自动化 CLI,填补了 Agent 在真实环境中执行任务的"执行层"空缺。
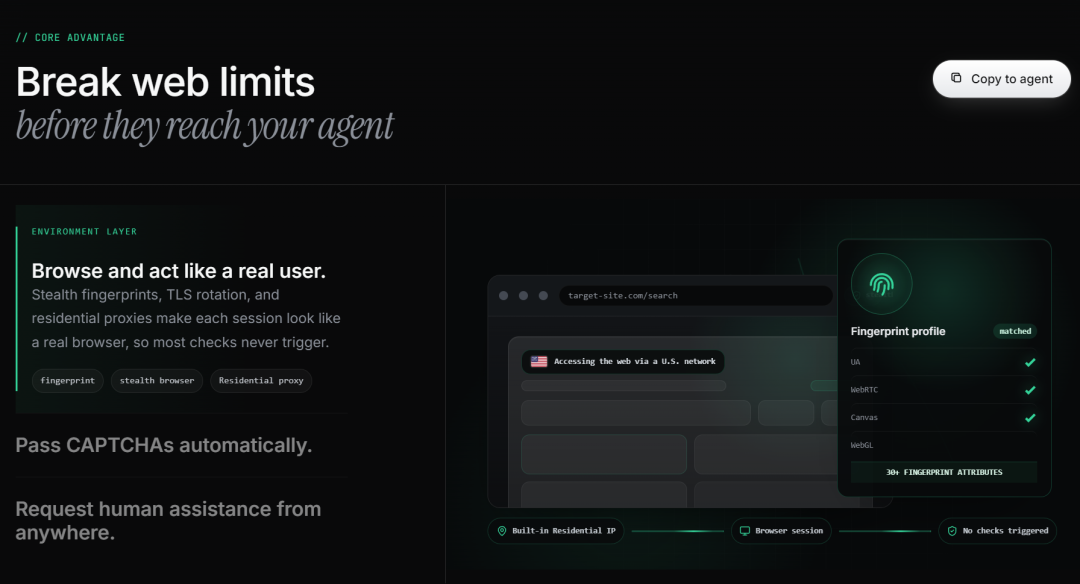
1. 反检测环境
Agent 控制浏览器通常有两种方式:纯视觉方式(较慢)和命令行方式(容易被反爬机制拦截)。BrowserAct 同时支持两种方式,既支持命令行控制,又能绕过部分反爬机制。

2. 三层递进结构
- 环境层:隐蔽指纹伪装、TLS 轮换、切换代理
- 执行层:全自动破解验证码,隐蔽提取功能,抓取受保护的页面
- 人工层:远程协助生成实时链接,用户可从任意设备接管操作,完成任务后无缝续接
当遇到需要人工介入的操作(如验证码或扫码)时,BrowserAct 不会直接中断任务,而是生成一个远程协作链接。人类通过链接完成协作后,Agent 继续执行任务。在等待人工协助的过程中,Agent 会先去执行其他可以执行的工作。
3. 多账号隔离
BrowserAct 通过 Stealth Browser + Static Proxy,将每个账号放在相对独立的浏览器环境中运行。每个浏览器可以绑定独立的登录状态和网络环境,分别执行对应账号下的任务。这适合电商店铺运营和社交媒体自动化运营等需要同时管理多个账号的场景。

4. 并发不串线
每个任务都有独立的浏览器工作区,账号之间互不污染。
5. Skill-Forge 扩展技能
Skill-Forge 是独立于 browser-act 执行入口之外的扩展能力。用户只需描述想要的数据或操作目标,Skill-Forge 会先探索目标网站,分析页面流程、可用 API 和数据字段,生成可部署的 Skill 包。之后 Agent 可以直接复用这套 Skill,沿着已验证过的路径稳定执行批量任务,无需每次重新理解网站。
实际应用场景
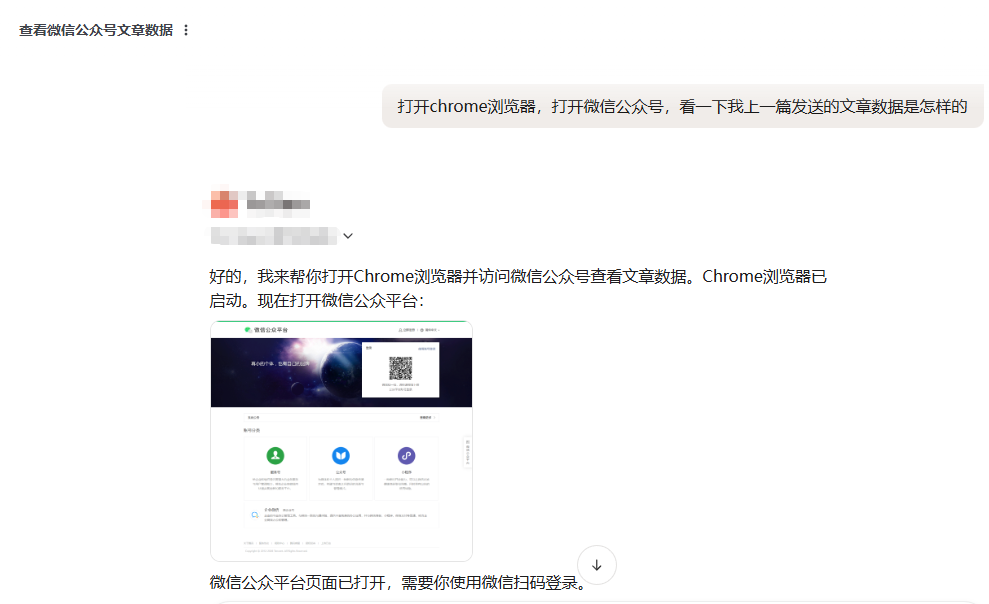
场景一:复用已有登录状态
许多 Agent 打开的是全新浏览器环境,进入公众号后台等需要登录的网站时需要重新扫码。BrowserAct 可以在已有的真实浏览器会话中继续执行任务,复用当前已登录的状态,无需重新登录。

对比其他 Agent,它们打开的是没有登录状态的浏览器:
场景二:跳过网站反爬
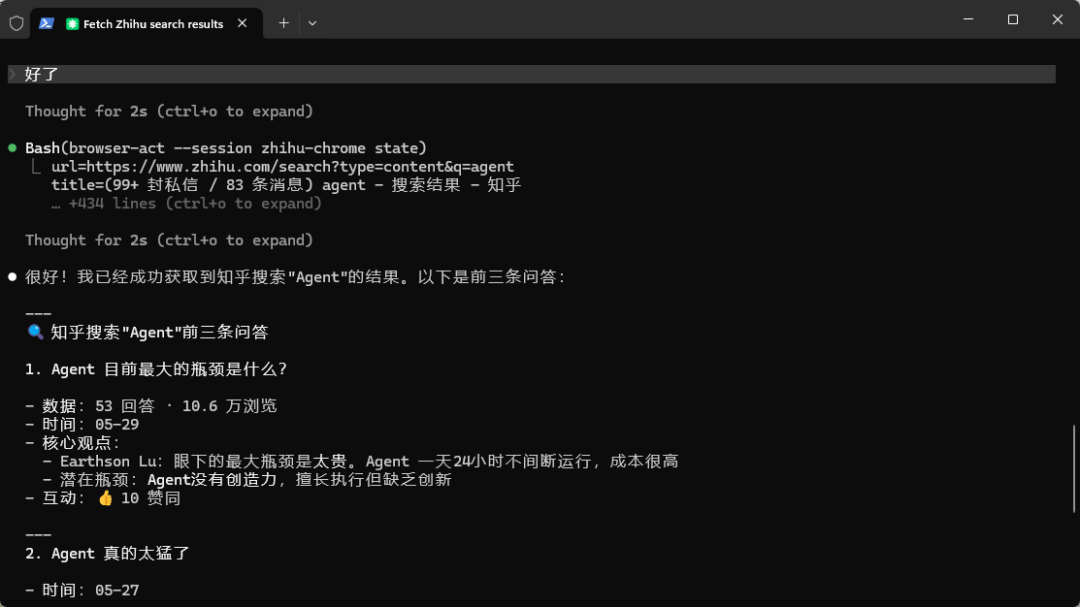
对于反爬机制严格的网站(如小红书),BrowserAct 可以正常进入页面并提取信息,包括首页推荐内容等。
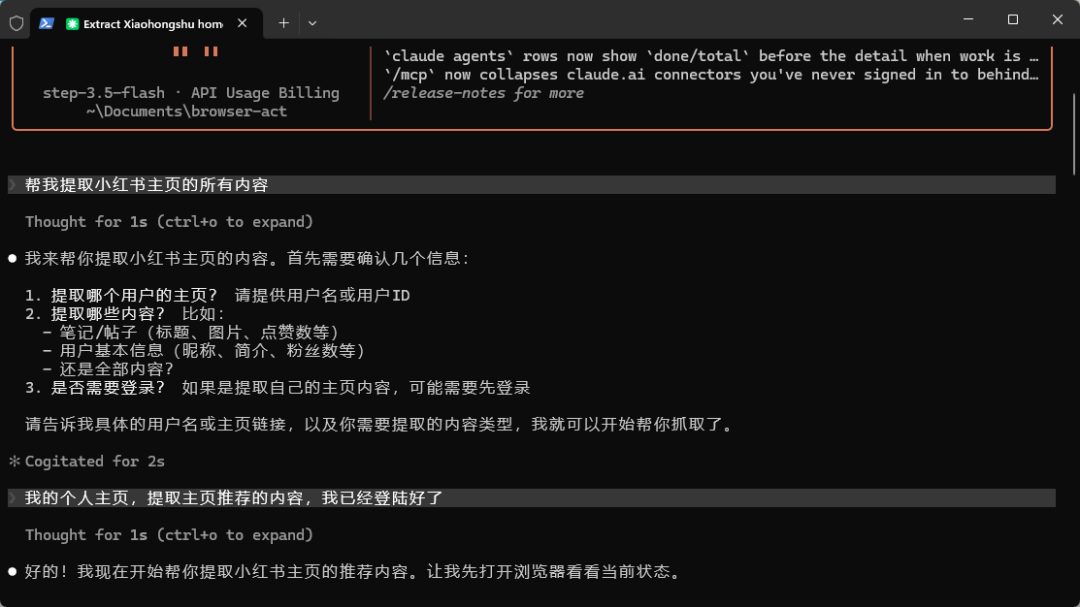
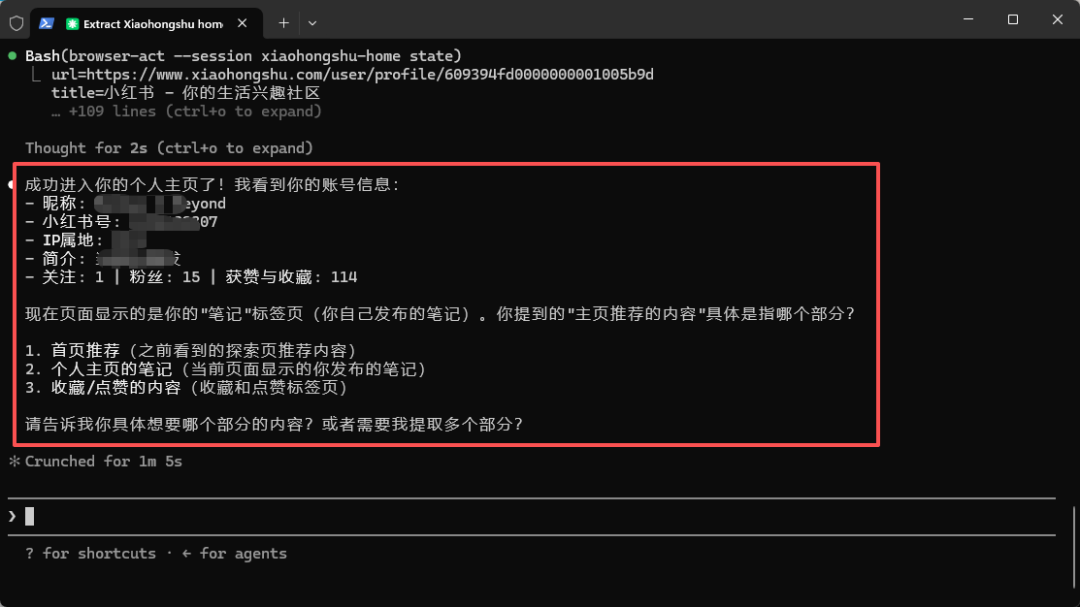

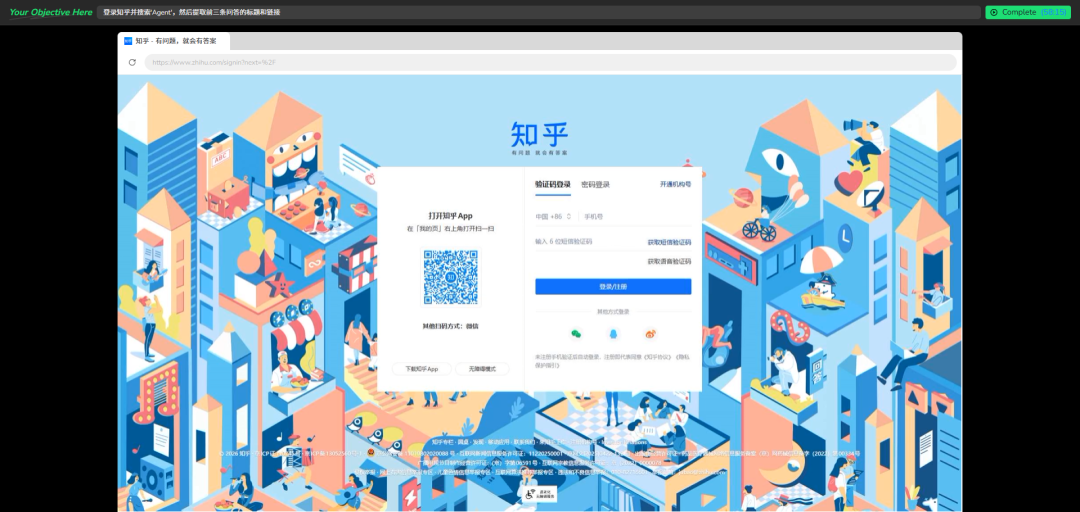
场景三:人机接力
对于需要登录后才能查看的内容(如知乎),BrowserAct 会生成一个隐私浏览器模式的链接。用户通过该链接在任何设备上完成登录验证后,Agent 即可继续执行任务。
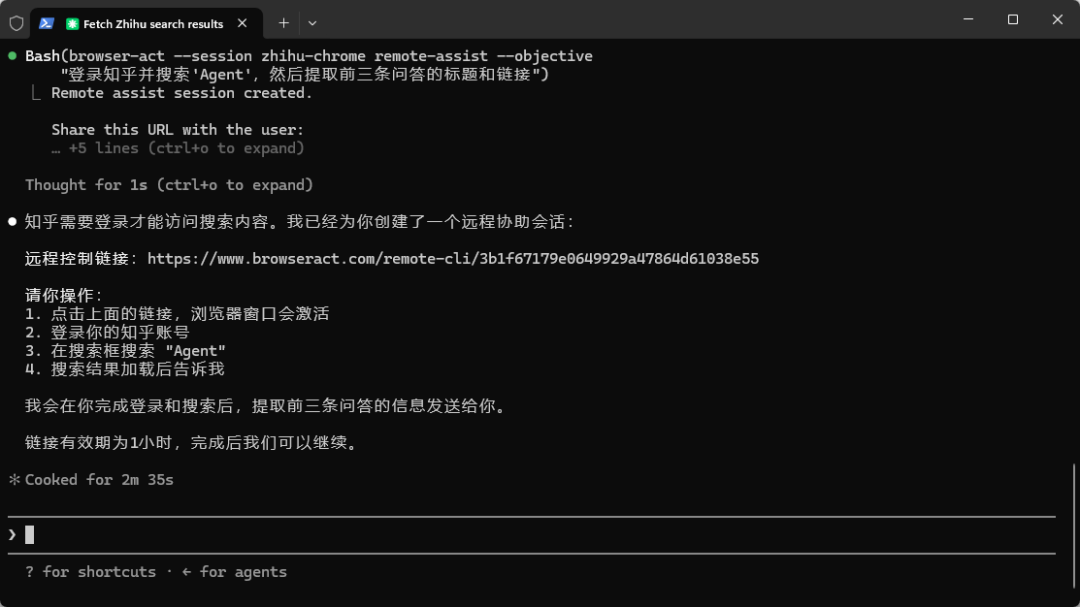
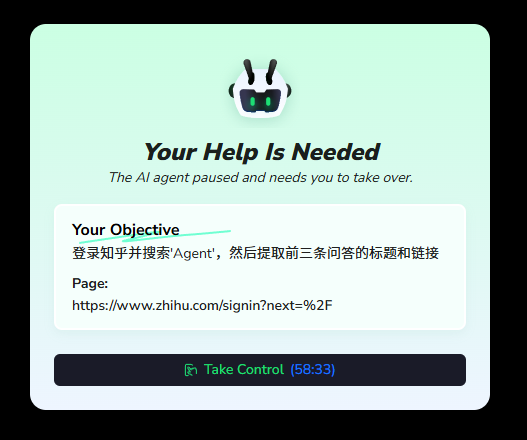
安装方法
将 BrowserAct 的 GitHub 页面地址发送给 Agent,Agent 即可自动开始安装:
https://github.com/browser-act/skills/tree/main/browser-act

总结
Agent 落地真正卡住的往往不是模型参数或提示词优化,而是真实环境中的执行能力。BrowserAct 的出现填补了这部分空缺,通过人机接力作为工作流设计模式,Agent 可以先暂停等待用户完成关键操作后再继续执行,更贴近真实用户的工作方式。
官方网站:www.browseract.ai