最近,微软推出的VibeVoice-1.5B模型深深吸引了我,它不仅在文本转语音(TTS)领域取得了显著突破,还打破了传统TTS技术的限制,能够生成长达90分钟、多达4个说话人的自然对话音频。对于AI语音生成的研究人员和开发者来说,这无疑是一个重大进展。
VibeVoice-1.5B是微软开源的前沿TTS框架,专注于生成长时、高表现力、多说话人的对话音频,极大提高了生成的自然度和多样性。
接下来,我将深入介绍这个项目的核心功能、应用场景以及如何部署。
核心功能与技术亮点
1. 超长时、多说话人支持
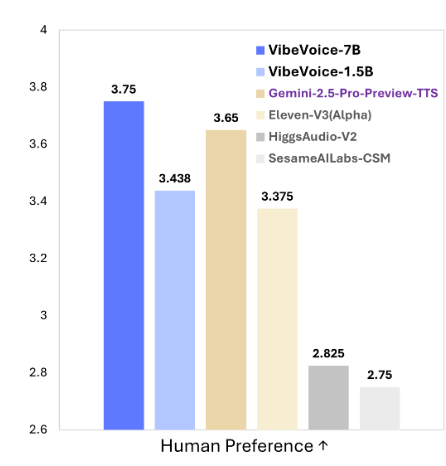
传统的TTS模型通常只能生成少量说话人的短时间对话,而VibeVoice-1.5B能够在一个会话中生成长达90分钟的音频,并支持最多4个说话人。这一功能使其特别适合用于播客、剧本创作以及其他复杂的对话场景。
2. 混合生成框架
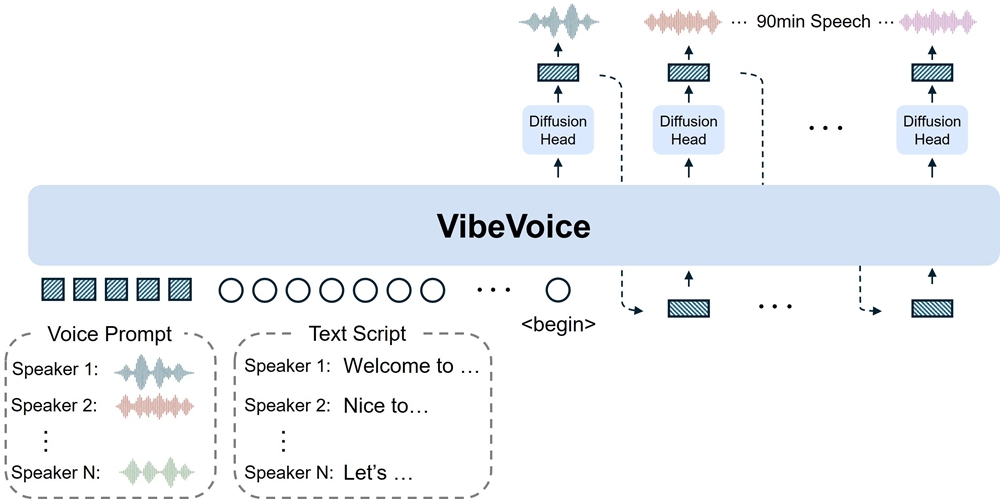
VibeVoice-1.5B结合了大型语言模型(LLM)与扩散模型(Diffusion Model),通过双Tokenizer架构(声学Tokenizer和语义Tokenizer)高效地解析文本和对话语境。LLM负责理解对话的上下文和结构,扩散模型则确保生成的音频在细节上接近人声,表现出更自然的韵律和情感。
3. 多说话人控制
该模型使用说话人嵌入向量(Speaker Embedding),能够维持长时间对话中的不同说话人音色的一致性,解决了传统TTS中无法有效处理多说话人、音色混乱的问题。
4. 跨语言与歌唱合成
虽然目前VibeVoice-1.5B的主要训练语言是英语和中文,但它具备跨语言合成的能力,甚至能够生成歌唱音频,拓展了TTS技术的应用场景。
5. 开源与可扩展性
VibeVoice-1.5B采用MIT许可开源,提供完整的文档和代码支持。由于它是一个框架而非单一引擎,研究人员可以在此基础上进行定制化开发,探索更多的应用场景。
应用场景
播客与长篇对话:VibeVoice-1.5B能够生成长达90分钟的音频,并且支持多个说话人,使其非常适用于播客创作或有多个角色的长篇对话内容。
跨语言合成与歌唱:该模型支持跨语言合成,尤其在中英文之间切换时表现优异,且具备歌唱生成能力,为多种娱乐和教育场景提供了更多可能。
语音助手与虚拟角色:通过精准的多说话人音色控制,VibeVoice能够在虚拟角色的对话生成中,保持每个角色音色的稳定性,提升用户体验。
研究与开发:作为一个开源框架,VibeVoice为AI语音合成的研究人员提供了灵活的工具,可以用于新技术的验证和优化。
安装与部署
1. 环境要求
硬件:VibeVoice-1.5B生成语音时需要7GB GPU VRAM,推荐使用8GB显存的消费级显卡(如RTX 3060)。
软件:Python 3.7+,TensorFlow 2.5+,CUDA(支持NVIDIA GPU)等。
2. 安装步骤
通过GitHub仓库下载源码:
git clone https://github.com/microsoft/VibeVoice.git
cd VibeVoice/
pip install -e .
下载预训练模型,并根据官方文档进行配置。
3. 启动与生成
配置模型后,通过命令行界面(CLI)或提供的API接口调用模型进行语音生成。
结论
VibeVoice-1.5B不仅突破了TTS领域的技术瓶颈,还将文本转语音技术带入了一个全新的时代。其高表现力、长时间生成能力、多说话人支持以及跨语言功能,为内容创作者、研究人员和开发者提供了丰富的工具和灵活的应用场景。随着微软计划推出更大规模的7B模型,VibeVoice的能力将得到进一步拓展。
对于AI语音合成技术的研究者和开发者,VibeVoice-1.5B无疑是一个值得深入探索和使用的开源工具。它的开放性和可扩展性让我们对未来的语音合成应用充满了期待。
如果你也对TTS技术和AI语音生成充满兴趣,不妨下载并尝试VibeVoice-1.5B,看看它如何帮助你推动自己的项目发展。
Github地址: