最近Cursor 发布了 Composer 2.5,官方定性为"迄今为止最强大的模型"。
发布推文 1182 万次浏览,马斯克本人转发点赞。这次除了模型更新本身,Cursor 还顺带宣布了一件更大的事。

先看数据
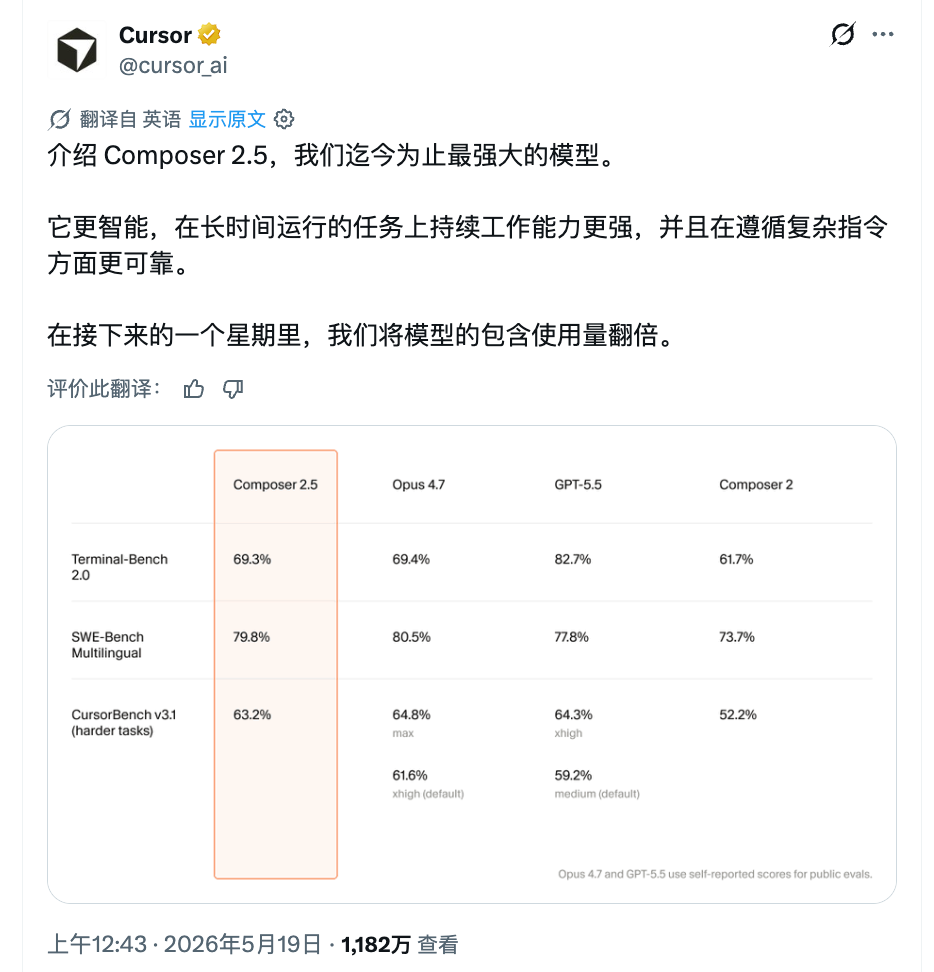
三项主要基准测试里,Composer 2.5 的成绩是:
- Terminal-Bench 2.0:69.3%,与 Opus 4.7 的 69.4% 几乎打平
- SWE-Bench Multilingual:79.8%,超过 GPT-5.5 的 77.8%,略低于 Opus 4.7 的 80.5%
- CursorBench v3.1(高难度任务):63.2%,Opus 4.7 默认配置是 61.6%,GPT-5.5 默认是 59.2%
CursorBench 是 Cursor 自己设计的测试集,更贴近真实编程场景,这个维度上 Composer 2.5 超过了同等默认配置的 Opus 4.7 和 GPT-5.5。
这几项成绩本身放在前沿模型里不算最顶,但下面这张图才是重点。
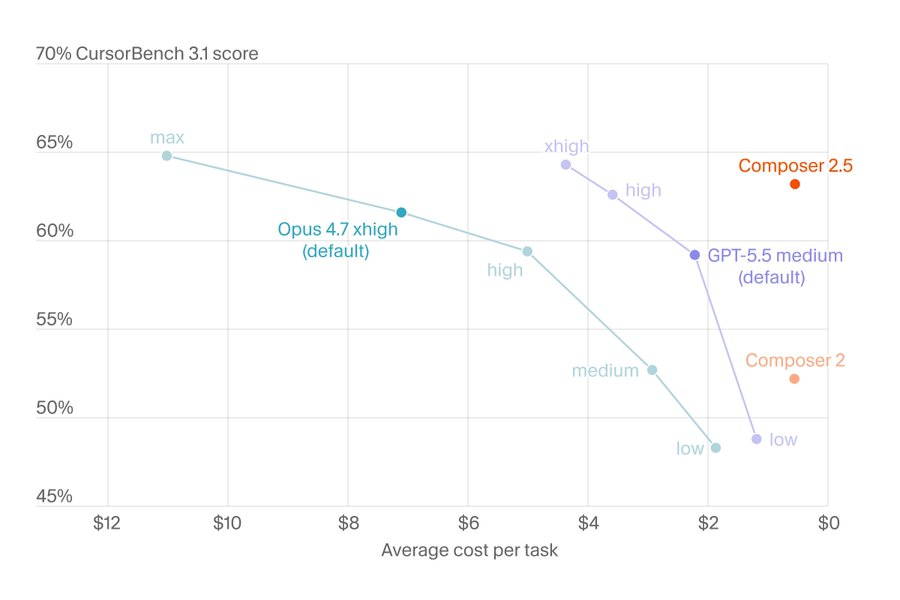
成本对比散点图里,Opus 4.7 达到类似 CursorBench 得分需要每任务约 7-10 美元,GPT-5.5 需要 1-2 美元,Composer 2.5 站在右上角,得分相近,成本接近于零。官方说法是"比同等能力的模型高效 10 倍"。
定价是每百万输入 token 0.50 美元,输出 2.50 美元。发布首周还直接把模型的包含用量翻倍。
这次 Cursor 把底座写进了公告
上次 Composer 2 发布时,社区因为抓包发现底层用的是 Kimi K2.5 而引发了一场透明度争议。Cursor 产品负责人 Lee Robinson 后来公开道歉,表示"下一个模型会把基座写清楚"。
这次他们做到了。
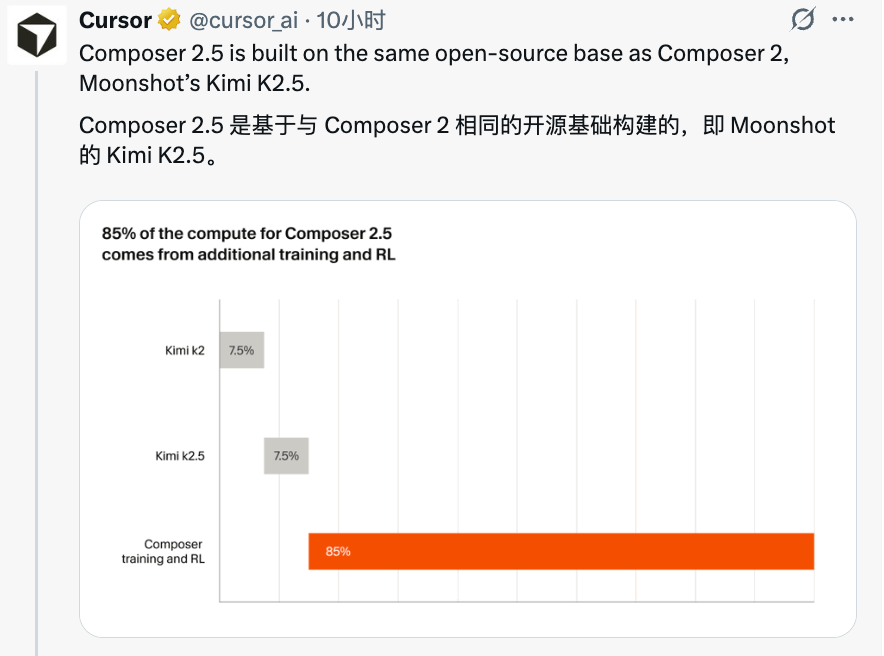
Cursor 在发布推文里直接写道:Composer 2.5 基于与 Composer 2 相同的开源基础构建,即 Moonshot 的 Kimi K2.5。
但这句话只说了一半,另一半更关键。
官方随即附上了一张计算资源分布图,图里写着:Composer 2.5 有 85% 的计算资源来自 Cursor 自己的额外训练和强化学习,Kimi K2 和 Kimi K2.5 各只贡献了 7.5%。
换句话说,Kimi K2.5 只是起点,Cursor 在这个基础上砸进去的才是主体。这和"拿开源模型做微调"是两种不同量级的工作。
他们到底做了什么

Cursor 在技术细节上没有藏着掖着,公布了三个核心方向:
- 扩大训练规模,生成了比上一代复杂得多的强化学习环境
- 引入文本反馈机制,在强化学习过程中,通过在跨越数十万个 token 的 rollout 中精确分配积分,让模型学得更快
- 合成数据量是上一代的 25 倍,并且发现模型能自己找到解析缓存、反编译字节码等复杂变通方案
优化器层面,他们用了分片 Muon 结合双网格 HSDP,在万亿参数规模上每个优化器步骤只需 0.2 秒。这些是模型公司才会搞的工程细节,不是普通应用层面的事情。
官方引用了一句评价:"Composer 2.5 exceptionally intelligent and up to 10x more efficient than similarly capable models."
然后是那个更大的消息
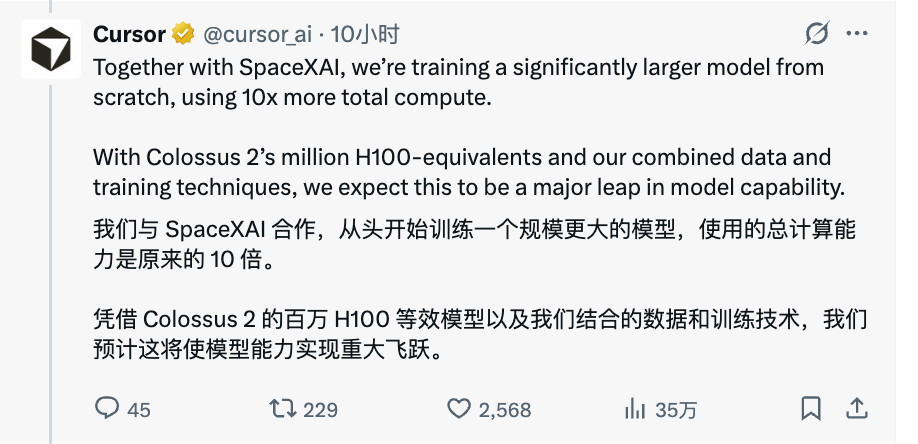
Cursor 宣布,正在与 SpaceXAI 合作,从头训练一个规模大得多的全新模型,总算力是现在的 10 倍。他们会用 Colossus 2 的百万 H100 等效算力,结合双方的数据积累和训练技术。
四月份 SpaceXAI 与 Cursor 宣布算力合作的时候,许多人认为这只是租用算力的商业协议。现在来看,那只是开始,双方已经在联合从零训练一个新模型。
马斯克本人在推文下评论了一句:"试用一下!(部分训练于 Colossus 2)"。简短,但背书效应不小。
Cursor CEO Michael Truell 在自己账号上写:Composer 2.5 相较于 Composer 2 是一个显著的进步,而这只是他们与 SpaceXAI 合作的开端,希望很快能推出更多改进。
值得注意的几个信号
Cursor 这条路越走越清晰:用自有数据和强化学习训练专属编程模型,而不是永远依赖第三方 API。从 Composer 1 到 1.5 再到 2,再到现在的 2.5,每一代都在把自研能力往前推一步。
现在他们有了 SpaceXAI 的算力支持,下一代模型的规模和能力上限会直接被拉高。Colossus 2 的百万张 H100 不是一个可以忽视的数字。
Kimi K2.5 这次被作为公开起点写进发布公告,本身也是一个变化。开源生态和商业产品的协作关系越来越像一种标准路线,谁借助谁做了什么,最终能不能形成自己的差异化,才是真正的竞争维度。
成本效率这件事也值得单独说一句。在性能相近的情况下,成本差距 10 倍不是小事。对于自动化编程、Agent 任务这类需要高频调用的场景,成本直接决定了什么东西能规模化,什么不能。
苏米注:Cursor 的这条路——基于开源底座 + 大量自有数据 RL 训练 + 专属算力合作——正在成为 AI 编程工具的标准路线。对于开发者来说,Composer 2.5 的成本优势(10 倍效率提升)意味着 Agent 编程可以真正规模化了。值得关注的是他们与 SpaceXAI 的合作,百万级 H100 算力训练出来的下一代模型,可能会重新定义 AI 编程的上限。
当然,Cursor 的下一代模型还在训练中,承诺和落地之间有多大距离,等上线了再说。但今天这个起点,看起来比预期的要结实一些。