刚刚,智谱开源了他们最强的视觉模型:GLM-4.6V
让我兴奋的是,这次一口气开源了两个尺寸:一个是106B的GLM-4.6V,另一个是9B的GLM-4.6V-Flash(消费级显卡就能本地部署)。
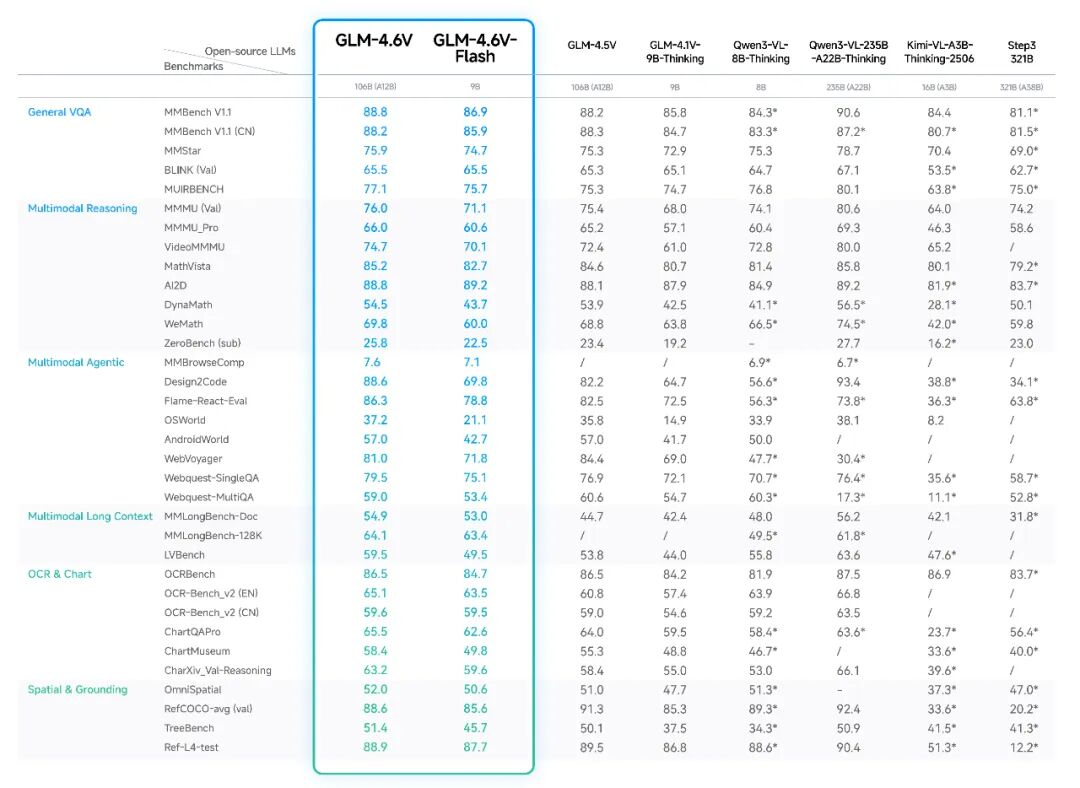
在同参数量级下,多模态交互、逻辑推理、长上下文能力都取得了SOTA(State Of The Art,目前最强)。
使用入口:可在 z.ai 使用,也支持以MCP形式接入Agent;可在Claude Code中作为“有视觉能力的基模”或作为MCP-Server提供视觉感知。

开源地址:
GitHub:https://github.com/zai-org/GLM-V
Hugging Face:https://huggingface.co/collections/zai-org/glm-46v
魔搭社区:https://modelscope.cn/collections/GLM-46V-37fabc27818446
真实场景落地尝试
1)本地跑9B:隐私与边缘部署的可行选项
我在一台带消费级显卡的办公电脑上跑了GLM-4.6V-Flash(9B)。
重点体验了几类场景:
- 群像定位:给它一张我的自拍和一张几十人的大合照,让模型在合照里标出我具体位置。这类任务之前在其他模型(包含Gemini 3)上经常失败或偏差大,这次成功率明显提升。
- 图像检索(Image Research):我写公众号需要配图,过去靠搜索常常不准。用z.ai的Image Research功能让GLM-4.6V搜“GEO(Generative Engine Optimization)”相关图片,返回结果更贴近主题,质量也更能直接用。
- 多图理解与结构化输出:把飞书多维表格API的几张截图丢给它,让模型组装成一段可直接调用的请求示例。对“有信息但分散在多张图”的情况,模型能把碎片信息整合得比较顺滑。
- 目标与属性识别:把紧贴我车头停车的红车照片给它,车辆类型、颜色等识别准确,品牌识别有偏差。整体看,常见属性较稳,品牌这类细分识别仍需场景化优化。
- 票据文本识别:把维修单据给它做OCR并结构化输出,在我逐字核对下准确率接近满分(我的样本场景下约99.9%)。
- 情绪/剧情走向分析:给“渣渣辉”的片段,让模型描述角色情绪变化与镜头细节。文本分析与细节抓取较到位,适合做素材标注或视频摘要。
这一档(9B)的意义在于:不依赖昂贵GPU,就能把“看图—理解—整理”的任务落到本地,对涉及隐私的数据尤其友好。
2)企业私有化的取舍:106B的平衡点
和动辄数百B的闭源巨型模型相比,106B在部署成本上更有可行性。我和几家制造业的朋友聊过,他们更关注“在现有机房条件下是否能上”而不是“参数规模越大越好”。
一个我在现场看到的真实案例:在流水线末端用摄像头与传感器采集纸箱图像,模型判断是否破损、封带是否完整。之前用的小模型可用,但误判较多,需要人工复核。对这类边缘场景,106B可以在企业内网里作为核心视觉服务,提升准确度的同时把数据掌握在自己手里。
3)云端与Agent:Claude Code + MCP 的组合打法
如果不介意上云,直接调智谱API,在速度和稳定性上更省心。我做了两次组合式测试:
- 复杂网页比价任务:让Claude Code做调度(工具调用、流程控制),GLM-4.6V负责视觉理解与信息抽取,通过playwright MCP跨淘宝、京东、唯品会做同款比价并加购物车。实际跑通,唯一漏的是“筛选价格区间”的步骤。
- “分工明确”的站点复刻:用GLM-4.6V分析视频中的网站结构与动效,再让GLM-4.6生成前端代码。最后效果基本还原了卡片动效与主要交互。对复杂动效的精细还原仍有难度,但这套“视觉感知 + 代码生成”的分工模式是有效的。
Claude Code集成配置(示例):
{
"env": {
"ANTHROPIC_AUTH_TOKEN": "你的智谱开放平台apikey",
"ANTHROPIC_BASE_URL": "https://open.bigmodel.cn/api/anthropic",
"API_TIMEOUT_MS": "3000000"
},
"model": "glm-4.6v"
}
如果让4.6V做视觉MCP-Server,而把代码生成换回GLM-4.6,整体分工会更清晰:
claude mcp add -s user zai-mcp-server --env Z_AI_API_KEY=你的智谱apikey -- npx -y "@z_ai/mcp-server"
选型建议
| 维度 | GLM-4.6V-Flash(9B) | GLM-4.6V(106B) | 云API(z.ai/开放平台) |
|---|---|---|---|
| 功能范围 | 多模态输入/输出、基础视觉理解、128k上下文、工具调用 | 更强的视觉理解与推理、128k上下文、工具调用 | 同能力,附带更好的服务稳定性与扩展工具 |
| 技术特征 | 适合本地量化与消费级显卡运行 | 需要高显存/多卡部署,更适合机房环境 | 免维护,随时按需扩容 |
| 使用门槛 | 低-中:有一定本地部署经验即可 | 中-高:需算力与工程化能力 | 低:直接调用API或平台 |
| 适合人群 | 个人开发者、小团队、边缘设备场景、隐私敏感任务 | 有内网与数据合规要求的企业、需要更高精度与稳定性 | 对交付速度和稳定性要求高的团队、Agent应用落地 |
| 典型使用 | 本地素材标注、票据识别、基础质检、图像检索 | 生产质检、业务系统视觉服务、私有化Agent“眼睛” | 跨平台自动化、复杂工具链、规模化服务 |
场景建议
- 本地9B:优先选择合适的量化与推理引擎,先跑通你的核心样本(比如业务常见票据与生产图片),再逐步扩展能力。
- Agent场景:用Claude Code做流程调度,GLM-4.6V做视觉与信息抽取,GLM-4.6做代码生成,是目前较稳的一种分工。
- 内容生产:结合Image Research做图像检索,和你现有的创意生图工具并行使用,用人来做最后筛选与定稿。
小结
这次GLM-4.6V的开源,把“本地可用的9B”与“企业可私有化的106B”都摆在了台面上。
我的感受是:相比一味追求模型规模,更关键的是把能力和场景对上。
流水线质检、票据识别、素材检索、Agent的“眼睛”这些具体任务,都能在可控的成本下跑起来。
另外补充一句:GLM-4.6与GLM-4.6V目前都在我的Coding Plan可用范围内。
后续我会继续把更多行业场景和模型能力对接起来,尽量用真实任务的测评数据来更新这类分享。
如果你正在做行业内的AI落地,欢迎一起交流你在本地与云端之间的选择逻辑。
最终目标不是“更强的模型”,而是“把业务问题解决掉”。