作为一名经常体验各类 AI 产品的产品经理,我发现许多开发者在集成翻译功能时,往往面临三个核心困境:对商用翻译 API 的成本担忧、数据隐私合规的压力,以及对翻译质量的不确定性。
最近在 Hugging Face 上接触到腾讯发布的混元翻译模型 HY-MT1.5,它提供了一个值得关注的替代方案——通过本地部署实现多语言、高质量的实时翻译能力。
项目概览
HY-MT1.5 是腾讯混元系列的翻译模型,包含两个规格版本:
- HY-MT1.5-1.8B:轻量化模型,支持端侧部署和实时翻译场景
- HY-MT1.5-7B:参数更大的版本,翻译效果更优
两个版本均支持 33 种语言,包括中文、英语、法语、德语、日语等主流语言,以及多个方言和地域语言。
核心功能特性
相比通用翻译模型,HY-MT1.5 在以下三个方面提供了专门的技术支持:
1. 术语干预
通过 Prompt 机制,允许用户在翻译时指定专业术语的固定译法。这对于文档翻译、技术手册等对术语准确性要求高的场景特别有用。实现方式是在系统提示中预设术语对照表:
{source_term} 翻译成 {target_term}
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:{source_text}
2. 上下文翻译
机器翻译常见的质量问题是缺乏语境导致的歧义。HY-MT1.5 支持传入前置上下文信息,使得模型能够根据文本背景进行更准确的翻译决策。这对于长文档翻译或对话翻译尤为重要。
3. 带格式翻译
在处理结构化文本(如 XML、HTML 或 Markdown 文档)时,保留原文格式标签是必需的。HY-MT1.5 提供了标签保留能力,翻译时可自动识别并保留指定标签位置。
性能表现
根据官方数据,HY-MT1.5-1.8B 在同尺度模型中达到业界最优水平,在多语言对翻译基准测试中的表现超过大部分商用翻译 API。轻量化的参数设计使其可通过量化部署在消费级硬件上,支持实时翻译场景的低延迟要求。
部署方案
根据使用场景和技术栈,项目提供了多种部署路径:
方案一:LM Studio(推荐 macOS 用户快速体验)
下载 HY-MT1.5-1.8B 模型
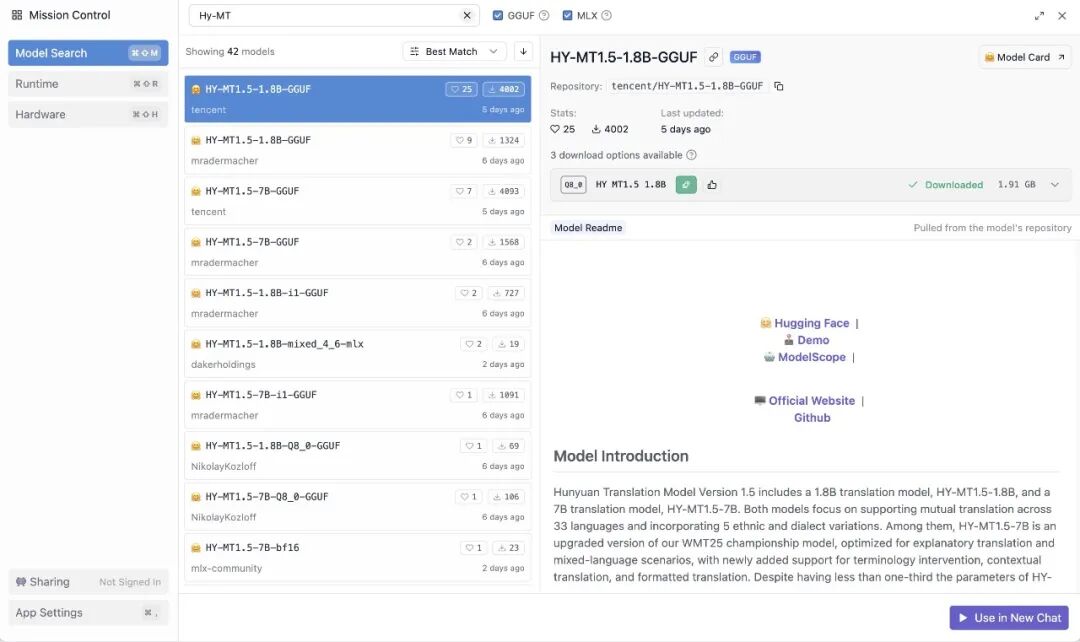
在 LM Studio 中加载模型
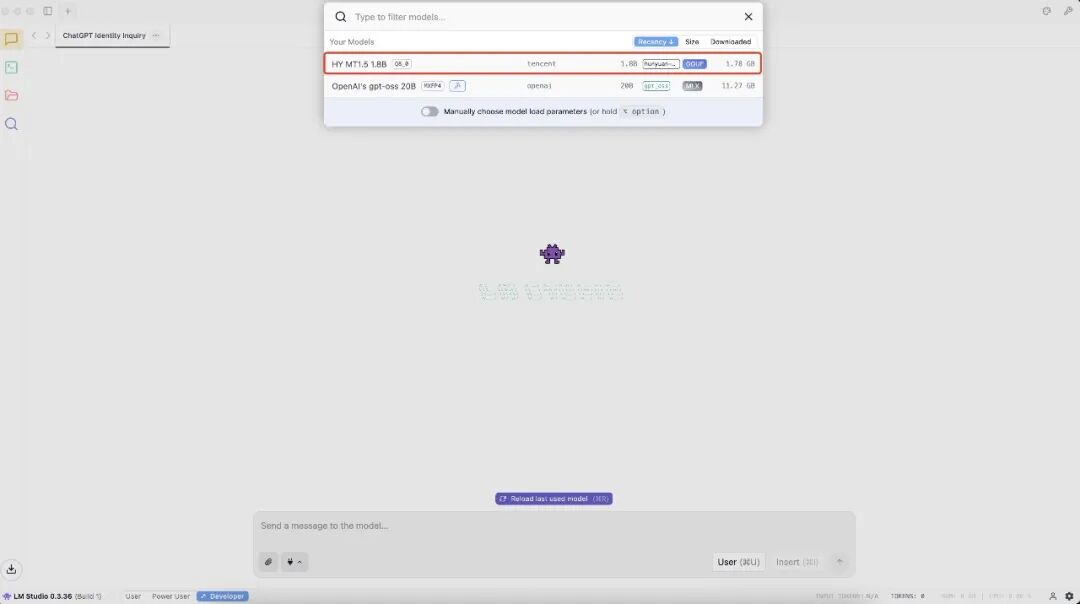
在聊天界面设置系统提示词(Prompt),示例如下:
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:{source_text}
将 {target_language} 和 {source_text} 替换为实际内容后发送即可
LM Studio 内置 llama.cpp 引擎,无需额外配置即可运行 GGUF 格式的模型。
方案二:llama.cpp(跨平台命令行部署)
适合需要集成到服务器或自动化流程的用户:
从 https://huggingface.co/tencent/HY-MT1.5-1.8B-GGUF 下载量化后的 GGUF 模型(根据硬件条件选择合适的量化版本)

从 GitHub 下载对应系统的 llama.cpp 版本
启动 llama-server 服务:
./llama-server -m [your_model_path]/HY-MT1.5-1.8B-Q8_0.gguf --port [server_port]
通过 HTTP API 调用翻译功能(兼容 OpenAI 格式的 /v1/chat/completions 接口)
方案三:Python 集成(最灵活的开发方式)
如需在现有 Python 应用中集成翻译功能:
- 安装依赖:
pip install transformers==4.56.0
- 加载模型并调用:
from transformers import AutoModelForCausalLM, AutoTokenizer model_name_or_path = "tencent/HY-MT1.5-1.8B" tokenizer = AutoTokenizer.from_pretrained(model_name_or_path) model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") messages = [ {"role": "user", "content": "Translate the following segment into Chinese, without additional explanation.\n\nIt's on the house."}, ] tokenized_chat = tokenizer.apply_chat_template( messages, tokenize=True, add_generation_prompt=False, return_tensors="pt" ) outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048) output_text = tokenizer.decode(outputs[0])
这种方式提供最高的灵活性,可直接在应用代码中控制模型行为和参数调优。
应用场景适配
基于其特性和部署方式,HY-MT1.5 特别适合以下场景:
| 应用场景 | 适配度 | 关键原因 |
| 文档翻译(技术手册、协议等) | ★★★★★ | 术语干预功能确保专业词汇准确性 |
| 实时对话翻译 | ★★★★☆ | 1.8B 轻量化模型支持低延迟响应 |
| 数据隐私敏感应用 | ★★★★★ | 本地部署完全避免数据上传第三方 |
| 成本优化场景 | ★★★★☆ | 一次部署,无持续 API 调用费用 |
| 结构化文本处理(代码、标记语言) | ★★★★☆ | 格式保留功能维持文本结构完整性 |
技术参考与对标
在开源翻译模型生态中,值得一提的相关项目包括:
- M2M-100:Meta 的多对多翻译模型,支持 100 多种语言但参数量较大(418M 起步)
- NLLB(No Language Left Behind):Meta 的后续版本,性能更优但依然轻量化不足
- Google Translate 离线版本:功能完整但模型不开源,难以定制
相比之下,HY-MT1.5-1.8B 在参数量、性能和可定制性上找到了较好的平衡点。
总结与建议
从产品角度来看,HY-MT1.5 解决了一个现实的市场痛点:当前开源翻译方案要么过于臃肿(参数量大),要么效果不理想;而商用 API 又面临成本、隐私和锁定的问题。这个项目通过量化、优化和功能设计,在轻量化和性能之间做了务实的权衡。
如果你正在构建以下类型的应用,值得抽出时间尝试:
- 涉及多语言内容处理的 SaaS 产品(文档管理、协作平台等)
- 对数据隐私有严格要求的企业应用
- 希望降低翻译成本的初创团队或小型企业
- 需要自定义翻译规则的垂直领域应用