站在2026年初回望,2025年无疑是开源大语言模型(LLM)发展史上的分水岭。
在这一年中,以DeepSeek、Qwen和Moonshot AI为代表的国内力量扭转了全球开源格局,打破了"开源模型性能逊于闭源"的固有认知。

从Llama 3独占鳌头的2024年,到百花齐放的2025年,这个转变背后的技术突破和生态演进值得系统梳理。
本文基于对2025年关键开源模型的观察和分析,梳理了十大代表性模型及其技术特征,旨在帮助决策者和开发者理解当前开源LLM的真实能力边界和应用适配。
一、DeepSeek R1:性能与成本效益的突破口
产品名称:DeepSeek R1
简介:2025年1月发布,DeepSeek R1是一个671B参数的稠密模型,专注于逻辑推理、数学问题求解和代码生成。其核心设计理念是在"中等"参数规模下,通过高质量数据、创新训练方法和算法优化实现极致性能。
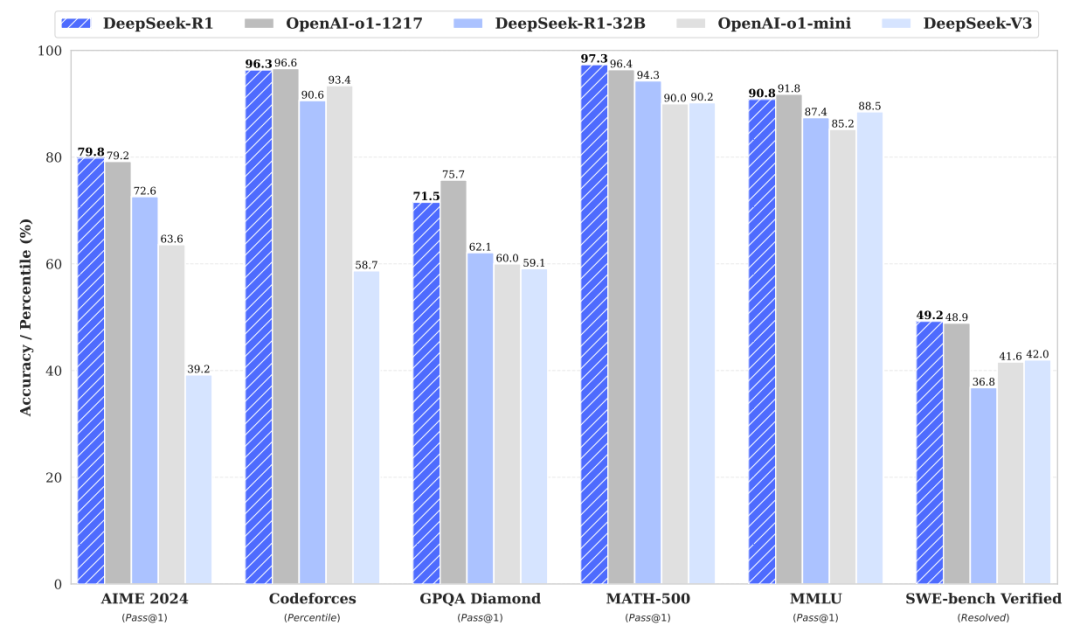
功能特色/特点:
- 推理能力突破:在数学问题求解上准确率超过90%,在MMLU-Pro、AIME 2024等权威基准上与GPT-4o、Claude 3.5 Sonnet相当或超越。
- 开放协议:采用MIT许可证,允许任何个人、学术机构或商业机构免费使用、修改和分发,无附加条件。
- 成本优势:训练成本估算仅为同等性能闭源模型的数十分之一,API定价极具竞争力。
- 技术架构:在混合精度框架和MoE(混合专家)架构上的优化,实现了高性能与低成本的结合。
- 实际应用支持:得到英伟达、亚马逊、微软等国际科技巨头接入,验证了其生产级别可用性。
二、Qwen3系列:全面均衡的综合型选手
产品名称:Qwen3(阿里巴巴通义千问)
简介:2025年4月发布,Qwen3是Qwen系列的最新迭代。旗舰模型Qwen3-235B-A22B采用MoE架构,预训练数据规模达18万亿token,结合监督微调(SFT)和多阶段强化学习(RL),实现了知识、编码、数学等多维度的能力均衡。
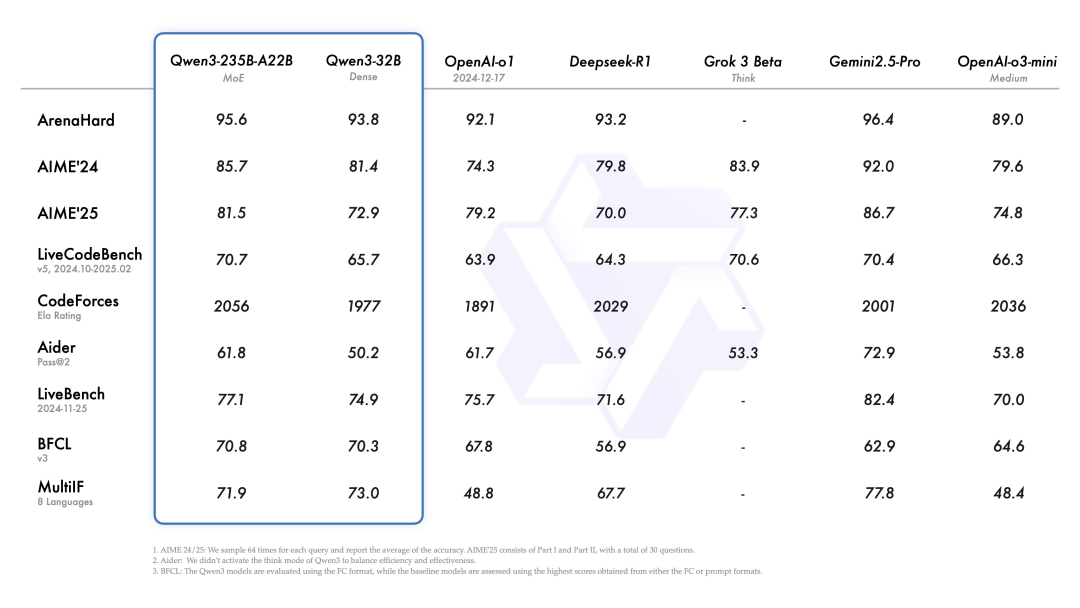
功能特色/特点:
- 数据规模飞跃:预训练数据从Qwen2的7万亿token增至18万亿token,为模型知识广度和深度提供坚实基础。
- 架构创新:采用MoE架构结合复杂的多阶段训练策略,在代码、数学、长文本处理等任务上表现均衡。
- 模型谱系完善:包含Qwen3-235B-A22B(旗舰)、Qwen3-30B-A3B(小型MoE,激活参数仅为QwQ-32B的10%)、Qwen3-4B等多个规格,覆盖不同应用场景。
- 性能指标:在MMLU、代码生成、数学推理等基准上与DeepSeek-R1、o1、Gemini-2.5-Pro等顶级模型保持竞争力。
- 小模型创新:Qwen3-4B虽然参数较小,但性能已接近Qwen2.5-72B-Instruct,突破了小模型能力天花板。
三、Kimi K2:万亿参数的稀疏探索
产品名称:Kimi K2(月之暗面 Moonshot AI)
简介:2025年7月发布,Kimi K2是全球首个真正意义上达到万亿参数规模的开源模型。采用稀疏MoE架构设计,总参数1万亿,但单次推理仅激活约320亿参数,实现了"规模"与"推理效率"的兼得。
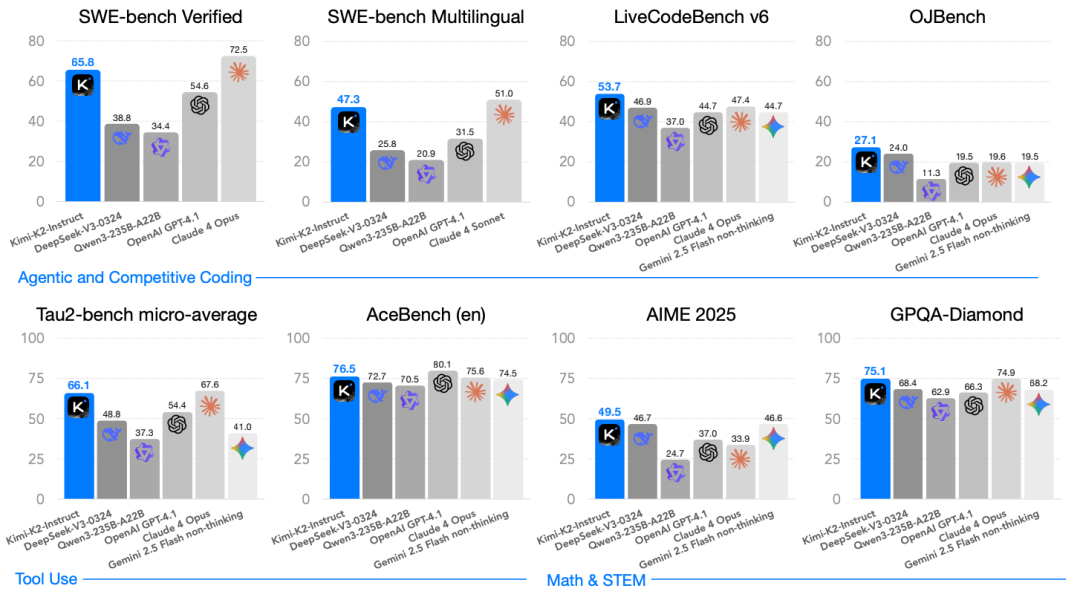
功能特色/特点:
- 参数规模突破:总参数达1万亿,代表了开源模型在规模上的新高度。
- 稀疏MoE设计:单次推理仅激活320亿参数,保持相对高效的推理成本,解决了超大模型难以落地的核心矛盾。
- 训练规模:使用超过15.5万亿token的数据进行预训练,标志行业进入数十万亿token时代。
- 技术创新:自研MuonClip优化器,有效稳定大规模模型的训练过程,提高训练效率和可靠性。
- 应用定位:兼具大规模知识储备与相对经济的推理成本,适配需要深度知识覆盖的复杂任务。
四、Llama 3.1:从领导者到奠基人
产品名称:Llama 3.1(Meta)
简介:作为2024年的开源生态主导者,Llama 3.1在2025年继续迭代。405B参数版本实现多模态能力升级,支持128K tokens的长上下文窗口,在150余个基准测试中展现出与GPT-4、Claude 3.5相当的效能。
功能特色/特点:
- 标准架构:采用标准Transformer架构,设计理念相对保守但久经考验。
- 多模态能力:405B版本支持多模态理解,在数学推理、工具使用等场景对标顶级模型。
- 长上下文支持:128K tokens窗口大小,支持处理长文档和复杂对话。
- 生态基础:作为开源生态的奠基者,积累了广泛的社区支持和工具链。
- 许可证:Llama许可证相比MIT更受限制,但平衡了开放性和商业控制。
五、GLM-4.5:智能体专向的开源方案
产品名称:GLM-4.5(智谱AI)
简介:2025年7月发布,GLM-4.5是智谱AI的旗舰开源大语言模型,专为AI Agent应用设计。通过创新的混合专家(MoE)架构,实现了大规模与实用性的结合。
功能特色/特点:
- Agent设计:模型架构针对自主规划、工具调用和复杂任务执行优化。
- MoE架构:采用混合专家机制,兼顾模型容量与推理效率。
- 社区基础:智谱从早期就坚持开源开放策略,积累了深厚的开发者社区基础。
- 应用场景:适配需要自主决策和工具链集成的Agent应用。
六、MiniMax-M2:紧凑高效的MoE方案
产品名称:MiniMax-M2
简介:MiniMax推出的紧凑、快速且具成本效益的MoE模型。总参数2300亿,活跃参数仅100亿,重新定义了智能体应用的效率边界。
功能特色/特点:
- 参数效率:总参数2300亿,活跃参数100亿,参数激活率极低,推理成本可控。
- 任务适配:在编码和Agent任务中表现突出,同时保持强大的通用智能。
- 成本优势:紧凑的设计使其在边缘设备和资源受限环境中具有部署优势。
- 应用场景:适合需要快速响应和低延迟的Agent和编码助手场景。
七、Qwen2.5系列:稳健迭代的技术基座
产品名称:Qwen2.5(阿里巴巴通义千问)
简介:2024年9月发布,但在2025年继续作为重要的技术基座被广泛应用。包含0.5B至72B的多个规格,针对编程(Coder)和数学(Math)提供专用模型。预训练数据7万亿token,在开源社区积累了广泛认可。
功能特色/特点:
- 规格覆盖完整:从0.5B到72B,覆盖从边缘设备到服务器端的全部场景。
- 专用模型:提供Qwen2.5-Coder和Qwen2.5-Math,针对特定任务的优化。
- 稳健性:经过大规模生产环境验证,社区反馈完整。
- 数据规模:7万亿token预训练数据,标志当时业界的数据规模水平。
八、DeepSeek-V3:通用能力的最后迭代
产品名称:DeepSeek-V3
简介:2024年12月发布,参数量达6710亿,是DeepSeek在R1推理模型发布前的通用模型最终版本。训练耗时约55天,耗资约558万美元,代表了高性价比大规模模型训练的典范。
功能特色/特点:
- 参数规模:671B参数,达到当时通用模型的规模上限。
- 训练效率:14.8万亿tokens数据,55天训练周期,极低的训练成本。
- 性能水平:与GPT-4o、Claude 3.5 Sonnet等顶级闭源模型相当。
- 技术意义:证明了通过优化训练方法和基础设施,可以显著降低大规模模型的训练成本。
九、MiMo-V2-Flash:端侧多模态的实践
产品名称:MiMo-V2-Flash(小米)
简介:2025年12月17日发布,小米的最新大模型方案。融合多种模态信息(视觉、语音等),聚焦于在智能手机等个人设备上实现高效多模态理解和交互。
功能特色/特点:
- 多模态支持:集成视觉、语音等多种模态输入,实现更自然的人机交互。
- 端侧部署:针对手机、IoT设备等消费级硬件优化,支持本地化推理。
- 实时性:设计目标是低延迟、快速响应,满足移动设备交互需求。
- 应用场景:智能助手、拍照理解、语音交互等移动端典型场景。
十、Gemma系列:谷歌的开源回馈
产品名称:Gemma(Google)
简介:谷歌在其顶级闭源模型Gemini系列之外,通过Gemma系列回馈开源社区的轻量级模型方案。设计目标是在消费级硬件上实现可用的模型性能,降低AI技术的使用门槛。
功能特色/特点:
- 轻量化设计:参数规模相对较小,但性能表现超过同等规模的其他开源模型。
- 硬件友好:支持在消费级GPU和边缘设备上部署。
- 开源生态回馈:作为闭源厂商向开源社区的主动贡献,维持与开源社区的关系。
- 应用场景:适配资源受限但需要一定智能水平的应用场景。
全局分析:技术趋势与应用适配
关键技术趋势

MoE架构已成事实标准。从Qwen3、Kimi K2到GLM-4.5、MiniMax-M2,MoE架构在2025年从实验阶段演变为构建超大规模模型的标配方案。通过稀疏激活机制,有效解耦总参数与推理成本,使万亿参数模型从理论走向实践。
数据规模进入数十万亿Token时代。Qwen3的18万亿token和Kimi K2的15.5万亿token标志着行业进入新数量级。竞争焦点不再是数据量堆砌,而是数据清洗质量、多语言配比、高质量代码数据和合成数据应用等精细化操作。
推理优化技术成熟度提升。vLLM、SGLang、TensorRT-LLM等推理框架日趋完善,INT8/INT4量化技术能在性能损失最小的情况下大幅降低显存占用。这使得高性能开源模型在消费级GPU甚至边缘设备上的部署成为可能。
训练效率与成本控制成为竞争要点。DeepSeek R1和V3的低成本训练方案、Moonshot的MuonClip优化器等创新,使得训练SOTA级模型不再是云巨头的专属,更多初创和研究机构获得入场机会。
应用适配建议
性能优先场景:选择DeepSeek R1、Qwen3或Kimi K2。三者在推理、编码、数学等核心任务上性能指标最具竞争力,适配对模型能力有高要求的应用。
成本约束场景:考虑MiniMax-M2或小规格Qwen模型(4B/7B)。这些模型在激活参数或总参数较小的前提下,依然保持可用的性能水平,适配边缘部署和实时性应用。
Agent应用专向:GLM-4.5专为Agent设计,工具调用和自主规划能力经过针对性优化,如果应用涉及复杂的多步推理和工具链集成,该方案具有优势。
端侧多模态交互:MiMo-V2-Flash针对移动设备优化,在手机端实现视觉语音多模态理解是其核心定位。
生态继承与兼容性:如果应用已基于Llama或Qwen生态构建,继续选择该系列新版本可获得最小改造成本。
结语
2025年的开源LLM生态已从追随者变身为创新引领者。
从DeepSeek R1的性能突破到Kimi K2的规模探索,从Qwen3的全面均衡到MiniMax-M2的极致紧凑,这十大模型代表了不同的技术路线和应用定位。
对开发者和决策者而言,不必盲目追求"最强"模型。
正确的选择是:根据实际应用场景、硬件约束、成本预算和性能要求,在上述模型谱系中找到最合适的匹配点。
展望2026年,开源模型与闭源模型的界限将进一步模糊,竞争焦点也将从单纯的性能指标,转向综合拥有成本、数据隐私控制、定制化需求和特定功能的满足。
这种转变,既是技术演进的必然结果,也是AI产业走向成熟和多元化发展的标志。