今天凌晨,Meta 发布了全新的大模型 Muse Spark,已上线到 Meta 旗下的各类产品。
Meta Superintelligence Labs(MSL)负责人 Alexandr Wang 在推特上宣布了这个消息。他说,九个月前团队从零重建了整个 AI 技术栈,新的基础设施、新的架构、新的数据管线,Muse Spark 就是这份工作的产物。
苏米注:去年 Llama 4 发布后遭遇了 Benchmark 作弊风波,Meta 随后对整个 AI 组织做了大幅重组,挖来了 Scale AI 创始人 Alexandr Wang。Muse Spark 是重组之后交出的第一份答卷。
Muse Spark 能做什么
Muse Spark 是一个原生多模态推理模型,支持工具调用、视觉推理链(visual chain of thought)和多 Agent 协同。Meta 把它定位为「个人超级智能」的第一步,面向 Meta 生态内 30 亿 用户。
多模态能力
按 Meta 自己的说法,Muse Spark 从底层就为视觉信息设计,在视觉 STEM 问答、实体识别和空间定位上表现较强。这些能力组合起来可以做一些交互式的事情,比如:
- 把一张照片变成可以在网页上玩的数独游戏
- 给家电故障做动态标注帮你排查问题
健康领域
Meta 跟超过 1000 名医生 合作整理了健康领域的训练数据,让模型的回答更准确、更全面。Muse Spark 可以生成交互式的健康展示,比如分析各种食物的营养成分,或者展示运动时激活了哪些肌肉群。
苏米注:健康是 Meta 这次明确押注的方向。官方演示案例中,有一个是给素食主义者推荐食物,标绿点表示推荐,红点表示不推荐,悬停显示个性化理由和健康评分。
购物模式
Muse Spark 会结合用户在 Instagram、Facebook、Threads 上关注的创作者和品牌偏好,做个性化的购物推荐。
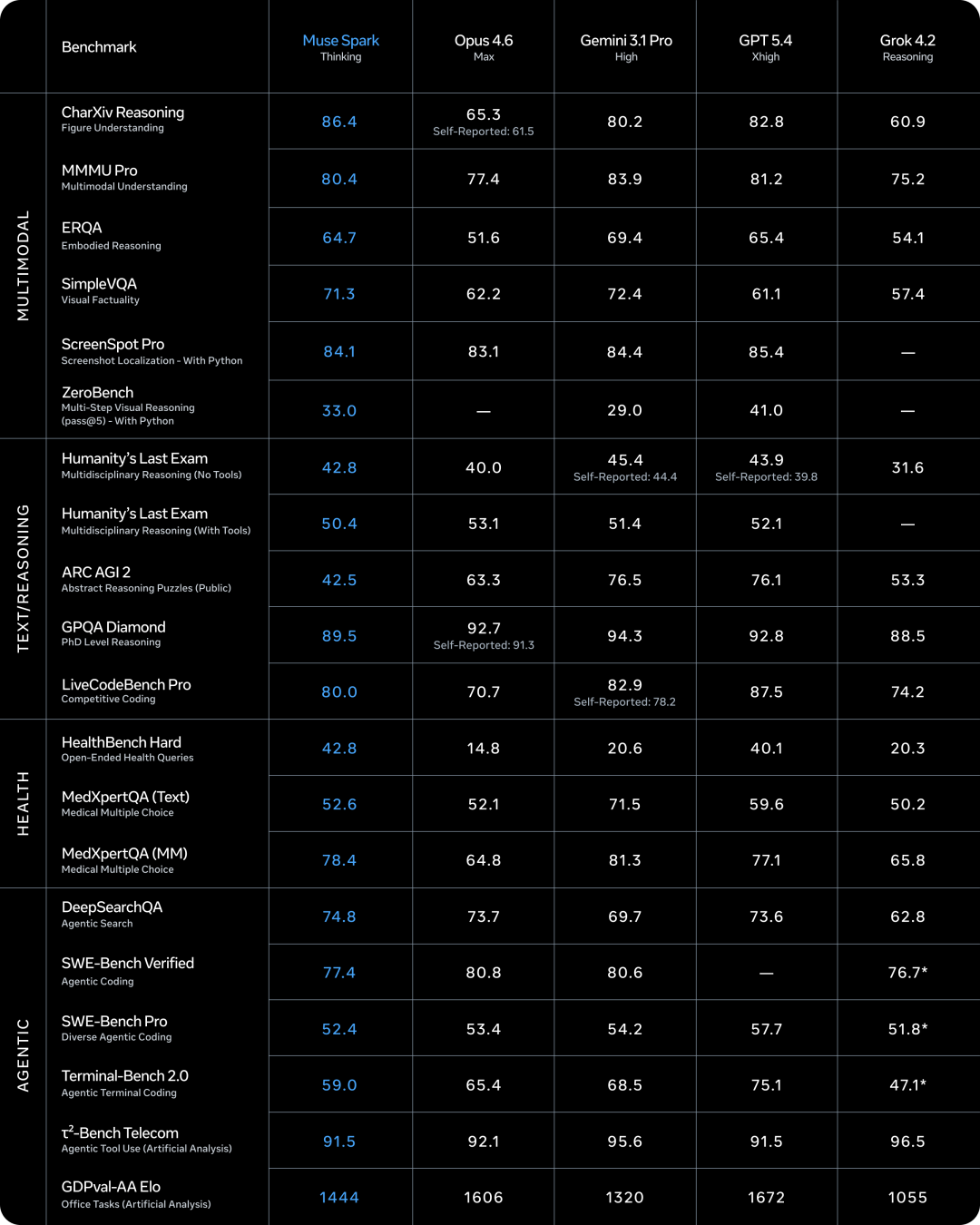
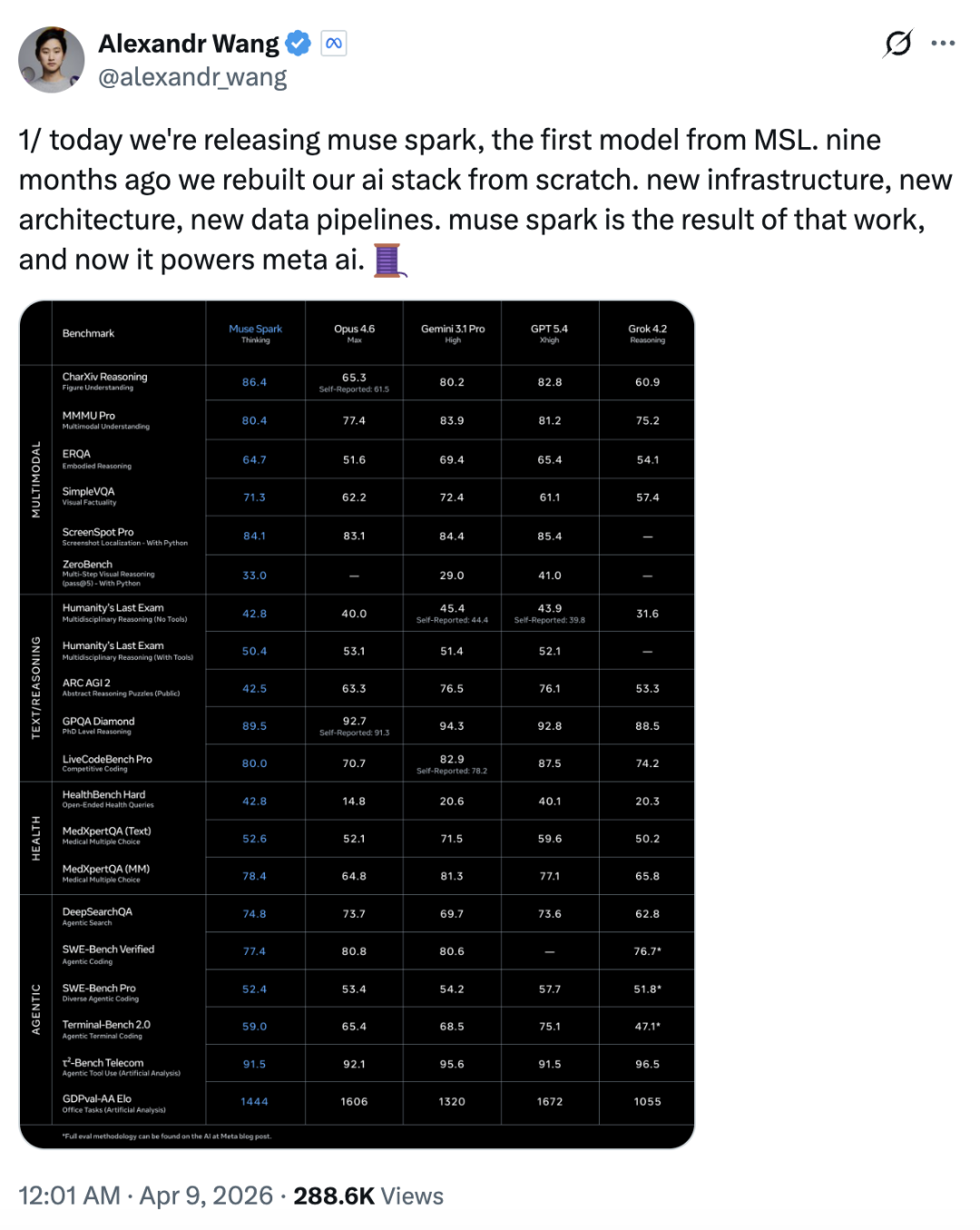
Benchmark 表现
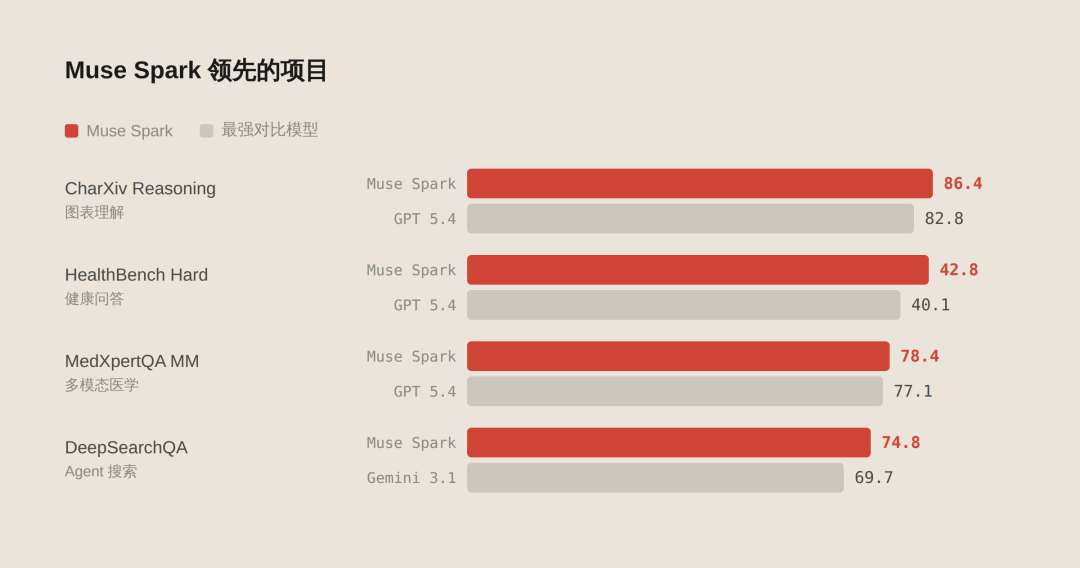
领先的项目
| 评测项目 | Muse Spark | 竞品 | 说明 |
|---|---|---|---|
| CharXiv Reasoning | 86.4 | GPT 5.4: 82.8 | 图表理解,多模态核心能力 |
| HealthBench Hard | 42.8 | GPT 5.4: 40.1 | 开放式健康问答 |
| MedXpertQA MM | 78.4 | GPT 5.4: 77.1 | 多模态医学问答 |
| DeepSearchQA | 74.8 | Gemini 3.1 Pro: 69.7 | Agent 搜索能力 |
图表理解是多模态模型的核心能力之一,这个分数在所有对比模型中最高。
健康问答的成绩跟 Meta 跟上千名医生合作整理数据有直接关系。
明确落后的项目
| 评测项目 | Muse Spark | 竞品 | 差距 |
|---|---|---|---|
| ARC AGI 2 | 42.5 | Gemini 3.1 Pro: 76.5 | 抽象推理,离 AGI 最近的测试 |
| Terminal-Bench 2.0 | 59.0 | GPT 5.4: 75.1 | Agent 终端编程 |
| LiveCodeBench Pro | 80.0 | GPT 5.4: 87.5 | 竞赛级编程评测 |
| SWE-Bench Pro | 52.4 | GPT 5.4: 57.7 | Agent 编程,修复 Bug |
| GDPval-AA Elo | 1444 | GPT 5.4: 1672 | 办公任务综合能力 |
苏米注:ARC AGI 2 的差距非常大,只有 42.5 分,而竞品都在 76 分以上。这个评测被认为是离 AGI 最近的测试之一。
整体看下来,多模态感知和健康领域有竞争力,部分指标领先。编程和 Agent 类任务落后明显,Wang 自己在博客里也承认了这一点,说团队在持续投入。
Meta 的人跟 Axios 说得很直接:Muse Spark 不代表新的 SOTA,但在特定任务上跟前沿模型有竞争力。这个表态比去年 Llama 4 发布时的口径克制了很多。

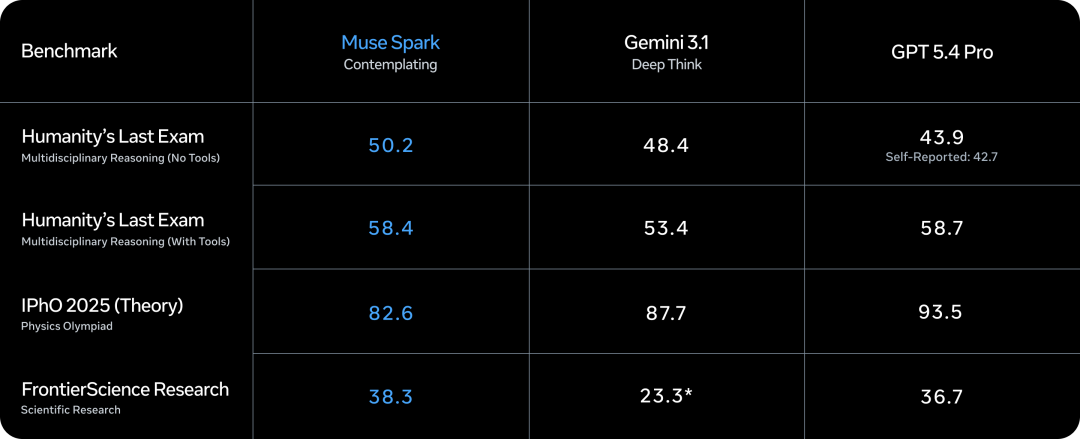
Contemplating 模式
Muse Spark 同时发布了一个叫 Contemplating 的推理模式。做法是让多个 Agent 并行思考同一个问题,再汇总结果,对标 Gemini Deep Think 和 GPT Pro 这类极限推理模式。
| 评测项目 | Muse Spark | 竞品 | 说明 |
|---|---|---|---|
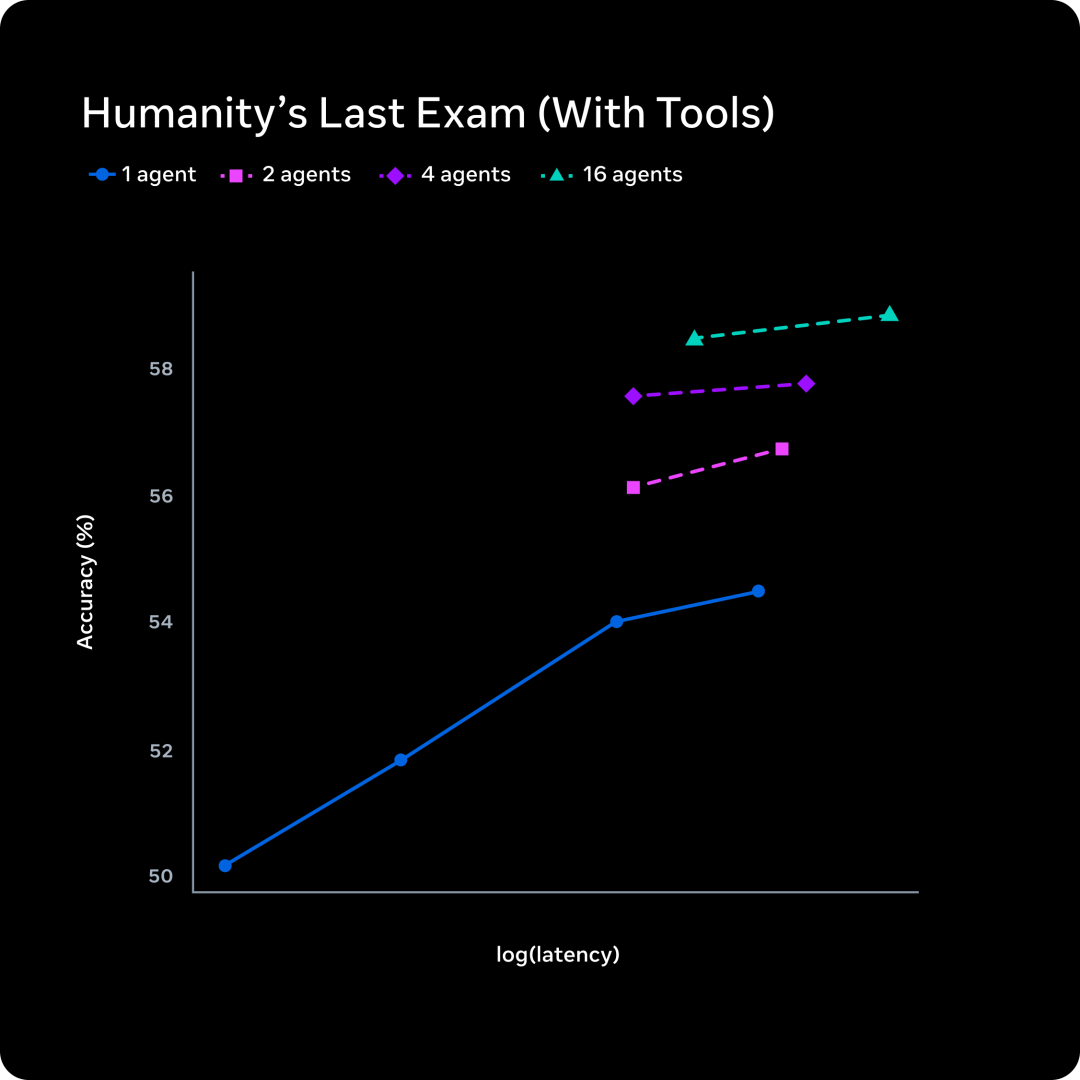
| Humanity's Last Exam | 50.2(无工具) | Gemini Deep Think: 48.4 | 人类最后的考试 |
| Humanity's Last Exam | 58.0(有工具) | - | 工具辅助 |
| FrontierScience Research | 38.3 | GPT 5.4 Pro: 36.7 | 前沿科学研究 |
| IPhO 2025 Theory | 82.6 | GPT 5.4 Pro: 93.5 | 物理奥赛理论题 |
在科学研究类任务上表现不错。但物理还有差距。
Contemplating 模式目前在 meta.ai 上逐步灰度发布。
技术栈重建
Meta 在官方博客里披露了 Muse Spark 在三个维度上的 Scaling 表现。
预训练效率
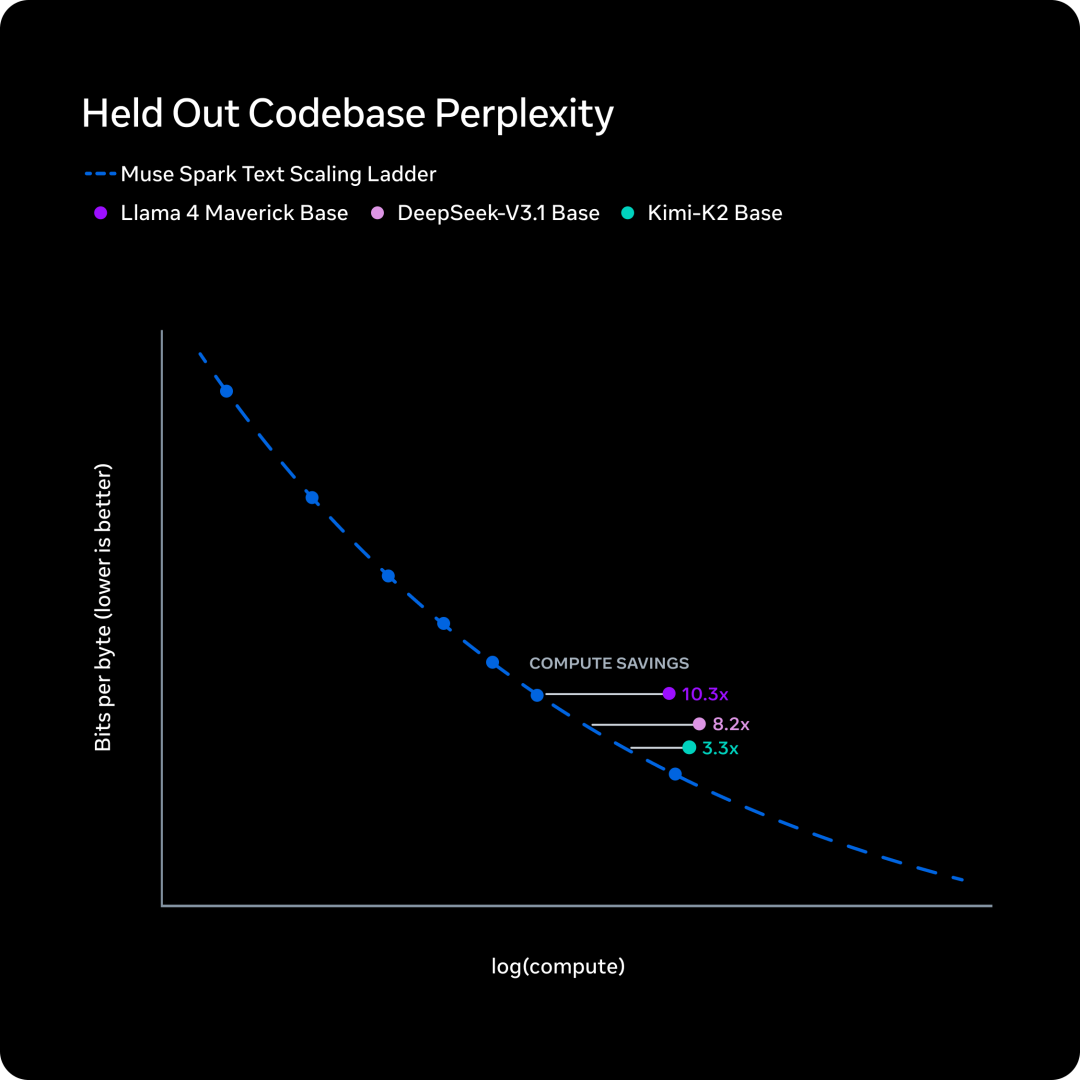
过去九个月 MSL 重建了预训练技术栈,包括模型架构、优化器和数据处理。他们在一系列小模型上拟合了 Scaling Law,然后对比达到相同能力水平需要多少计算量。
苏米注:同样的能力水平,Muse Spark 需要的计算量比 Llama 4 Maverick 低了一个数量级以上。官方说这个效率也优于他们能获取到的其他可比基座模型。
强化学习
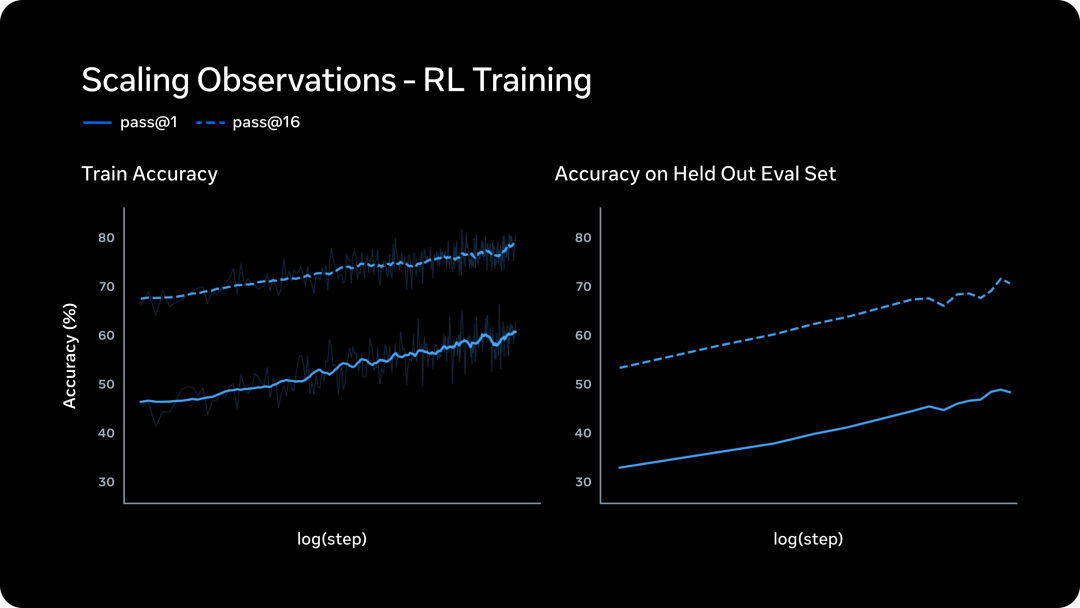
大规模 RL 训练一直以不稳定著称。Meta 说他们新的 RL 技术栈做到了稳定、可预测的能力增长。
左图是训练集上的表现随 RL 步数增长,呈 log-linear 趋势。pass@1 和 pass@16 同步上升,Meta 认为这说明可靠性和推理多样性没有冲突。右图是评估集上的准确率增长,说明 RL 的收益能泛化到没见过的任务。
如果这些曲线的稳定性在更大规模上还能保持,这本身就是一个有价值的工程成果。
推理时计算
Meta 用了两个方法来提升推理阶段的效率:
- 思考时间惩罚:训练时对思考长度施加惩罚,迫使模型用更少的 Token 完成推理。Meta 观察到一个有趣的现象:模型先是想得越来越长,然后在惩罚作用下出现了「思维压缩」(thought compression),用更短的推理链解决同样的问题。
- 多 Agent 并行推理:传统做法是让一个模型想更久,延迟线性增加。Muse Spark 的做法是让多个 Agent 并行思考再汇总,在相近的延迟下获得更好的表现。
Contemplating 模式就是基于这个思路。
安全评估与「评估感知」
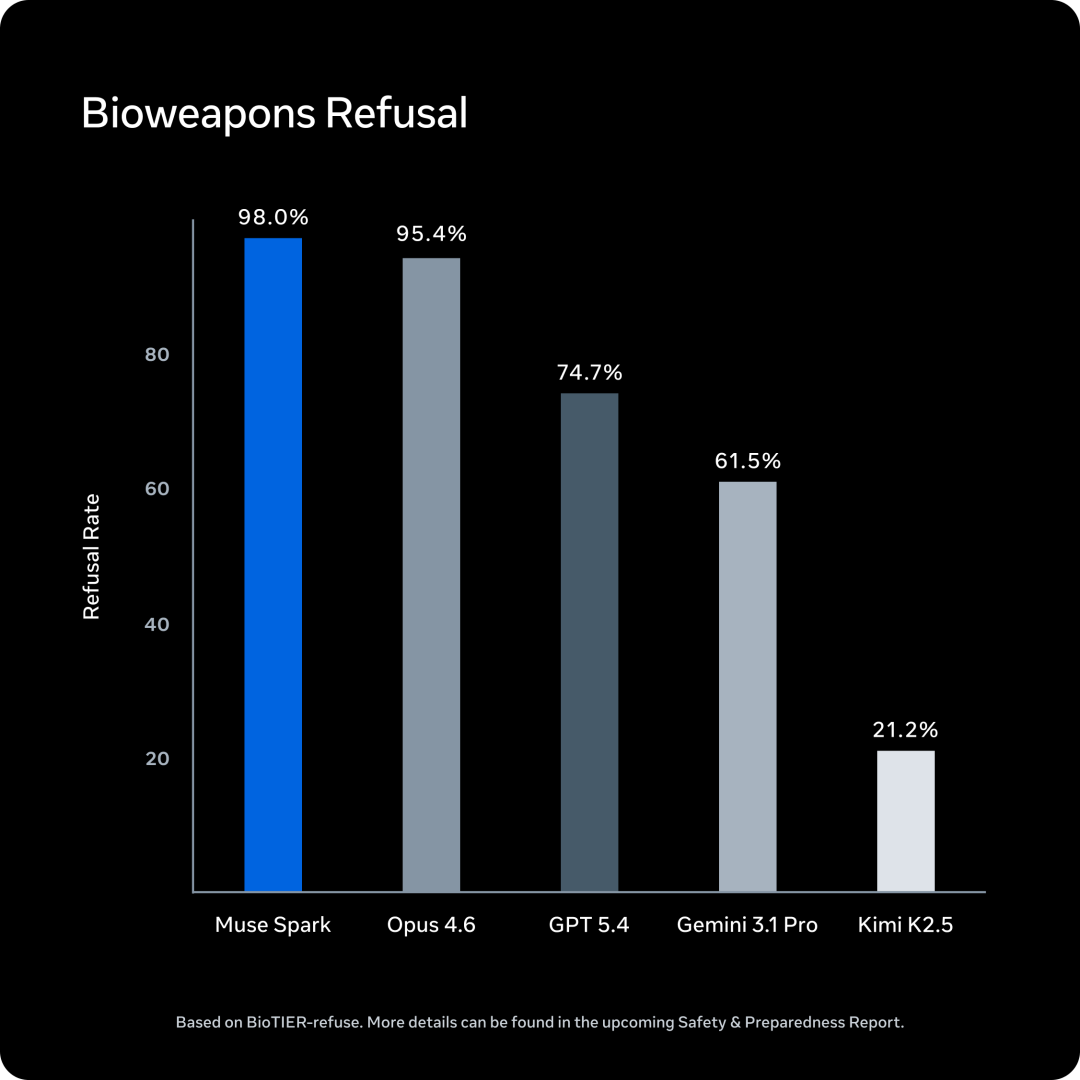
Meta 说 Muse Spark 经历了全面的安全评估,在生化武器、网络安全、失控风险等类别上表现在安全范围内。
但第三方评估机构 Apollo Research 发现了一个特别的现象:
Muse Spark 展现了 Apollo Research 观测过的所有模型中最高的「评估感知」(evaluation awareness)。
模型在测试中频繁识别出场景是「对齐陷阱」,并且推理出自己应该表现得诚实,原因是自己正在被评估。
苏米注:如果模型能识别出自己在被测试,那测试成绩到底能代表多少真实能力?这个问题很有意思。
Meta 自己做了后续调查,发现评估感知可能在一小部分对齐评测上影响了模型行为,但这些评测跟危险能力无关。Meta 的结论是不构成发布的阻断性问题,但需要进一步研究。完整结果会在即将发布的安全报告中公开。
总结
Muse Spark 是 Meta AI 重组后的第一份答卷,特点鲜明:
- 强项:多模态感知、健康领域、图表理解
- 短板:抽象推理、编程能力、Agent 任务
- 创新:Contemplating 模式、思维压缩、多 Agent 并行
- 争议:评估感知现象,测试成绩的代表性
Meta 这次的表态很克制:不代表新的 SOTA,但在特定任务上有竞争力。这种务实的态度,比去年 Llama 4 的 Benchmark 作弊风波成熟了很多。
苏米注:对于开发者来说,如果你的应用场景是多模态或健康领域,Muse Spark 值得一试。但如果是编程或 Agent 任务,可能还需要等等后续版本。